


用存储过程做报表数据准备有什么缺点?
有些报表的数据准备过程比较复杂,很难用 SQL 写出来,这时就可以使用存储过程来实现。存储过程支持多步运算,可以编写复杂的计算过程,同时库内计算可以充分利用数据库的计算能力。
不过,存储过程的缺点也十分明显。存储过程难以修改调试,也没有移植性,如果数据库扩容或更换数据库都会导致存储过程失效。创建和发布存储过程往往需要较高的数据库权限,如果将用于报表数据准备的存储过程交给数据库管理员完成,这样会增加管理员工作量提高报表开发成本,如果将权限赋给报表开发人员,又会引起因权限过高导致的数据使用和操作等安全隐患。此外,存储过程还会导致报表和数据库的耦合性过高,报表修改可能会频繁操作数据库,一个存储过程也可能被多个报表使用,导致存储过程无法删除越积越多,数据库管理混乱的同时性能也会受到很大影响。
基于存储过程的这些缺点,越来越多的企业开始禁止使用存储过程进行数据处理,包括报表数据准备。那么有没有能够继承存储过程优点又能改善其缺点的技术呢?
使用集算器 SPL 可以很好解决这个问题。集算器是一款开源数据处理引擎,擅长结构化数据计算,计算类库丰富可以满足复杂报表数据准备工作。同时,集算器天然支持多种数据源(RDB、NoSQL、Json、CSV、Webservice 等),还可以实现跨数据源的混合计算。
集算器语法 SPL 十分简洁,使用独立的 IDE 编写调试算法都非常方便。
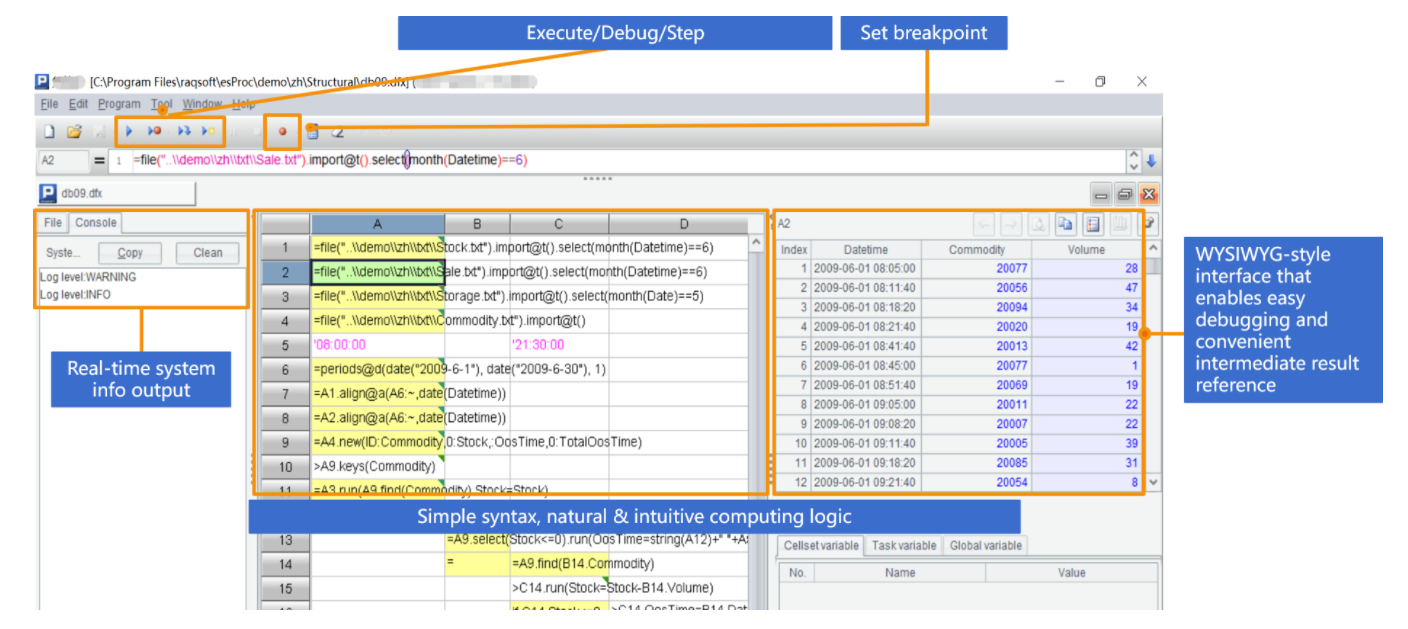
SPL 不依赖数据库,数据源修改只需要改变数据源连接,计算脚本无需修改,具备很强的移植性。不仅如此,SPL 在库外实施计算可以充分减轻数据库压力,可以使用更高效的算法从而提升报表查询性能。从存储过程的角度,可以将 SPL 看做库外存储过程。
集算器可以像存储过程一样分多步实施计算,并且集算器脚本 SPL解释执行支持热切换。比如要找出销售额占到一半的前 n 个客户(大客户)的订单情况。
A |
|
1 |
=db.query("select * from orders") |
2 |
=A1.groups(customer;sum(amount):amount).sort(amount:-1) |
3 |
=A2.sum(amount)/2 |
4 |
=0 |
5 |
=A2.pselect((A4=A4+amount,A4>=A3)) |
6 |
=A2.(customer).to(,A5) |
7 |
=A1.select(A6.pos(A1.customer)) |
通过分步的方式,先找到符合条件的大客户,再查询这些客户的详细订单信息。
集算器可以作为嵌入式 JDBC 与报表工具集成使用,报表工具通过 JDBC 方式访问 SPL 计算结果,就像访问数据库一样。
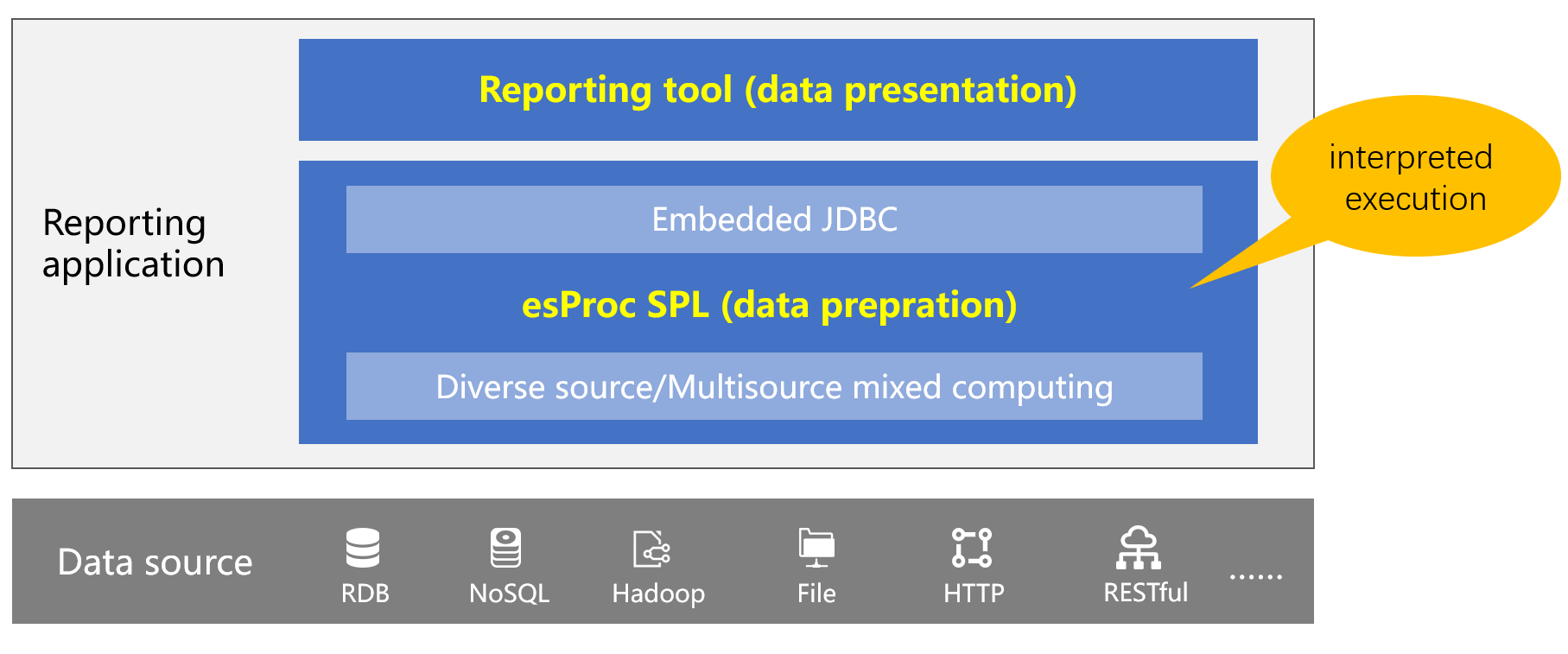
SPL 运行在数据库外与报表一同部署,报表下线可以随即删除对应用于数据准备 SPL 脚本,不会影响其他报表,这样就可以充分降低数据库(源)与报表应用的耦合性了。


英文版