


报表工具如何使用 NoSQL/Restful/ 文件等非数据库数据源?
除了数据库,报表工具本身通常也可以连接一些非关系数据库的数据源,包括 NoSQL、文件(CSV/Excel/JSON)、Hadoop、RESTful 等。但这类数据源的计算能力较弱,往往需要将数据取出在外部计算,而报表工具的计算能力也有限,这就导致报表开发困难。这时就要二次开发硬编码完成报表数据准备,十分繁琐。
使用集算器 SPL 配合报表工具,可以彻底通用地解决这个问题。集算器是专业的开源数据处理引擎,内置了很多结构化数据计算函数具备很强的计算能力。同时集算器支持多种数据源连接,包括大量的非关系数据库,可以轻松搞定搞定报表工具使用这类数据源。目前集算器支持的部分数据源如下:
TXT/CSV、Excel、Json、XML、阿里云、Cassandra、MDX、ElasticSearch、Ftp、Hbase、HDFS、Hive、Influxdb、Kafka、MongoDB、Redis、Salesforce、SAP/BW、Spark、Webcrawl、HTTP/Webservice/Restful
还在不断增加中。
集算器提供了专门的形式化语法 SPL,比如用 SPL 连接 MongoDB 并计算的脚本如下:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.new(Orders.OrderID,Orders.Client,Name,Gender,Dept).fetch() |
4 |
=mongo_close(A1) |
5 |
return A3 |
前面说过,非关系数据库和报表工具的计算能力较弱,SPL 正好还可以补上这个缺点,将数据源中无法实施的计算放到 SPL 中处理,借助 SPL 的敏捷语法、丰富的计算类库、多样性数据源支持、跨库运算、多数据源混合计算、并行计算、高性能存储等特性快速、高效完成数据运算,为报表工具返回计算结果,报表工具直接进行数据呈现即可。
集算器可以作为嵌入式 JDBC 与报表工具集成使用,报表工具通过 JDBC 方式访问 SPL 计算结果,就像访问数据库一样。
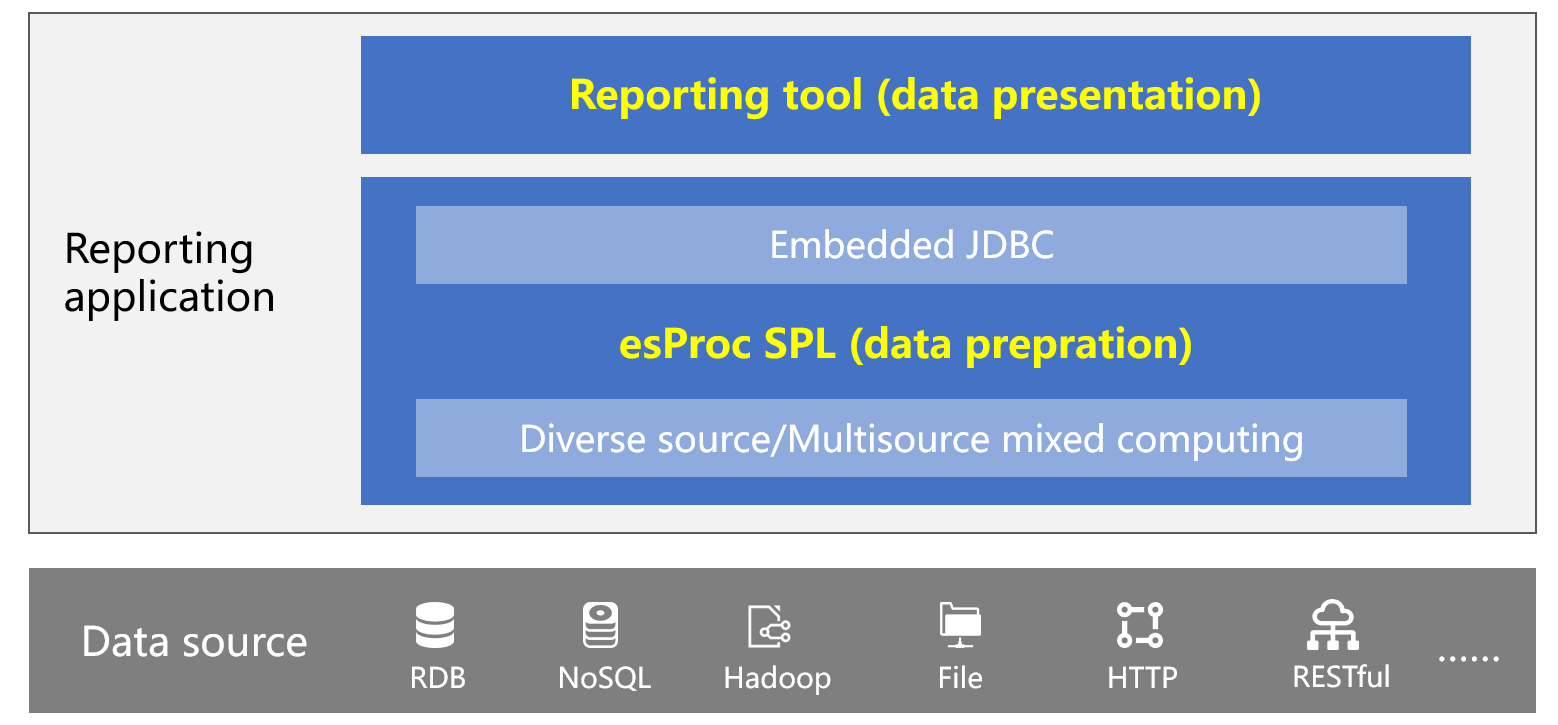
总结一下,集算器不仅提供了多种非关系数据库支持,还具备较强的计算能力可以完成复杂数据处理任务,并且敏捷的 SPL 语法实施这些计算也很简单。还能作为嵌入式计算引擎与报表工具集成使用,通过 JDBC 就可以访问 SPL 计算结果,简单方便。


英文版