


SPL:未结构化文本的读写和解析处理
文本文件可能是结构化的,也可能是无结构的,比如是一篇文章,一则日志,也可以是一份工资清单。未结构化的文本不能直接应用类似 SQL 式的运算,而要用更基础的文字处理运算。
下面我们根据文本文件的不同内容,来分类分析下不同内容时的相关计算。
1 读入
SPL 用 file 函数打开文本文件,可以读成序列或游标,然后就可以进一步计算了。当文件数据不大,能够全部装入内存时,用 read 函数将数据读成串或序列;当文件数据很大,不能全部装入内存时,用 cursor 函数将数据读成游标。
下面是一些读取方式介绍。
1.1. 整文件读入
现有一个名为 novel.txt 的文件,下述表达式将整个文件读为一个文本串:
=file(“novel.txt”).read()
file 函数用于打开指定文件,这个文件可以采用绝对路径或者相对路径,相对路径时,它是相对于集算器环境中的主目录。再使用 read 函数将文件内容读成一个大串返回。
file 函数缺省采用的是操作系统的默认字符集,如果文本需要指定字符集,则可以使用:
=file(“novel.txt”:”UTF-8”).read()
也就是在文件名后面用冒号隔开,加上指定字符集的名称。
1.2. 按行读入
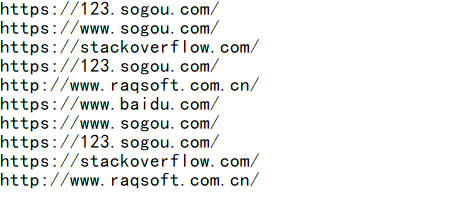
这类按行分开的内容,将每一行读成一个序列成员时,方法如下:
=file(“urls.txt”).read@n()
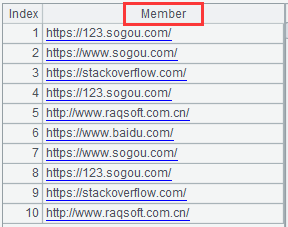
read 函数使用选项 @n 将每一行数据置入序列成员,返回值跟 1.1 节不同,返回的是序列对象。变量查看面板中的红框为 Member(成员) 则表示当前对象是一个序列,如下图:
如果每个成员是一些串描述的日期,或者数值,还可以配合选项 @v,将对应的成员解析为相应类型的数据。
如下的示例数据:

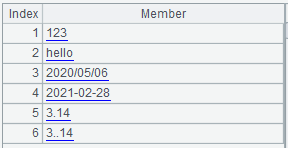
使用 =file("data.txt").read@n() 直接读取时,每一项数据缺省都是串类型:
使用带选项 @v 的表达式 =file("data.txt").read@nv() 读取后,可以看到可以解析为数据的值都变成了相应类型的数据:
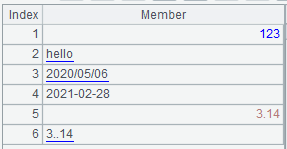
数值查看面板中,为了区分类型,字串类型会加上下划线。不过要注意的是,日期的格式需要在应用环境中设置,只有跟环境设置一致的日期写法才能正确解析,比如上图中 2020/05/06 因为跟环境格式不一致所以没法解析为日期类型。
1.3. 大文件按行读入
大文件时,使用游标函数 cursor 读入,将 1.2 节中的数据用游标读入的方法如下:
=file(“urls.txt”).cursor@s().fetch(10)
游标缺省是处理多列的序表数据,上例的每一行对应一个成员,无需拆分,则使用选项 @s 来指定不按字段拆分,直接返回包含各成员的序表。图中红框是产生序表的缺省字段名,如下图:
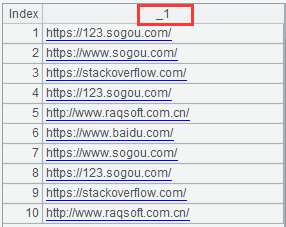
如果不想返回序表,而是想得到跟 1.2 中一样的返回序列,则需要配合选项 @i,方法如下:
=file(“urls.txt”).cursor@si().fetch(10)
再看如下的一些股票指数数据:
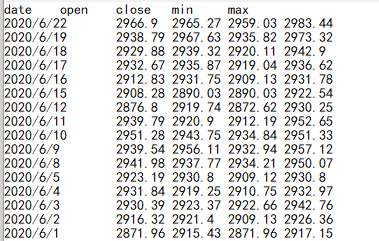
数据是用 Tab 值分开的多列数据,而 cursor 函数的默认处理方式便是返回多列的序表,所以用缺省选项的表达式:
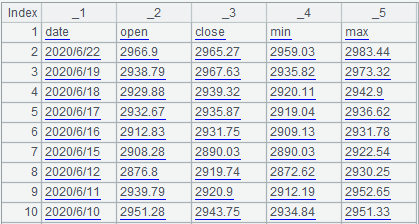
=file("d:/stock.txt").cursor().fetch(10)
读取的结果就已经是多行多列的序表:
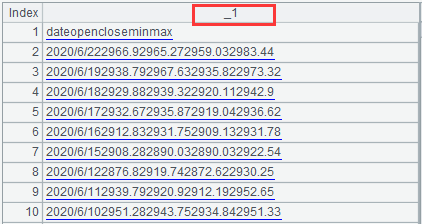
对于这种包含多列的数据,如果不想拆分为序表,则用 @s 选项:
=file("d:/stock.txt").cursor@s().fetch(10)
此时的结果为只含一列的序表,其中红圈为缺省字段名:
如果当前序表仅有一列数据,则可以用 @i 选项将结果返回成序列。当读入的序表已经是多列时,光用 @i 选项是不起作用的,没法转为序列,@i 选项通常要配合 @s 选项使用。
2 写出
将 SPL 中计算处理后的串、序列写出到文本文件时,先用 file 函数打开写出文件,然后用 write 函数将值写出。对于游标中的大数据,采用循环分批取数并写出时,要用追加写出方式。
下面是一些写出例子。
2.1. 整串写出
使用write 函数可以直接将文本串写出到文件,如下示例:
A |
B |
|
1 |
William Shakespeare (baptised 26 April 1564; died 23 April 1616) was an English poet and playwright, widely regarded as the greatest writer in the English language and the world's pre-eminent dramatist. |
一段文章 |
2 |
=file("d:/paragraph.txt").write(A1) |
将 A1 中的文章内容整段写出到 paragraph.txt |
写出文件的效果:

2.2. 按行写出
当要写出的数据是序列对象时,write 函数会将每个成员写成一行,将 2.1 示例稍微改动一下:
A |
B |
|
1 |
William Shakespeare (baptised 26 April 1564; died 23 April 1616) was an English poet and playwright, widely regarded as the greatest writer in the English language and the world's pre-eminent dramatist. |
一段文章 |
2 |
=A1.words() |
将 A1 中的文章内容拆分为单词序列 |
3 |
=file("d:/words.txt").write(A2) |
将单词序列 A2 写出到文件 words.txt |
可以看到写出函数 write 的使用跟 2.1 没有区别,此时 A2 的内容为一个包含多个串的序列,write 函数会根据要写出的对象,自动识别,如果是序列,则会将每个成员写为一行。对比下按行写出后的文件内容:
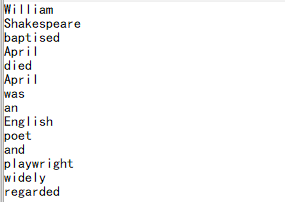
注意,按行写出时,换行符会缺省采用操作系统的换行符。如果想强制使用 windows 风格的换行符 (包含字符回车和换行,也即 \r\n),则需要使用选项 @w。
2.3. 追加写出成大文件
假设上述 urls.txt 文件很大 (没法一次性读入内存),现在要复制一下该文件,则需要使用游标读取源文件,以及使用追加写方式,此时需要用到 write 函数的 @a 选项,复制大文件的示例代码:
A |
B |
|
1 |
=file("d:/urls.txt").cursor@si() |
用游标方式读入源文件,并用 si 选项将内容返回成序列 |
2 |
for A1,1000 |
循环游标取数,每次取 1000 行,直到全部取完 |
3 |
=file("d:/urlCopy.txt").write@a(A2) |
B3 中使用 write@a 函数将每次取数结果追加写出到 urlCopy.txt。
3. 文本处理举例
文本的内容形态百千,能处理的方式也各式各样。下面列出一些最常见的文本处理方式。
3.1. 查找
查找文本内容,最常见的有 grep 命令,比如:
grep magic /usr/src 将目录 /usr/src 下所有文本文件中包含 magic 的内容查找出来。
SPL 有丰富和现成的函数可以使用。仅需两行代码便能实现类似 grep 的查找功能:
A |
B |
|
1 |
=directory@ps(path+"/*.txt") |
列出搜索目录下的所有文本文件(包含子目录) |
2 |
=A1.run(file(~).read@n().run(if(pos(~,key),output(A1.~/" 第"/#/"行: "/~)))) |
读入每个文件内容,并逐行比较关键词,输出相应信息 |
上表中用到了参数 path 和 key,这个需要先在脚本文件中定义好,执行时输入相关参数。
补充说明:
A2 run 为循环执行函数,对根目录下的所有文件遍历执行。后面还有一个 run 则是对文件内容遍历搜索。
output 的逻辑很简单,找到后,打印出行内容,行号等信息,这里要注意的是 SPL 中,整数类型的行号跟字符串拼接时,要用 /,不能用 +。
其中实现查找功能的是 pos 函数。
3.2. 替换
SPL 提供的 replace 函数可以实现对文本串的词语替换。替换后的内容需要再写出,所以分别将读入内容,替换,写出分开执行:
A |
B |
C |
|
1 |
=directory@ps(path+"/*.txt") |
列出 path 目录下的所有文本文件(包含子目录) |
|
2 |
for A1 |
=file(A2).read@n() |
循环处理目录下的所有文件 |
3 |
=B2.run(~=replace(~,source,target)) |
每个文件读入的内容执行替换动作 |
|
4 |
=file(A2).write(B3) |
再将替换后的内容写出到原文件 |
3.3. 单词计数
对单词进行计数,需要先将句子拆分为独立的单词,SPL 提供了 words 函数用于单词拆分。代码实现:
A |
B |
|
1 |
=file(“novel.txt”).read() |
读入给定文件的文本内容 |
2 |
=A1. words() |
将内容拆分为单词序列 |
3 |
=A2.groups(lower(~):Word;count(~):Count) |
将单词转为小写后,分组并计数 |
3.4. 字母计数
类似于单词计数,使用 split 函数可以将文本串直接拆分为独立的字母。代码实现:
A |
B |
|
1 |
=file(“novel.txt”).read() |
读入给定文件的文本内容 |
2 |
=A1. split() |
将内容拆分为单词序列 |
3 |
=A2.groups(~:Char;count(~):Count) |
对字符分组并计数 |
3.5. 文本去重
1.2 节中文本为一些收集重复的 url 地址列表,使用 group 函数可以很方便地去除多余的 url 地址。代码实现:
A |
B |
|
1 |
=file("d:/urls.txt")) |
打开指定文件 |
2 |
=A1.read@n() |
按行读取文件内容为序列 |
3 |
=A2.group@1() |
按序列成员分组 |
4 |
=A1.write(A3) |
获得所有行号序列 |
A3 中 group 函数提供了丰富的选项,这里使用 @1 选项去除多余的 url 串。
4. 结构化解析
有些文本内容构成稍微复杂,里面既包含可以结构化的内容,也有许多非结构化信息。此时需要去除非结构化信息,解析出结构化数据,从而对这类文件(也称为半结构化文件)也可以进行 SQL 式计算。
4.
4.1. 单行解析
如下为某软件日志文件 (QQLive.log) 的部分截图:

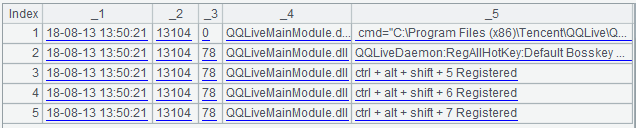
去除多余的中括号以及多余的字符后,每一行都可以解析成一条固定字段的记录。为了去除多余的字符,可以使用正则表达式和 SPL 的 regex 函数,实现代码如下:
A |
B |
|
1 |
\[(.*)\]\[(.*)\]-\[(.*)ms\]\[(.*)\](.*) |
定义正则表达式 |
2 |
=file("D:/QQLive.log").read@n() |
打开日志文件,按行将内容读成序列 |
3 |
=A2.regex(A1) |
用序列的正则分析函数 regex,拆解出字段 |
解析后的结果如下图:
4.2. 多行解析
日志文件的内容本就多种多样,比如下列数据,由于调试信息的不固定,所以要解析一条记录,需要读取不固定的行数:
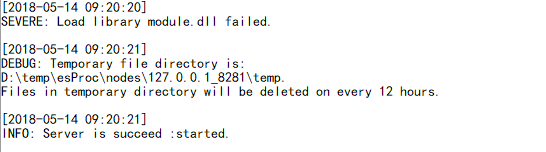
解析同一条记录,可以用左中括号来界定,这里用到 like 函数来作为分组条件,使得位于同一记录的多行可以分到相同组。代码实现如下:
A |
B |
|
1 |
=file("D:/raq.log").read@n() |
打开日志文件,按行将内容读成序列 |
2 |
=A1.select(~!="") |
过滤掉空行 |
3 |
=A2.group@i(like(~,"[*")) .(~.concat()) |
按记录内容分组,且组内成员合并为串 |
4 |
\[(.*)\] ([A-Z]+):(.*) |
定义正则表达式 |
5 |
=A3.regex(A4) |
执行正则分析 |
分组函数 group 的选项非常丰富,这里用 @i 选项可以使得同一记录的后续行都能分到当前组。
解析后的结果如下图:

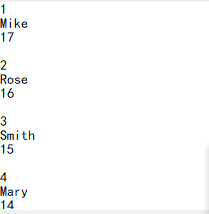
4.3. 固定行解析
下述这种固定行解析到记录的数据,可以直接使用 record 函数来填充数据。
实现代码如下:
A |
B |
|
1 |
=file("D:\\student.txt") |
打开学生文件 |
2 |
=A1.read@n() |
将数据按行读进序列 |
3 |
=A2.select(~!="") |
去掉记录间的空行 |
4 |
=create(ID,Name,Age) |
构造表结构 |
5 |
=A4.record(A3) |
将 A3 序列填充到表结构 |
解析后的结果如图:

4.4. 非固定行解析
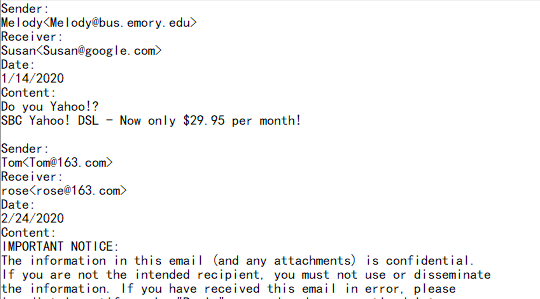
下列邮件信息,由于邮件内容的不固定,因此需要将不固定的数据行解析到一条邮件记录:
A |
B |
|
1 |
=file("D:\\mail.txt") |
打开邮件文件 |
2 |
=A1.read@n().select(~!="") |
导入序列并去掉空行 |
3 |
=A2.group@i(like(~,"Sender:*")) |
每一个 Sender: 开头以及后续行为一组 |
4 |
=A3.new(~(2):Sender,~(4):Receiver,~(6):Date,~.to(8,).concat():Content) |
摘出记录值,合并正文,创建新的结构表
|
类似于固定行解析,需要使用 group 的 @i 选项将邮件分组到一起。然后根据每一组中邮件正文起始于第 8 行,再用 to 函数将第 8 行后面的所有邮件正文设置到字段 Content。代码如下:
解析后的结果如图:

4.5. 复杂格式解析
下面为一个文本格式的客户报价单数据 item.txt,如图所示:
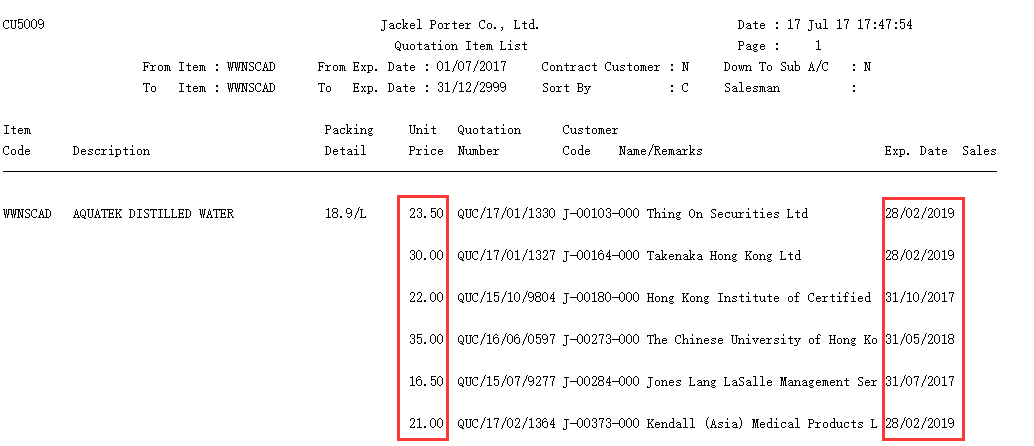
横线之前的行是复杂的表头,之后每一行是一条报价记录,记录之间有空行。图中所示只是一个表头和报价记录区,这样的区域在文本文件中会不断地重复出现。红框所示分别是 Unit Price 和 Exp. Date 字段列,中间还有 Quotation Number、Customer Code、Customer Name 字段列,各列数据之间都是空格。
观察并发现文本中的规律,我们发现这个文本的规律为:
(1)、少于 136 个字符的行都没有有效信息,可以跳过
(2)、所需数据位于每行 59 列至 136 列
(3)、把每行有效信息部分按空格为分隔符拆分,若第 1 个拆分值是数值类型,则此行是报价记录,否则可跳过。第 1 个拆分值是 Unit Price 列,第 2 个是 Quotation Number 列,第 3 个是 Customer Code 列,最后 1 个是 Contract Expiry Date 列,第 4 个至倒数第 2 个用空格连接起来是 Customer Name 列。
理清规律后,用 SPL 实现的代码如下:
A |
B |
C |
|
1 |
=create(Customer_Code,Customer_Name,Quotation_No,Unit_Price,Contract_Expiry_Date) |
||
2 |
=file("D:/item.txt").read@n() |
||
3 |
for A2 |
if len(A3)<136 |
next |
4 |
=right(left(A3,136),-58) |
=B4.split@tp() |
|
5 |
if !ifnumber(C4(1)) |
next |
|
6 |
=C4.m(4:C4.len()-1).concat(" ") |
||
7 |
>A1.insert(0,C4(3),B6,C4(2),C4(1),C4(C4.len())) |
||
8 |
=file("D:/ item.xlsx").xlsexport@t(A1) |
代码注解:
A1 创建目标数据集
A2 打开报价单文本文件 item.txt,读入文件内容,选项 @n 表示每一行读成一个字符串
A3 循环处理每一行文本,实施前面找出来的规律 B3C3 如果本行长度小于 136,则跳过此行
B4 提取本行数据的第 59 至 136 列
C4 对 B4 中提取出来的数据按空白符进行拆分,选项 t 表示拆分后去除两端的空白,选项 p 表示把拆分后的串解析成对应的数据类型
B5C5 如果 C4 拆分出的第一个值不是数值类型,则跳过此行
B6 将 C4 拆分出来的第 4 个值到倒数第二个值用空格连接成串
B7 将 C4 拆分出的第 3 个值、B6、C4 拆分出的第 2 个值、第 1 个值、最后一个值按顺序插入到 A1 的新记录中
A8 将所有提取的数据保存到 Excel 文件 item.xlsx

