


SPL:读写 xml 数据
xml是一种常用的数据格式,它具有多层节点,并且每层节点上又可以定义多对属性值,比数据库的二维表结构复杂,直接对着xml数据做计算,还是有难度。SPL语言提供了xml()函数解析/生成xml,对xml数据整理、计算提供了便利。
解析xml
基本数据类型
xml里没有显式地定义数据类型,无论是标签值,还是属性值,都认为是字符串就可以。如下person.xml,root为根节点,其下person节点代表一个人,person下每个节点记录一个用户的信息:
<?xml version="1.0" encoding="UTF-8"?>
<root>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
<birthday2>12/03/1992</birthday2>
<age>"29"</age>
<grade>8</grade>
<isForeigner>true</isForeigner>
</person>
</root>
用SPL读出:
A |
|
1 |
D:/dataFiles/xml/person.xml |
2 |
=file(A1).read() |
3 |
=xml(A2) |
A2从文件中读入整个xml串:
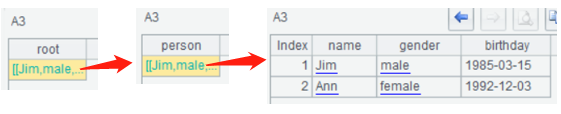
SPL的基础数据类型有字符串、数值、布尔值(true/false)、null、日期时间,解析xml的时候,会自动匹配正确的数据类型,匹配不了的就仍然是字符串类型。A3用SPL的xml()函数解析xml,依次展开,第三层解析成了一条记录,能看到name、gender识别成了字符串;birthday因为符合默认的日期格式(yyyy-MM-dd),识别成了日期类型;birthday2没识别成日期,就还是字符串类型;age虽然是数值,但因为用双引号括起来了,强制识别成字符串类型;grade识别成了数值;isForeigner识别成了布尔值。

同结构的多行数据
root节点下有多个同结构的person时,就类似一个多行的人员表了:
<root>
<person>
<name>Jim</name>
<gender>male</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
</person>
……
</root>
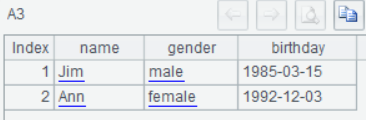
用SPL的xml()函数解析,能看到第三层是多行的二维表了:
解析XML中的指定路径
A |
|
3 |
=xml(A2,"root/person") |
xml()函数的第二个参数指定解析路径为root/person,这时就直接解析到第三层序表了:
不同结构的同种节点
<root>
<person>
<name>Jim</name>
<gender>male</gender>
</person>
<person>
<name>Ann</name>
<birthday>1992-12-03</birthday>
</person>
</root>
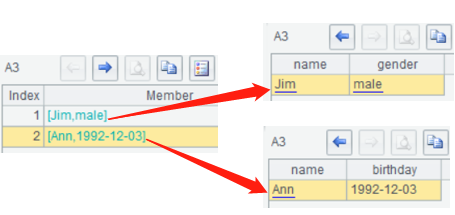
第一个person节点没有birthday,第二个节点没有gender,结构不同,这时虽然每个person仍然会解析成一条记录,但已经不能形成序表了,而是多条异构记录形成的序列
同一层有多种节点
<root>
<person>
<name>Jim</name>
<gender>male</gender>
<birthday>1985-03-15</birthday>
</person>
<team>
<name>team1</name>
<persons>Jim,Ann</persons>
</team>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
</person>
<team>
<name>team2</name>
<persons>Ann</persons>
</team>
</root>
第二层除了人员信息,还有多个team的信息,这时第二层会按照节点种类划归到不同序表,注意上面person、team两种节点是乱序混编的,这也不影响两个序表生成:
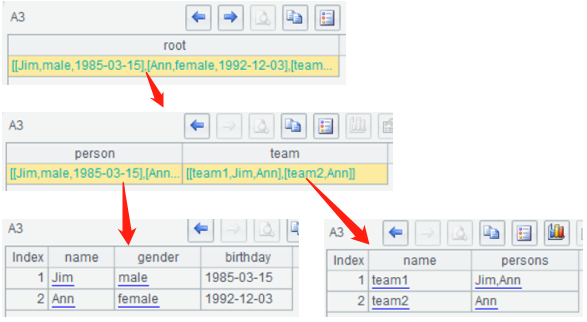
属性信息
上面看到的xml中没有属性,即便有,上面的SPL代码解析xml时也会忽略属性信息。现在继续看一下SPL如何解析xml标签上的属性信息,把person.xml改成如下属性的方式:
<root >
<person name="Jim" gender="male" birthday="1985-03-15"></person>
<person name="Ann" gender="female" birthday="1992-12-03"></person>
</root>
A |
|
1 |
D:/dataFiles/xml/person.xml |
2 |
=file(A1).read() |
3 |
=xml@s(A2) |
xml()函数用@s选项切换解析方式,这种解析方式,每一个xml标签是一条记录,数据结构是标签名和它里面的属性名:

解析成序表后,看到person字段的值是null,这是因为标签的值是空的,把person的ID做为标签值再试一下:
<root >
<person name="Jim" gender="male" birthday="1985-03-15">10001</person>
<person name="Ann" gender="female" birthday="1992-12-03">10002</person>
</root>
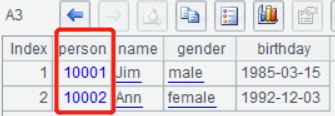
标签的值可以为空,也可以是上面10001这样的基本类型数据,还可以嵌套标签,字段值也就是嵌套的序表了:
<root>
<person name="Jim" gender="male" birthday="1985-03-15">
<buy num="5" price="$3.2">milk</buy>
<buy num="2" price="$1.8">apple</buy>
</person>
<person name="Ann" gender="female" birthday="1992-12-03">
<buy num="10" price="$1.5">egg</buy>
</person>
</root>
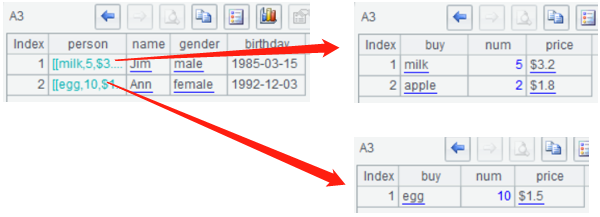
生成XML
解析的反向操作是把SPL对象生成xml,SPL中仍然用xml()函数实现它,判断传入参数的类型,会自动的选择正确的转换动作(传入xml字符串时,转换成SPL对象;传入SPL对象时,转换成xml字符串)。对于以上解析的xml,解析后不做任何修改,直接再生成回xml,观察这些正反操作中会有什么变化。
基本数据类型
原始xml:
<root>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
<birthday2>12/03/1992</birthday2>
<age>"29"</age>
<grade>8</grade>
<isForeigner>true</isForeigner>
</person>
</root>
A3中xml()把A2的xml串转换成SPL对象,A4把A3的SPL对象生成回xml串:
A |
|
1 |
D:/dataFiles/xml/person.xml |
2 |
=file(A1).read() |
3 |
=xml(A2) |
4 |
=xml(A3) |
A4的结果xml串和原始串结构一致,所有的字符串值会用双引号标示出来:
<root>
<person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
<birthday2>"12/03/1992"</birthday2>
<age>"29"</age>
<grade>8</grade>
<isForeigner>true</isForeigner>
</person>
</root>
同结构的多行数据
原始xml:
<root>
<person>
<name>Jim</name>
<gender>male</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
</person>
</root>
解析后写出,结构仍然一致:
<root>
<person>
<name>"Jim"</name>
<gender>"male"</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
</person>
</root>
写到XML中指定路径
原始xml:
<root>
<person>
<name>Jim</name>
<gender>male</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
</person>
</root>
A |
|
1 |
D:/dataFiles/xml/person.xml |
2 |
=file(A1).read() |
3 |
=xml(A2) |
4 |
=xml(A3,"persons") |
写出xml时,xml()函数的第二个参数指定写出时的根路径:
<persons>
<root>
<person>
<name>"Jim"</name>
<gender>"male"</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
</person>
</root>
</persons>
再注意,persons下还有root节点,如果想去掉它,使persons下直接是person节点,那写出的SPL对象,换成A3的root字段值就行:
A |
|
4 |
=xml(A3.root,"persons") |
<persons>
<person>
<name>"Jim"</name>
<gender>"male"</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
</person>
</persons>
不同结构的同种节点
原始xml:
<root>
<person>
<name>Jim</name>
<gender>male</gender>
</person>
<person>
<name>Ann</name>
<birthday>1992-12-03</birthday>
</person>
</root>
这种解析出来不是标准的序表,生成xml时会失败。
同一层有多种节点
原始xml:
<root>
<person>
<name>Jim</name>
<gender>male</gender>
<birthday>1985-03-15</birthday>
</person>
<team>
<name>team1</name>
<persons>Jim,Ann</persons>
</team>
<person>
<name>Ann</name>
<gender>female</gender>
<birthday>1992-12-03</birthday>
</person>
<team>
<name>team2</name>
<persons>Ann</persons>
</team>
</root>
解析后写出,结构也基本一致。因为解析时把同一种类的节点划归到了一个序表内,会按照种类排好顺序地写出,不再是乱序的:
<root>
<person>
<name>"Jim"</name>
<gender>"male"</gender>
<birthday>1985-03-15</birthday>
</person>
<person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
</person>
<team>
<name>"team1"</name>
<persons>"Jim,Ann"</persons>
</team>
<team>
<name>"team2"</name>
<persons>"Ann"</persons>
</team>
</root>
属性信息
原始xml:
<root >
<person name="Jim" gender="male" birthday="1985-03-15">10001</person>
<person name="Ann" gender="female" birthday="1992-12-03">10002</person>
</root>
这种属性格式的信息解析后,再回写成xml,变化就比较大,这对比出了两种解析模式的迥异:
<xml>
<row>
<root>
<person>10001</person>
<name>"Jim"</name>
<gender>"male"</gender>
<birthday>1985-03-15</birthday>
</root>
<root>
<person>10002</person>
<name>"Ann"</name>
<gender>"female"</gender>
<birthday>1992-12-03</birthday>
</root>
</row>
</xml>


英文版