


SPL:读写数据库
业务系统的数据绝大多数存储在关系数据库(RDB)中,SPL能便捷地读写数据库中的数据。下面以Mysql中MyCompany库的一个employees表为例解释SPL的相关用法。
读取RDB数据
用SQL读取
用SQL读取最早入职的100个员工,在集算器中执行它的SPL脚本如下:
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.query("select * from employees order by hire_date asc limit 100") |
3 |
>A1.close() |
A1:连接数据库MyCompany;
A2:在 A1 的连接中用 query 函数执行查询 SQL,执行后,选中 A2, 能观察到查询结果;
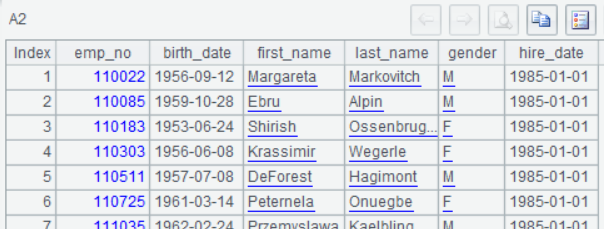
A3:关闭 A1 的数据库连接,打开和关闭数据库连接必须成对出现,否则会一直无意义的耗用着数据库连接资源。
只返回第一条结果
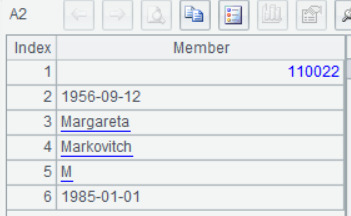
query函数用@1选项时,只返回第一条结果,如果这条记录有多个字段,返回的是序列:
A |
|
2 |
=A1.query@1("select * from employees order by hire_date asc") |
结果:
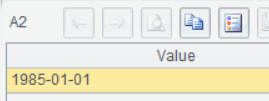
如果这条记录只有一个字段,就直接返回字段值了:
A |
|
2 |
=A1.query@1("select hire_date from employees order by hire_date asc") |
结果:
改变数值字段精度
query函数返回的数字字段值,默认是decimal类型,如果对精度要求不高,又想提升性能,可以用@d选项改成double类型,如下面查询的薪水字段:
A |
|
2 |
=A1.query@d("select salary from salaries limit 100") |
查询后自动关闭数据库连接
临时连接数据库做一个查询时,可以用一句代码实现连接、查询、关闭连接。@x选项表示查询完自动关闭数据库连接:
A |
|
1 |
=connect("MyCompany").query@x("select max(emp_id) from employees") |
通过参数查询
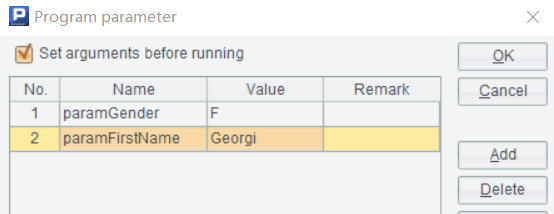
业务系统中的后端JAVA执行数据库查询时,往往是定义SQL模板,参数值是传进来的,SPL脚本也类似,同样可以接收参数值。
A |
|
2 |
=A1.query("select * from employees where gender=? and first_name=? limit 10",paramGender, paramFirstName) |
query函数第一个参数是SQL,需要传入参数值的地方用问号代替,按照问号出现的次序,从第二个参数开始依次传入动态参数值(可以是预定义参数或其它格子定义的一些SPL变量)。
参数也可以是日期类型date(1990,1,1),或日期格式的字符串"1990-12-31",查找1990年入职的员工数:
A |
|
2 |
=A1.query("select count(*) from employees where hire_date>=? and hire_date<=?" , date(1990,1,1) , "1990-12-31") |
IN中的集合参数
SQL中的IN操作会涉及多个值,涉及几个就写几个问号,后面依次跟上多个值,如下涉及三个值:
A |
|
2 |
=[500000,500001,500002] |
3 |
=A1.query("select * from employees where emp_id in (?,?,?)",A2(1),A2(2),A2(3)) |
也可以用如下更简洁的写法,只用一个问号,然后把参数值的序列整体当成一个参数:
A |
|
2 |
=[500000,500001,500002] |
3 |
=A1.query("select * from employees where emp_id in (?)",A2) |
用游标方式读取大量数据
salaries表中几百万条数据,全部加载可能导致内存溢出,这时可以用cursor函数,它的用法和query函数差不多,只是不会立即加载数据,可以通过多次fetch(n),一部分一部分的取出数据做处理。如下面每次取出100行,累加薪水,同时计数,直到取完所有数据,结束循环,最终A6再求出平均薪水:
A |
B |
C |
D |
|
1 |
=connect("MyCompany") |
|||
2 |
=A1.cursor("select * from salaries") |
|||
3 |
>all=0,count=0 |
|||
4 |
For |
=A2.fetch(100) |
if (B4==null) |
break |
5 |
>all+=B4.sum(salary) |
>count+=B4.count() |
||
6 |
=all/count |
|||
7 |
>A1.close() |
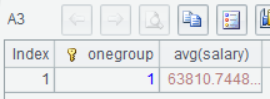
上面这种使用游标的方式,是为了看清楚使用游标做计算的过程,实际使用的时候可以直接使用针对游标的计算函数,改写上面代码,用groups,avg等函数就能得到平均薪水,这些函数内部,同样使用边加载边计算的策略,原始数据很大,但占用内存很少:
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.cursor("select * from salaries") |
3 |
=A2.groups(1:onegroup;avg(salary)) |
4 |
>A1.close() |
回写RDB数据
SPL中用execute函数执行数据库的写操作(SQL中的INSERT/UPDATE/DELETE),用法和query函数基本一致。
执行SQL更新数据
execute(sql, paramValue1, paramValue2, paramValue3,……),sql语句之后是按照顺序传入的参数,如下插入新数据:
A |
|
2 |
=A1.execute("insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",10007,"1957-05-23","Tzvetan","Zielinski","F","1989-02-10") |
SQL语句中参数如果是像上面这样连续的,可以简化成一个问号,同时后面的参数也合入一个序列即可:
A |
|
2 |
=A1.execute("insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?)",[10007,"1957-05-23","Tzvetan","Zielinski","F","1989-02-10"]) |
更新数据:
A |
|
2 |
=A1.execute("update employees set gender=? where emp_no=?","M",10007) |
删除数据:
A |
|
2 |
=A1.execute("delete from employees where emp_no=?",10007) |
批量执行SQL更新数据
emps.txt中存储了一些待插入employees表的数据:
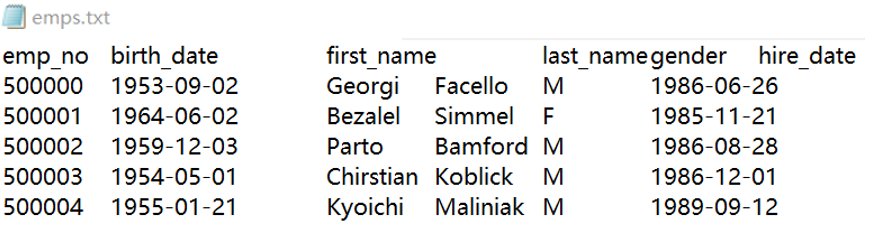
要把这些数据写入数据库,可以用for循环一条一条插入。也可以用execute函数的批量更新动作。看下面的代码,A2把emps.txt的数据加载成内存中的SPL序表;A3中execute函数针对A2做整体更新,参数中的#1,#2,#3…分别代表A2序表的第1、2、3…个字段,直接用A2序表中的字段名也可以(A4中的写法)。
A |
|
1 |
=connect("MyCompany") |
2 |
=file("d:/emps.txt").import@t() |
3 |
=A1.execute(A2,"insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",#1,#2,#3,#4,#5,#6) |
4 |
/=A1.execute(A2,"insert into employees (emp_no,birth_date,first_name,last_name,gender,hire_date) values (?,?,?,?,?,?)",emp_no,birth_date,first_name,last_name,gender,hire_date) |
5 |
>A1.close() |
表格式更新数据
上面的批量写入,只能做同一种动作(批量插入、或批量更新、或批量删除)。设想这样一种场景,读出一些记录到表格编辑,可能会新增、删除、修改,编辑完成把表格数据回写到数据库,这公涉及比较复杂的过程,要和原有数据做比对,根据情况分别生成 INSERT,DELETE和UPDATE语句,还可能遇到自增主键的状况。针对这种需求,SPL提供了update函数,封装了这些操作,用一条语句实现表格式批量写入。
从数据库读出要修改的数据,存入emp_old.xlsx:
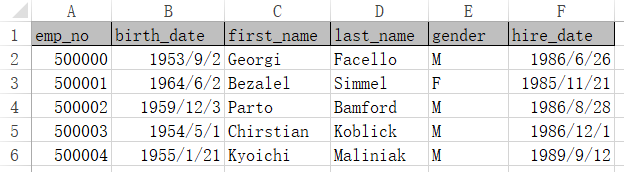
修改后另存成如下emps.xlsx,红色的前三行的数据做了修改;删除了emp_no=500003、500004的两行;最后绿色的两行是新增的。
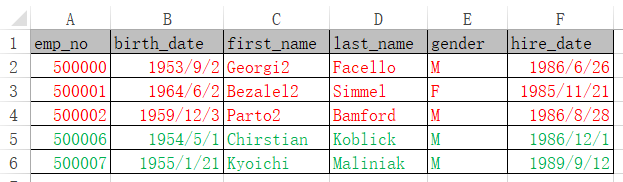
A4中update函数,通过新(A3)、旧(A2)数据的对比,更新数据库中的表employees,更新的字段是emp_no,birth_date,first_name,last_name,gender,hire_date,最后的分号后指定主键字段emp_no,新旧数据是通过对比这个主键字段,才知道哪些数据要新增、哪些要修改、哪些要删除。
A |
|
1 |
=connect("MyCompany") |
2 |
=file("d:/emps_old.xlsx").xlsimport@tx() |
3 |
=file("d:/emps.xlsx").xlsimport@tx() |
4 |
=A1.update(A3:A2,employees,emp_no,birth_date,first_name,last_name,gender,hire_date;emp_no) |
5 |
>A1.close() |
update函数能同时增删改数据,也能用选项指定只执行某一种操作,只做新增用@i,只修改用@u,只删除用@d:
A |
|
=A1.update@i(...) /仅新增 |
|
=A1.update@u(...) /仅修改 |
|
=A1.update@d(...) /仅删除 |
除了上面这三个控制更新方式的选项,还有一个@a选项,表示清空目标表,然后全部重新插入新数据。
A |
|
=A1.update@a(...) /清空数据库表,重新插入全部数据。 |
有的数据库表中的主键是自增字段,用@1选项指明这种情况,表示第一个字段是自增的主键字段,这时update函数中的不用再指名主键字段(emp_no),修改后的序表A3中emp_no无论是null、或空字符串、或不在旧序表A2范围内的行都是要新增的行,新增的emp_no值是数据库自增产生的。
A |
|
4 |
=A1.update@1(A3:A2,employees,birth_date,first_name,last_name,gender,hire_date) |
用update函数更新数据确实方便,但因为它内部动作复杂,比execute简单任务要慢。使用时要根据具体情况选用。
事务控制
update和execute函数一样,都支持@k选项,表示不自动提交事务,等一系列写操作完成后,可以观察这一系列操作中是否发生了错误,依据错误性质,再决定是否提交db.commit()、或执行回滚db.rollback(),撤销全部的更新。
连接上数据库,执行多个写操作时,中间某一步发生错误时,程序会默认地中断执行,如果不想让错误中断程序,A1连接数据库时用connect的@e选项即可,之后A2/A3/A4的写操作execute、update都用@k取消自动提交,避免后面操作发生错误时,前面的数据已经提交,也就不会产生“脏数据”。A5中用db.error()观察A1这个数据库连接中积累的错误,如果没有错误执行B5中的db.commit(),否则执行B6中的db.rollback(),取消所有的写操作。
A |
B |
|
1 |
=connect@e("MyCompany") |
|
2 |
=A1.execute@k("insert into …") |
|
3 |
=A1.update@k(...) |
|
4 |
=A1.execute@k("delete…") |
|
5 |
if A1.error()==0 |
>A1.commit() |
6 |
else |
>A1.rollback() |
7 |
>A1.close() |
调用存储过程
一个定义好的 proc1 存储过程,有字符串类型 param1、整数类型 param2 两个输入参数:
delimiter $
create procedure proc1 (
in param1 varchar(100)
,in param2 int
) begin
update employees set first_name=param1 where emp_no=param2;
end$
delimiter ;
在SPL中可以用之前的更新函数execute执行,传入"Kyoichi"、500001两个参数值。
A |
|
2 |
=A1.execute("{call proc1(?,?)}","Kyoichi",500001) |
执行后再查看这个雇员,发现first_name改成了Kyoichi,存储过程成功执行了。
上面这种办法只适合没有返回值的存储过程,如果有返回值,甚至多个返回值时,需要用 proc 函数执行。下面这个存储过程有两个输入参数、两个输出参数:
delimiter $
create procedure proc2 (
in param1 varchar(100)
,in param2 int
,out param3 int
,out param4 int
) begin
SELECT count(*) into param3 FROM employees WHERE first_name=param1 and emp_no>param2;
SELECT count(*) into param4 FROM employees WHERE first_name<>param1 and emp_no>param2;
end$
delimiter ;
在下面的 A2 执行这个存储过程,两个输出参数返回的结果是 r1,r2 两个变量。r1 表示迟于 emp_id=400000 的员工中,first_name 是 Kyoichi 的人数;r2 表示 first_name 不是 Kyoichi 的人数。
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.proc("{call proc2(?,?,?,?)}","Kyoichi":11:"i":,400000:11:"i":,"@r1":11:"o":r1,"@r2":11:"o":r2) |
3 |
>A1.close() |
执行后,看到网格变量中r1、r2的值已经计算出来了。
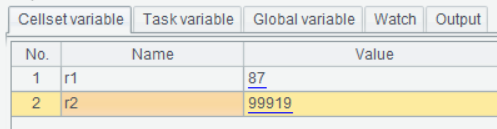
proc函数后面的参数形式稍微复杂,每个参数是用三个冒号分开的四个值,{输入的值}:{数据类型}:{参数类型}:{输出值的变量名}
输入的值:输入参数的值;是输出参数时,或是变量名(Mysql),或为空(Oracle),为空时,之后的冒号不能省略;
数据类型:参考《存储过程数据类型定义》;
参数类型:"i"是输入参数,"o"是输出参数;
输出值的变量名:存储过程的输出参数对应的SPL变量名,A3/A4通过变量名可以观察到这两个输出的表,如果是输入参数,这里为空,但之前的冒号不能省略。
上面是两个Mysql的存储过程,Oracle语法不太一样,输出参数能直接支持游标数据类型,可以较方便的返回多个多行结果集,如下,两个结果集返回的是符合条件的完整员工信息,而非员工数
create or replace procedure proc3 (
param1 in varchar2
,param2 in int
,param3 out sys_refcursor
,param4 out sys_refcursor
) as
begin
open param3 for select * from FROM employees WHERE first_name=param1 and emp_no>param2;
open param4 for select * from FROM employees WHERE first_name<>param1 and emp_no>param2;
end proc3;
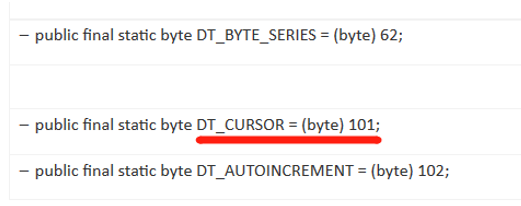
游标数据类型在SPL中的定义是101,如下A2调用执行:
A |
|
1 |
=connect("MyCompany") |
2 |
=A1.proc("{call proc3(?,?,?,?)}","Kyoichi":11:"i":,400000:11:"i":,:101:"o":r1,:101:"o":r2) |
3 |
>A1.close() |


连接池如何设置啊?
http://doc.raqsoft.com.cn/esproc/tutorial/jisuanqijdbc.html
在线文档中介绍了如何在润乾配置文件中设置连接池。