


润乾报表中的 DQL 有什么过人之处?
一直以来,BI(特指多维分析)都没有太好的办法解决关联查询的问题。由于 BI 用户无法理解表间关联,所以常见的做法是通过事先建立数据立方体将可能的关联都整理成一张表,用户基于一张表进行多维分析。但数据立方体会限制查询的灵活性(只能用建好的模型,超出范围就查不了),而 BI 自助分析注重的就是灵活性。反过来,如果想兼顾灵活性,就只能把关联操作开放给用户,这对用户来说又太难,也没法实施。
看起来,灵活和简单是 BI 应用天生不可调和的一对矛盾。
现在好了,DQL 拯救 BI 的时候到了。
DQL 是润乾报表的 BI(多维分析)引擎,全称是 Dimensional Query Language,从开发语言角度来看,是一种基于维度的查询语言,类似 SQL。其实大可不必深究这个名称,看它能干什么就行。
DQL 兼顾了 BI 关联分析的灵活和简单。DQL 采用实时关联的方式,基于用户在页面拖拽实时生成关联查询,不需要事先关联(灵活),更不需要用户来指定关联(简单)。
DQL 之所以具备 SQL 搞不定的能力,是由其理论决定的。
我们知道 SQL 对关联(JOIN)的定义很简单,两个表关联时,设置对应的关联字段就可以了,除此之外没有更多的信息和约定。定义简单,是容易理解了,但用来描述现实却会很复杂。就像只要学加法是很简单,但试图把乘法也用加法来描述却会很麻烦。
DQL 则重新看待表间关联,基于 DQL 很容易做出前端界面,从而实现实时关联查询,满足灵活性和简单性的要求。
比如,根据订单表 (orders),区域表 (area),查询订单的发货城市名称、以及所在的省份名称、地区名称。
用 DQL 表达是这样的:
SELECT
send_city.name city,
send_city.pid.name province,
send_city.pid.pid.name region
FROM
orders
使用一张(订单)表查询,城市和地区信息通过类似“对象. 属性”的方式获得,send_city.pid.name 获得的是城市信息,send_city.pid.pid.name 获得的是城市上级地区的信息,城市和地区都存储在一个地区表里。同样的查询,用 SQL 则要关联多次(地区表自关联):
SELECT
T_1_2.name city
,T_1_3.name province
,T_1_4.name region
FROM
orders T_1_1
LEFT JOIN area T_1_2 ON T_1_1.send_city=T_1_2.area_id
LEFT JOIN area T_1_3 ON T_1_2.pid=T_1_3.area_id
LEFT JOIN area T_1_4 ON T_1_3.pid=T_1_4.area_id
这种自关联的场景如果想事先建宽表难度非常大,自己和自己关联的层级可能很多,有时无法事先确定有多少层;而且每次关联都会随之附带很多字段(属性)导致宽表过宽,冗余过高,不仅可能出错(不遵循范式的结果),查询效率也低(大宽表查询会很慢)。
DQL 允许把外键表的字段当成字段的属性使用,支持无限层级,这样就很好地解决了关联问题。页面端也很好表达,按层展开即可,有多少层都没关系。
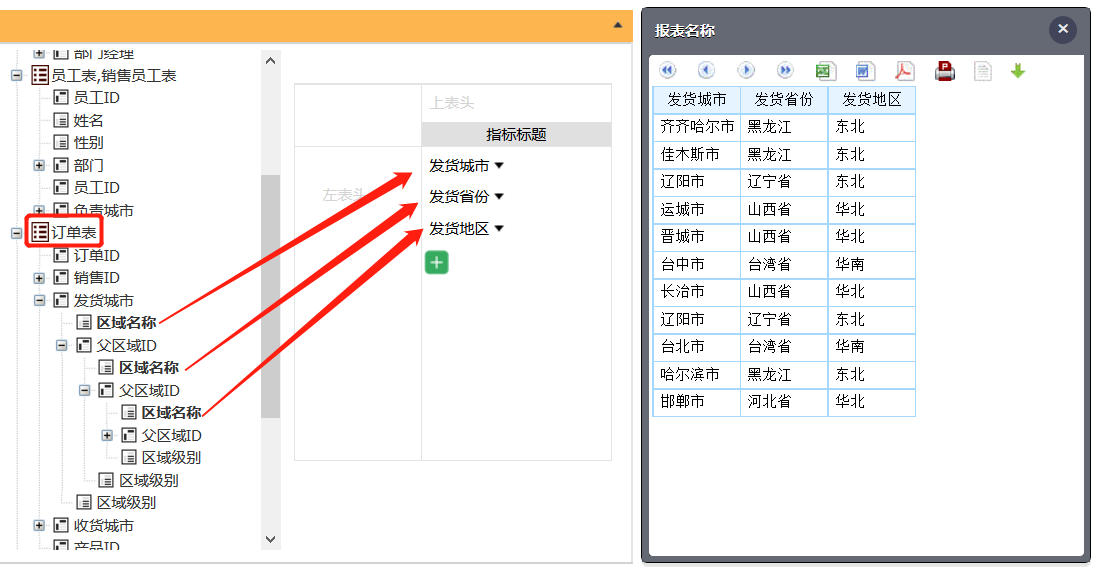
循环关联也类似,比如员工表和部门表,员工的部门指向部门表,部门的经理又指回员工表,这样查询时就可能重复使用多次(比如查询中国经理的美国员工),用 DQL 就很好表达。
除了自关联和循环关联,多级(外键)关联,重复关联(订单表有发货城市和收货城市都指向地区表),多字段关联(多字段外键)的情况。而实际业务中这些关联场景还会混合出现,这时无论是事先的宽表方案,还是将关联开放给用户都无法很好满足要求了,使用 DQL 仍然非常简单。
实现了这个效果,BI 的灵活性大大增强,用户使用也很简单,这就是 DQL 的过人之处。

