


Java 文本计算利器
用 java 处理存储在 text、csv 等文本中的数据时,经常要借助一些工具来实现。
把文本导入数据库再使用 SQL 处理是一种选择,不过这种方式过重,数据库安装、管理、导入数据过于繁琐,时效性很差。折中的方案是使用 SQLite 这样的可嵌入数据库,这样不仅可以与 java 有效结合,还能借助 SQL 进行计算。但 SQLite 的缺点也很明显,数据导入非常复杂,处理大文本(big text)有点吃力,仍然要维护数据库的问题仍然存在。
还可以使用文件 SQL 引擎,如 CSVJDBC/XLSJDBC/CDATA Excel JDBC/xlSQL,以文本为物理表,向上提供 JDBC 接口。由于直接是 java 类库,因此集成非常方便,还可以使用 SQL 查询。不过,由于只支持有限的几种基本计算(条件查询、排序、分组汇总)使得这类工具使用场景非常受限。
另外一种选择是 dataFrame 类函数库,不再依赖 SQL 能力,一般会提供类似 dataFrame 的通用数据对象,提供函数式的计算接口。此类工具数量较多,如 Tablesaw/ Joinery/ Morpheus/ Datavec/ Paleo/ Guava。这类工具与 java 可以无缝集成,一般的计算实现与 SQL 相当,但关联(JOIN)运算要复杂得多,虽然有 lambda 语法的加持,但仍然不够简单。
如果要全场景覆盖,使用专业的结构化计算语言可能是唯一选择。可选择的包括 Scala、esProc 和 linq4j。Scala 的使用还算简单,但对复杂计算的支持不够好,易学难精是 Scala 的特点,而且 Scala 不支持热部署会对经常修改的计算任务制造不少麻烦。
esProc 的能力则更出众些。esProc SPL 是专业的结构化数据查询语言,有完善的计算类库可以很方便地完成从简单到复杂的计算。不仅可以处理小文本,对大文本(big text)计算支持也非常好。举个例子:
基于学生成绩文本文件students_scores.txt,查询各班语文成绩在90分以上且总成绩排在前5名的学生。
A |
|
1 |
=file("students_scores.txt").import@tc() |
2 |
=A1.select(Chinese>=90) |
3 |
=A2.derive(English+Chinese+Math:total_score) |
4 |
=A3.groups(CLASS;top(-5;total_score)) |
如果文本很大(big text),esProc还支持并行计算,写法也非常简单,只需要将上面的第一行脚本改为:=file("students_scores.txt").cursor@tcm(;8)"即可,其中“cursor”用来创建文件游标,参数“8”代表启动8个线程并行计算。
另外,esProc SPL还支持SQL查询文件:
$select area,department,sum(amount) total fromorders.txtgroup by area,department
对熟悉SQL的程序员非常友好。
esProc用 Java 开发,提供标准 JDBC 接口,可以无缝集成嵌入 Java 应用
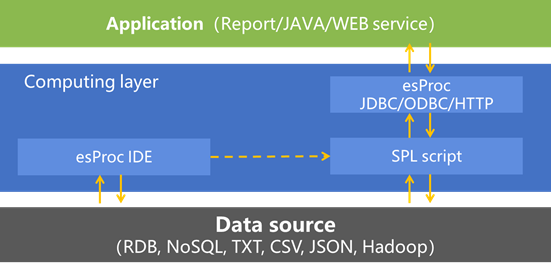
在 Java 中调用上面例子的 SPL 脚本,集成代码:
public static void callspl() {
Connection con = null;
java.sql.Statement st;
try {
Class.forName("com.esproc.jdbc.InternalDriver");
con = DriverManager.getConnection("jdbc:esproc:local://");
st = con.createStatement();
ResultSet rst = st.executeQuery("call students()"); //调用esProc SPL脚本
System.out.println(rst);
} catch (Exception e) {
System.out.println(e);
} finally {
// 关闭连接
if (con != null) {
try {
con.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
}
此外 SPL 是解释执行的,算法修改只要替换脚本就可以了,不需要重新启动应用。

