


从 Scala 到 esProc
Scala 是一门多范式(multi-paradigm)的编程语言,全称是 Scalable Language,寓意具备很强的伸缩性,设计初衷是要集成面向对象编程和函数式编程的各种特性。Scala 运行在 JVM 上,可以与 JAVA 无缝对接,很多时候可以把 Scala 看做 JAVA 的延伸。
Scala 非常擅长结构化数据计算,使用 DataFrame 数据对象可以很方便实施集合运算,可以达到 SQL 同样简单的效果,而应用场景要比 SQL 更为广泛。
比如 SQL 比较难以实施的跨库运算,使用 Scala 会很简单:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
object testJoin {
def main(args: Array\[String\]): Unit = {
//create spark session on local
val spark = SparkSession.builder()
.master("local")
.appName("example")
.getOrCreate()
//load Employees from oracle
val Employees = spark.read
.format("jdbc")
.option("url", "jdbc:oracle:thin:@127.0.0.1:1521:ORCL")
.option("query", "select EId,Name from employees")
.option("user", "scott")
.option("password", "password")
.load()
//load Orders group from MySql
val O = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql1")
.option("query", "select SellerId, sum(Amount) subtotal from Orders group by SellerId")
.option("user", "root")
.option("password", "password")
.load()
//join using dataframe
val join=O.join(Employees,O("SellerId")===Employees("EId"),"Inner")
.select("Name","subtotal")
join.show()
}
}
虽然整体代码较长,但核心用于跨库关联计算的代码却很简单。
不过,使用 Scala 实现比较复杂的计算会有些困难,Scala 易学难精,这可能也是 Scala 使用者很少的原因。
另外,Scala 在 MongoDB 支持方面表现一般,Scala 只能以 collection 为单位取数,不支持用 mongoDB 的 json 查询表达式取数,如果 colleciton 数据量较大,则取数会花费大量时间。而且,Scala 不能从多层 collection 中取数,如果想计算 MongoDB 中的多层 collection,则必须改造成多个单层 collection。
相对 Scala,使用 esProc 充当 Java 计算库更有优势。esProc SPL 是专业的结构化数据查询语言,有完善的计算类库可以很方便地完成从简单到复杂的计算。
举个例子:Duty.xlsx 记录着每日值班情况,一个人通常会持续值班几个工作日,之后再换人,现在要根据 duty 依次计算出每个人连续的值班情况。数据结构示意如下:
处理前(Duty.xlsx)
Date |
Name |
2018-03-01 |
Emily |
2018-03-02 |
Emily |
2018-03-04 |
Emily |
2018-03-04 |
Johnson |
2018-04-05 |
Ashley |
2018-03-06 |
Emily |
2018-03-07 |
Emily |
… |
… |
目标:
Name |
Begin |
End |
Emily |
2018-03-01 |
2018-03-03 |
Johnson |
2018-03-04 |
2018-03-04 |
Ashley |
2018-03-05 |
2018-03-05 |
Emily |
2018-03-06 |
2018-03-07 |
… |
… |
… |
使用 esProc SPL 实现:
A |
|
1 |
=T("D:/data/Duty.xlsx") |
2 |
=A1.group@o(name) |
3 |
=A2.new(name,~.m(1).date:begin,~.m(-1).date:end) |
SPL 的代码非常简洁,而这个例子使用 Scala 就比较难写。
在 MongoDB 支持方面,esProc 由于本身提供了多层数据结构,可以直接使用多层 collection,这样就可以避免 Scala 拆分再关联带来的编码困难和性能差的问题。
此外,esProc 支持 MongoDB 的 json 查询表达式(find、count、distinct 和 aggregate),比如区间查询写作:=mongo_shell(A2,"test1.find({Orders.Amount:{$gt:1000,$lt:3000}})")
在 collection 数据较多且 json 表达式较简单的时候,可以通过这种方式减少取到的数据,以防内存溢出;也可以加快查询速度,比如针对索引的查询。如果取到的数据依旧很多,esProc 也能轻松处理,esProc 支持游标类型,可以计算超出内存的数据。
比如过滤多层 collection(Orders)可以编写 mongo.dfx:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"test1.find()") |
3 |
=A2.conj(Orders) |
4 |
=A3.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")).fetch() |
5 |
=mongo_close(A1) |
可以看到,在 MongoDB 支持方面,esProc 更有优势。
esProc用 Java 开发,提供标准 JDBC 接口,可以无缝集成嵌入 Java 应用
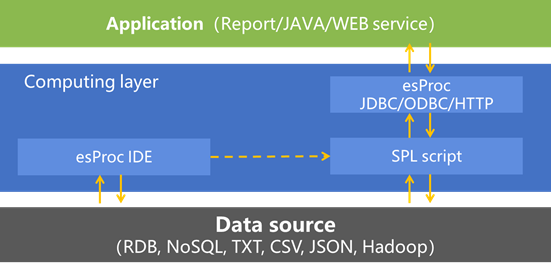
在 Java 中调用上面例子的脚本 mongo.dfx,集成代码:
public static void callspl() {
Connection con = null;
java.sql.Statement st;
try {
Class.forName("com.esproc.jdbc.InternalDriver");
con = DriverManager.getConnection("jdbc:esproc:local://");
st = con.createStatement();
ResultSet rst = st.executeQuery("call mongo()"); //调用mongo.dfx
System.out.println(rst);
} catch (Exception e) {
System.out.println(e);
} finally {
// 关闭连接
if (con != null) {
try {
con.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
}
此外 SPL 是解释执行的,算法修改只要替换脚本就可以了,不需要重新启动应用,而 Scala 作为编译型语言则不具备这个优势。

