


多维分析后台实践 8:主子表及并行计算
【摘要】
用实例、分步骤,详细讲解多维分析(OLAP)的实现。点击了解多维分析后台实践 8:主子表及并行计算
实践目标
本期目标,是在完成前几期优化的基础上,用有序归并或一体化存储来实现主子表及其并行多维分析计算。
实践的步骤:
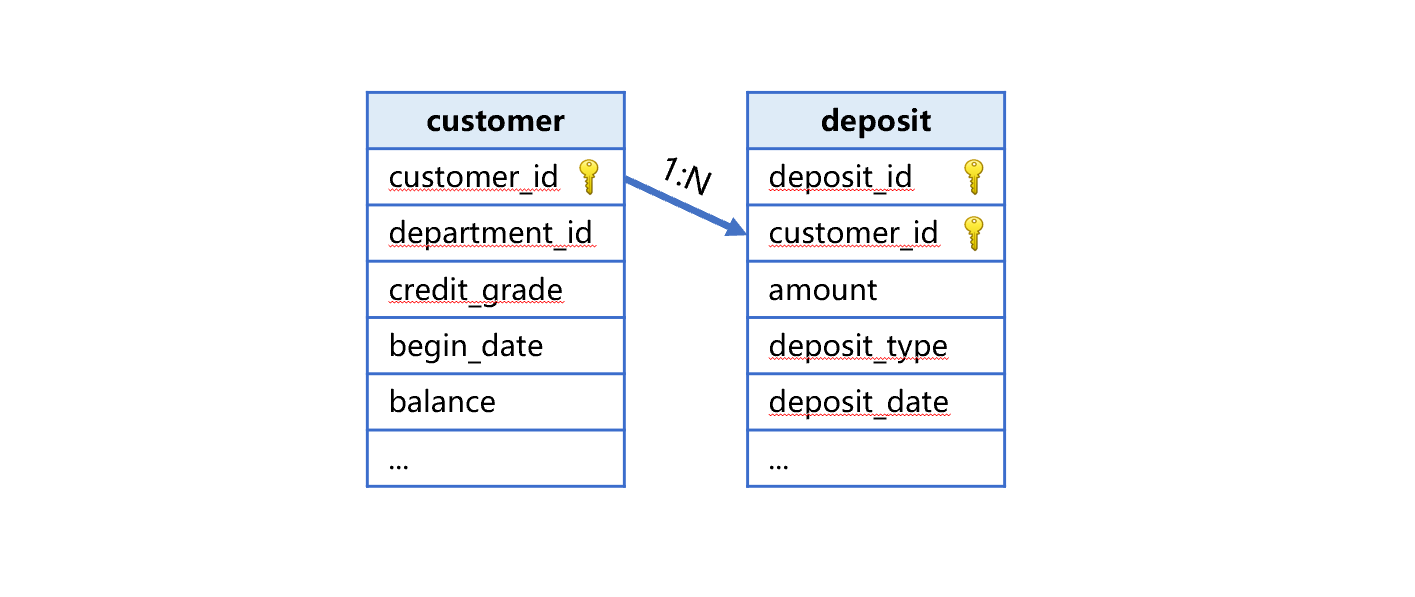
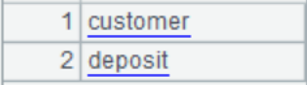
1、 准备“存款表“:从数据库中导出存款表,与客户表形成主子表,如下图:
2、 对主子表实现多维分析计算:修改查询代码。
3、 对主子表实现数据更新。
存款表包括下面这些字段:
DEPOSIT_ID NUMBER(20,0), 存款流水号
CUSTOMER_ID NUMBER(10,0), 客户编号
DEPOSIT_DATE DATE, 交易日期
AMOUNT NUMBER(8,2), 交易金额
DEPARTMENT_ID NUMBER(4,0), 分支机构编号
DEPOSIT_TYPE NUMBER(2,0) 交易类型,取值范围 1-5
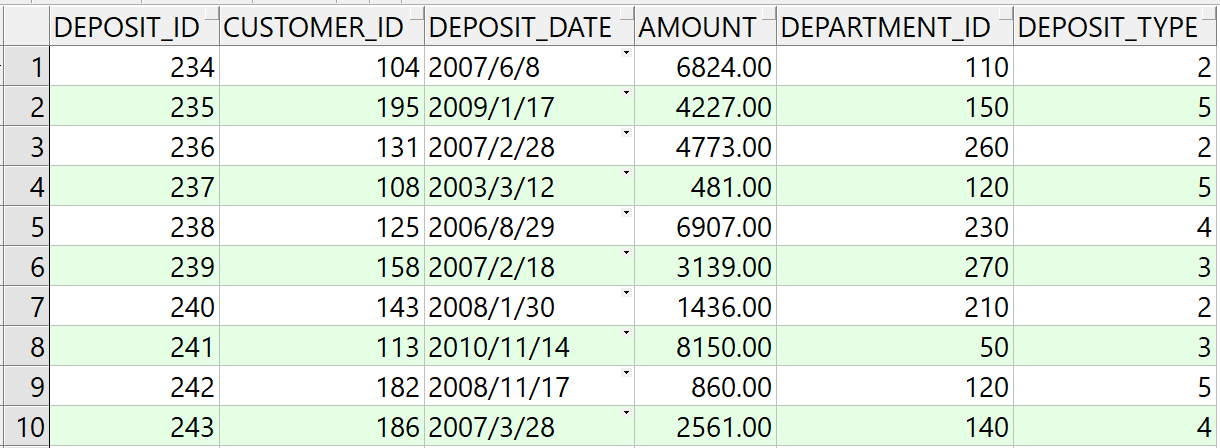
多维分析计算需求用下面 Oracle 的 SQL 表示:
select c.department_id,d.deposit_type,sum(d.amount) sum
from customer c left join DEPOSIT d on c.customer_id=d.customer_id
where d.department_id in (10,20,50,60,70,80)
and c.job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP')
and d.deposit_date>=to_date('2002-01-01','yyyy-mm-dd')
and d.deposit_date<=to_date('2002-4-31','yyyy-mm-dd')
and c.flag1='1' and c.flag8='1'
group by c.department_id,d.deposit_type
准备数据
一、有序归并
客户表直接采用前面几期的 customer.ctx 存储方式即可。
存款表要将数据库中的数据导出到 deposit.ctx。etl.splx 代码示例如下:
A |
B |
|
1 |
=connect@l("oracle") |
=date("2000-01-01") |
2 |
=A1.cursor@d("select * from deposit order by customer_id,deposit_id") |
|
3 |
=A2.new(int(customer_id):customer_id,int(deposit_id):deposit_id,int(interval@m(B1,deposit_date)*100+day(deposit_date)):deposit_date,amount,int(department_id):ddepartment_id,int(deposit_type):deposit_type) |
|
4 |
=file("data/deposit.ctx").create(#customer_id,#deposit_id,deposit_date,amount,department_id,deposit_type;customer_id) |
|
5 |
=A4.append(A3) |
>A4.close(),A1.close() |
A1:连接预先配置好的数据库 oracle,@l 是指取出字段名为小写。注意这里是小写字母L。
B1:定义日期 2000-01-01。
A2:建立数据库游标,准备取出 deposit 表的数据。游标的 @d 选项是将 oracle 的 numeric 型数据转换成 double 型数据,而非 decimal 型数据。decimal 型数据在 java 中的性能较差。
A3:用 new 函数定义三种计算。
1、 确定是整数的数值,从 double 或者 string 转换为 int。方法是直接用 int 函数做类型转换。注意 int 不能大于 2147483647,对于数据量超过这个数值的事实表,序号主键要用 long 型。
2、 用 interval 计算 deposit_date 和 2000-01-01 之间相差的整月数,乘以 100 加上 deposit_date 的日值,用 int 转换为整数存储为新的 deposit_date。
3、 department_id 是存款的分支机构,和客户表中的开户分支机构重名了,所以重命名为 ddepartment_id。
A4:定义列存组表文件,字段名和 A3 完全一致。分号后面的参数 customer_id,是指组表追加数据会按 customer_id 字段分段,不会把 customer_id 同值的记录分到两段中,为并行分段取数做准备。
A5:边计算游标 A3,边输出到组表文件中。
B5:关闭组表文件和数据库连接。
导出文件 deposit.ctx 大小是 4.2G。
二、一体化存储
修改 etl.splx,将客户和存款数据作为实表和附表存入组表文件。代码如下:
A |
B |
|
1 |
=connect@l("oracle") |
=date("2000-01-01") |
2 |
=A1.cursor@d("select * from customer order by customer_id") |
|
3 |
=A1.cursor@d("select * from deposit order by customer_id,deposit_id") |
|
4 |
=A1.query@d("select job_id from jobs order by job_id") |
=file("data/2job.btx").export@z(A4) |
5 |
=A4.(job_id) |
|
6 |
=A2.new(int(customer_id):customer_id,int(department_id):department_id,A5.pos@b(job_id):job_num,int(employee_id):employee_id,int(interval@m(B1,begin_date)*100+day(begin_date)):begin_date,first_name,last_name,phone_number,job_title,float(balance):balance,department_name,int(flag1):flag1,int(flag2):flag2,int(flag3):flag3,int(flag4):flag4,int(flag5):flag5,int(flag6):flag6,int(flag7):flag7,int(flag8):flag8,int(vip_id):vip_id,int(credit_grade):credit_grade) |
|
7 |
=A3.new(int(customer_id):customer_id,int(deposit_id):deposit_id,int(interval@m(B1,deposit_date)*100+day(deposit_date)):deposit_date,amount,int(department_id):ddepartment_id,int(deposit_type):deposit_type) |
|
8 |
=file("data/customer_deposit.ctx").create@y(#customer_id,department_id,job_num,employee_id,begin_date,first_name,last_name,phone_number,job_title,balance,department_name,flag1,flag2,flag3,flag4,flag5,flag6,flag7,flag8,vip_id,credit_grade) |
|
9 |
=A8.append(A6) |
=A8.attach(deposit,#deposit_id,deposit_date,amount,ddepartment_id,deposit_type) |
10 |
=B9.append(A7) |
|
11 |
=A8.close() |
|
A1:连接预先配置好的数据库 oracle。
B1:定义日期 2000-01-01。
A2、A3:建立数据库游标,准备取出 customer 和 deposit 表的数据。
A4、B4、A5:从数据库中取出 jobs 数据,用于 customer 中的数据转换。
A6、A7:对两个游标定义数据转换。
A9:定义 customer 组表文件。A10:从数据库游标读取 customer 数据写入组表,叫做实表。
B9:为组表文件增加一个附表 deposit,第一个主键 customer_id 和实表的主键相同,省略。其他字段不能和实表的字段重名。
B10:从数据库游标读取数据写入附表。
A11:关闭组表和数据库连接。
导出文件 customer_deposit.ctx 大小是 7.4G。
多维分析计算
一、有序归并
SPL 代码由 olapJoinx.splx 和 customerJoinx.splx 组成。前者是调用的入口,传入参数是 arg_table、arg_json,后者用来解析 arg_json。
arg_table 的值为 customerJoinx。
arg_json 的值为:
{
aggregate:
[
{
func:"sum",
field:"amount",
alias:"sum"
}
],
group:
[
"department_id",
"deposit_type"
],
slice:
[
{
dim:"ddepartment_id",
value:[10,20,50,60,70,80]
},
{
dim:"job_id",
value:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"]
},
{
dim:"deposit_date",
interval:[date("2002-01-01"),date("2020-12-31")]
},
{
dim:"flag1",
value:"1"
},
{
dim:"flag8",
value:"1"
}
]
}
customerJoinx.splx 代码如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
3 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
4 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
5 |
else |
return A1.dim/"=="/A1.value |
|
6 |
func |
||
7 |
if ifa(A6) |
return A6.(if(A9.pos(~),"c."/~,"d."/~)) |
|
8 |
else |
return if(A9.pos(A6),"c."/A6,"d."/A6) |
|
9 |
="customer_id,department_id,job_num,employee_id,begin_date,first_name,last_name,phone_number,job_title,balance,department_name,flag1,flag2,flag3,flag4,flag5,flag6,flag7,flag8,vip_id,credit_grade".split@c() |
||
10 |
=json(arg_json) |
=date("2000-01-01") |
|
11 |
=func(A6,A10.aggregate.(field)) |
=A10.aggregate.(~.func/"("/A11(#)/"):"/~.alias).concat@c() |
|
12 |
=A10.group.(if(~=="job_id","job_num",~)) |
||
13 |
=A12.(if(~=="begin_yearmonth","begin_date\\100:begin_yearmonth",~)) |
=func(A6,A13).concat@c() |
|
15 |
=[] |
=[] |
|
16 |
for A10.slice |
if (A15.dim=="begin_date"|| A15.dim=="deposit_date") && A15.value!=null |
>A15.value=int(interval@m(C10,eval(A15.value))*100+day(eval(A15.value))) |
17 |
else if (A15.dim=="begin_date"|| A15.dim=="deposit_date") && A15.value==null |
=A15.interval.(~=int(interval@m(C10,eval(~))*100+day(eval(~)))) |
|
18 |
else if A15.dim=="job_id" |
>A15.dim="job_num" |
|
19 |
>A15.value=A15.value.(job.pos@b(~)) |
||
20 |
else if like(A15.dim, "flag?") |
>A15.value=int(A15.value) |
|
21 |
>B14|=A15.dim |
=A15.dim=func(A6,A15.dim) |
|
22 |
=[func(A1,A15)] |
>A14|=B21 |
|
23 |
=A10.aggregate.(field) |
=A12.(if(~=="begin_yearmonth","begin_date",~)) |
|
24 |
=(A22|B14|C22|["customer_id"]).id() |
=A23^A9 |
=A23\B23|["customer_id"] |
25 |
=A10.group|A10.aggregate.(alias) |
=A24(A24.pos("job_id"))="job(job_num):job_id" |
|
26 |
=A24(A24.pos("begin_yearmonth"))="month@y(elapse@m(date(\""/C10/"\"),begin_yearmonth)):begin_yearmonth" |
||
27 |
=A24(A24.pos("begin_date"))="elapse@m(B4,begin_date\\100)+(begin_date%100-1):begin_date" |
||
28 |
return B23.concat@c(),C23.concat@c(),B11,C13,A14.concat("&& "),A24.concat@c() |
||
A1 到 C8 是子程序,在调用的时候才会执行。为了方便说明,我们按照执行的顺序来讲解。
A9:列出 customer 表字段,用来判断 arg_json 中的参数属于哪个表。
A10:将 arg_json 解析成序表。解析的结果是多层嵌套的序表,如下图:

其中的 aggregate 为:

其中的 group 为:

其中的 slice 为:
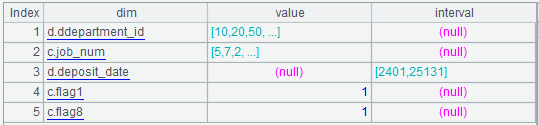
C10:定义起点日期 2000-01-01,用于参数和结果中的日期值转换。
A11:调用子程序 A6,将聚合表达式的 field 序列 A10.aggregate.(field) 作为参数传递给 A6。
B7:如果传入参数是序列,那么 C7 逐个判断序列成员是否属于 customer 表,是的话就加上 "c." 前缀,否则加上 "d." 前缀。返回 C7。
B8:如果传入参数不是序列,直接判断 A6 是否属于 customer 表,是的话就加上 "c." 前缀,否则加上 "d." 前缀。返回 C8。
此时子程序 A6 返回的结果是:

B11:先将聚合函数和对应的 A11 成员计算成冒号相连的字符串序列,如下图:

再将序列用逗号连接成一个字符串:sum(d.amount):sum,也就是聚合表达式。
A12:将 group 中的 job_id 替换为 job_num。
A13:将 A12 中的 begin_yearmonth 替换成表达式 begin_date\100:begin_yearmonth。
B13:把 A13 成员用逗号连接成一个字符串 c.department_id,d.deposit_type,也就是分组表达式。
A14:定义一个空序列,准备存放切片(过滤条件)表达式序列。
B14:定义一个空序列,准备存放切片(过滤条件)所需要的字段名。
A15:A10.slice 循环计算,循环体是 B15 到 C21。其中:B15 到 C20 是对 slice 的 value 或者 interval 做性能优化的转换。
B15:如果当前循环 slice 的 dim 是 begin_date,并且 value 不为空,也就是 begin_date 等于指定日期的情况,例如:begin_date==date("2010-11-01")。此时 C15 计算出 date("2010-11-01") 的转换后的整数值,赋值给 A15 的 value。
B16:如果 dim 是 begin_date,并且 value 为空,也就是 begin_date 在两个日期之间的情况,例如:begin_date 在 date("2002-01-01") 和 date("2020-12-31") 之间。此时 C16 计算出两个日期的转换后整数值,赋值给 A15 的 interval 的两个成员。
B17:如果 dim 是 job_id,也就是 job_id 取枚举值的情况。例如:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id)。此时 C17 要将 A15 的 dim 改为 job_num。C18 要将 A15 的 value 枚举值转换为在全局变量 job 序列中的位置,也就是 job_num 整数序列,例如:[5,7,2,15,16]。
B19:如果 dim 是 flag1、flag2…flag8,也就是标志位等于 "1" 或者 "0" 的情况。此时 C18 要将 A15 的 value 值从字符串转化为整数。
B20:将 A15.dim 追加到 B14 中。
C20:用 A15.dim 做为参数调用子程序 A6,给字段名加上表名前缀,返回结果赋值给 A15.dim。执行结果为:

B21:用 B15 到 C20 对 slice 的 value 或者 interval 做性能优化的转换的结果作为参数,调用子程序 A1。子程序 A1 和第二篇的 A1 代码相同。
C21:func A1 的返回结果追加到 A14 中。继续 A15 中的循环,到循环结束,就准备好了切片表达式的序列。
A22:取得 aggregate 中的 field 字段,也就是聚合表达式用到的所有字段名。
C22:将 group 中的 begin_yearmonth 替换成 begin_date,结果就是分组表达式所用到的所有字段名。
A23:将 A22、B14 和 C22 合并后加上一个 "customer_id", 去掉重复:
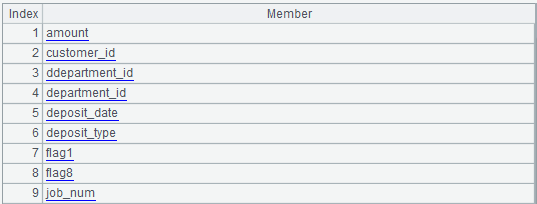
B23:求 A23 与 A9 成员的交集,也就是 customer 表的字段。
C23:求 A23 去掉 B23 之后的成员,也就是 deposit 表的字段。
A24:从这里开始准备结果集显示值转换的表达式。将 A10.group 和 A10.aggregate.alias 序列合并,如下图:

C24:将 A24 中的 job_id 替换成转换语句。语句的作用是:将结果集中的 job_num 转换为 job_id。
A25:将 A24 中的 begin_yearmonth,替换为转换语句,作用是:将分组字段中的整数值 begin_yearmonth 从整数转化为 yyyymm。
A26:将 A24 中的 begin_date,替换为转换语句,作用是:将分组字段中的整数化日期值转换为日期型。此时 A24 就是准备好的结果集显示值转换表达式:
A27:返回 B23.concat@c(),C23.concat@c(),B11,C13,A14.concat("&&"),A24.concat@c(),依次是:
本次计算用到的 customer 表字段名:
customer_id,department_id,flag1,flag8,job_num
本次计算用到的 deposit 表字段名:
amount,ddepartment_id,deposit_date,deposit_type,customer_id
聚合表达式:sum(d.amount):sum
分组表达式:c.department_id,d.deposit_type
切片表达式:
[10,20,50,60,70,80].contain(d.ddepartment_id) && [5,7,2,15,16].contain(c.job_num) && between(d.deposit_date,2401:25131) && c.flag1==1 && c.flag8==1
结果集显示值转换表达式:
department_id,deposit_type,sum
前端调用入口 olapJoinx.splx 的 arg_table 参数值是 customerJoinx.splx,代码如下:
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=file("data/customer.ctx").open().cursor@m(${A1(1)};;2) |
3 |
=file("data/deposit.ctx").open().cursor(${A1(2)};;A2) |
4 |
=joinx(A2:c,customer_id; A3:d,customer_id) |
5 |
=A4.select(${A1(5)} ) |
6 |
return A5.groups(${A1(4)};${A1(3)}).new(${A1(6)}) |
A2:实际执行的代码:
=file("data/customer.ctx").open().cursor@m(customer_id,department_id,flag1,flag8,job_num;;2)
作用是建立文件游标,设置游标过滤需要取出的字段名,并行数是 2。
A3:实际执行的代码:
=file("data/deposit.ctx").open().cursor(amount,ddepartment_id,deposit_date,deposit_type,customer_id;;A2)
根据多路游标 A2 的值,得到存款的多路游标,游标路数也是 2。
A4:有序归并两个多路游标,关联字段是 customer_id。
A5:实际执行的代码是:
=A4.select([10,20,50,60,70,80].contain(d.ddepartment_id) && [5,7,2,15,16].contain(c.job_num) && between(d.deposit_date,2401:25131) && c.flag1==1 && c.flag8==1 )
对归并后的游标定义条件过滤计算。
A6:实际执行的代码是:
return A5.groups(c.department_id,d.deposit_type; sum(d.amount):sum).new(department_id,deposit_type,sum)
对游标定义分组汇总,并实际执行游标定义的计算。
用来调用 SPL 代码的 Java 代码和上期相比没有变化,只要调整调用参数即可。
二、主子表一体化存储
SPL 代码由 olap.splx 和 customer_deposit.splx 组成。前者是调用的入口,传入参数是 arg_table、arg_json,后者用来解析 arg_json。
arg_table 的值为 customer_deposit。
arg_json 的值和有序归并相同。
customer_deposit.splx 代码如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
3 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
4 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
5 |
else |
return A1.dim/"=="/A1.value |
|
6 |
=json(arg_json) |
=date("2000-01-01") |
|
7 |
=A6.aggregate.(~.func/"("/~.field/"):"/~.alias).concat@c() |
||
8 |
=A6.group.(if(~=="job_id","job_num",~)) |
||
9 |
=A8.(if(~=="begin_yearmonth","begin_date\\100:begin_yearmonth",~)).concat@c() |
||
10 |
=A6.aggregate.(field) |
=A8.(if(~=="begin_yearmonth","begin_date",~)) |
|
11 |
=(A10|C10).id().concat@c() |
||
13 |
=[] |
||
14 |
for A6.slice |
if (A13.dim=="begin_date"||A13.dim=="deposit_date") && A13.value!=null |
>A13.value=int(interval@m(C6,eval(A13.value))*100+day(eval(A13.value))) |
15 |
else if (A13.dim=="begin_date"||A13.dim=="deposit_date") && A13.value==null |
=A13.interval.(~=int(interval@m(C6,eval(~))*100+day(eval(~)))) |
|
16 |
else if A13.dim=="job_id" |
>A13.dim="job_num" |
|
17 |
>A13.value=A13.value.(job.pos@b(~)) |
||
18 |
else if like(A13.dim, "flag?") |
>A13.value=int(A13.value) |
|
19 |
=[func(A1,A13)] |
>A12|=B18 |
|
20 |
=A6.group|A6.aggregate.(alias) |
=A19(A19.pos("job_id"))="job(job_num):job_id" |
|
21 |
=A19(A19.pos("begin_yearmonth"))="month@y(elapse@m(date(\""/C6/"\"),begin_yearmonth)):begin_yearmonth" |
||
22 |
=A19(A19.pos("begin_date"))="elapse@m(B4,begin_date\\100)+(begin_date%100-1):begin_date" |
||
23 |
return A11,A7,A9,A12.concat("&&"),A19.concat@c() |
||
可以看到,代码与第三期 customer.ctx 相比基本没有变化,只是在 B14、B15 增加了 deposit_date 的处理。
修改 olap.splx,采用一体化存储的方式计算实表和附表,代码如下:
A |
B |
|
1 |
=call(arg_table/".splx",arg_json) |
=file("data/"/arg_table/".ctx").open() |
2 |
=arg_table.split("_") |
|
3 |
if A2.len()==2 |
=B1.attach(${A2(2)}) |
4 |
=B3.cursor@m(${A1(1)};${A1(4)};2) |
return A4.groups(${A1(3)};${A1(2)}).new(${A1(6)}) |
A1:调用 customer_deposit.splx。
B2:打开 data/customer_deposit.ctx 组表文件。
A2:用下划线来分开 arg_table 参数值,结果是:
第一个成员是实表名称,第二个是附表名称。
A3:如果 A2 的长度是 2,那么 B3 就打开附表,名称就是 A2 的第二个成员 deposit。
A4:实际执行的代码:
=A3.cursor@m(amount,department_id,deposit_type;[10,20,50,60,70,80].contain(ddepartment_id) && [5,7,2,15,16].contain(job_num) && between(deposit_date,2401:25131) && flag1==1 && flag8==1)
B4:实际执行的代码:
return A4.groups(department_id,deposit_type; sum(amount):sum).new(department_id,deposit_type,sum)
用来调用 SPL 代码的 Java 代码和上期相比也没有变化,只要调整调用参数即可。
Java 代码加上后台计算返回结果总的执行时间如下:
计算方法 |
单线程 |
二线程并行 |
备注 |
有序归并 |
136秒 |
86秒 |
|
一体化存储 |
62 秒 |
41 秒 |
通过上表的对比可以看出,一体化存储相比有序归并可以提高计算性能,而且还可以兼容单宽表 OLAP 计算的代码。
新增数据
和客户表一样,存款表每天也会有新增数据,需要每天定时添加到组表文件中。我们可以改写 etlAppend.splx,网格参数如下:
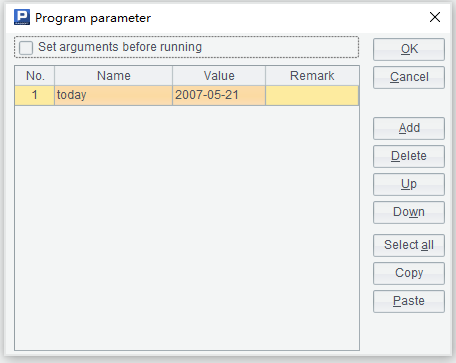
SPL 代码如下:
A |
B |
|
1 |
=connect@l("oracle") |
|
2 |
=A1.query@d("select c.customer_id customer_id,c.department_id department_id,job_id ,employee_id , begin_date, first_name, last_name, phone_number, job_title, balance, department_name, flag1, flag2, flag3, flag4, flag5, flag6, flag7, flag8, vip_id , credit_grade, deposit_id ,deposit_date ,amount,d.department_id ddepartment_id,deposit_type from customer c left join DEPOSIT d on c.customer_id=d.customer_id where begin_date=? order by c.customer_id,deposit_id",today) |
|
3 |
=A1.query@d("select job_id from jobs order by job_id") |
|
4 |
=A3.(job_id) |
=date("2000-01-01") |
5 |
=A2.new(int(customer_id):customer_id,int(department_id):department_id,A4.pos@b(job_id):job_num,int(employee_id):employee_id,int(interval@m(B4,begin_date)*100+day(begin_date)):begin_date,first_name,last_name,phone_number,job_title,float(balance):balance,department_name,int(flag1):flag1,int(flag2):flag2,int(flag3):flag3,int(flag4):flag4,int(flag5):flag5,int(flag6):flag6,int(flag7):flag7,int(flag8):flag8,int(vip_id):vip_id,int(credit_grade):credit_grade, int(deposit_id):deposit_id,int(interval@m(B4,deposit_date)*100+day(deposit_date)):deposit_date ,amount,int(ddepartment_id):ddepartment,int(deposit_type):deposit_type) |
|
6 |
=A5.groups(customer_id,department_id,job_num ,employee_id , begin_date, first_name, last_name, phone_number, job_title, balance, department_name, flag1, flag2, flag3, flag4, flag5, flag6, flag7, flag8, vip_id , credit_grade) |
|
7 |
=A5.new(customer_id,deposit_id ,deposit_date ,amount,ddepartment_id,deposit_type) |
|
8 |
=file("data/customer_deposit.ctx").open() |
=A8.append(A6.cursor()) |
9 |
=A8.attach(deposit) |
=A9.append(A7.cursor()) |
10 |
>A8.close(),A1.close() |
|
A1:连接 oracle 数据库。
A2:以 begin_date 为准,取出当天客户和存款数据。
A3:取出 jobs 表数据,用于类型转换。
A4:取出 job_id 的序列。B5:定义起始日期。
A5:对数据类型定义转化计算方法。
A6:取出其中的客户数据。
A7:取出其中的存款数据。
A8:打开 customer_deposit.ctx。B8:追加 A6 数据。
A9:打开附表 deposit。B9:追加 B9 数据。
A10:关闭文件和数据库连接。
etlAppend.splx 需要每天定时执行。执行的方法是用 ETL 工具或者操作系统定时任务,通过命令行调用集算器脚本。
例如:
C:\Program Files\raqsoft\esProc\bin>esprocx d:\olap\etlAppend.splx


英文版