


【性能优化】3.6 [外存查找] 批量查找
3.6 批量查找
前面讨论的查找主要是单个查找值,如果同时有多个查找值,是否只要简单重复多次就可以了?
对于内存查找,这样做问题不大。虽然两次查找中可能复用某些中间结果以减少计算量,但为了判断出哪些信息可复用也需要较复杂的代码(从而增大计算量),总体来看不一定能获得更好的性能。
对于外存查找,因为读取文件的时间相对于处理判断要慢得多,如果后面的查找能重复利用前面查找中已经读取的结果,即使代码复杂导致判断时间变多也常常是值得的,多查找值时就需要更细致的优化方法。
我们来考察外存的排序索引查找,多级索引将构成一个树状结构,我们假定是个 K 叉树(SPL 中这个 K 是 1024)。给定查找值 k1,…,kn,如果每次都从根节点开始查找,需要读取的索引段次数是 n*logKN 次。如果我们把曾经读过的索引段都缓存起来,在查找排在后面的查找值时就可以复用这些缓存数据而减少读取次数了。
但是,当 n 很大时,我们会发现有可能需要缓存非常多的索引段,因为不能预测哪些缓存的索引段是否会在将来用得上。太多缓存数据会占用很大的内存,有时可能被迫要丢弃一部分缓存,结果就可能在后面的查找时发生重复读取某个索引段的现象。
如果把 k1,…,kn排序后再依次查找,就可以避免这个现象。为查找 ki读取的索引段,在查找 ki+1时如果没有用到,则可以丢弃了,这些索引段在查找 ki+2,…时都不可能再用到了。
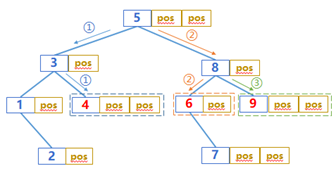
(查找 6 时,为了查找 4 而读出的索引段如果没有用到,在查找 9 时也不会被用到)
这样,在查找这批值时需要缓存的索引段很少(同时最多只有 logKN 块,也就是从根节点到叶子节点的数量,N 很大时也不会有多少),很容易在内存中放下,这样就能保证不会出现因丢弃而导致的重复读取。每次批量的查找值越多,总体优势就越大。
二分查找的情况是类似的,在没有索引时需要读取的数据量更多,已读取数据的复用效果就会更明显。
使用索引找到每个目标值的位置后,还不能马上就去原数据表中读取数据,还要等待把所有目标值的位置都找出来,然后再按这个位置排序后再去原数据表中读取数据。
原因是类似的,原数据表通常也会按块存储,每次读取一个数据块,如果两个目标值在同一个数据块中,那么只要读取一次就可以了。按位置排序后就容易复用目标值的数据块,否则,又可能发生重复读取原数据表中数据块的现象,导致时间浪费。
很多性能优化都在细节,多个环节加起来就可能获得可观的性能提升。
SPL 中已经内置了这样的算法,直接在函数使用 contain 作为条件就可以了,如果查找值是个序列,icursor 函数会先将其排序后执行上述方法。
A |
|
1 |
=file("data.ctx").open() |
2 |
=file("data.idx") |
3 |
=10000.id(rand(1000*10000)+1) |
4 |
=A1.icursor(…;A3.contain(ID);A2).fetch() |
读者可以对比执行多次单值查找和一次批量查找的时间差异。
另外,即使用了 SPL 的预加载索引,对于数据量很大的场景(需要用到四级索引段时),查找值排序仍然是有意义的。前三级都预加载了不会重复读取,第四级索引段只能临时读入(这一级数量太多了),用过之后就会丢弃以减少内存占用(前三级已经占用很大内存了),查找值无序时仍然有可能出现重复读取的现象,而在前三级已经缓存之后,这部分时间在整个查找过程中的占比就会更明显。
多查找值还可能出现在多并发的场景。每个任务都只有一个查找值,但同时可能并发几百上千个任务,这些任务相互独立,都要去各自查找,也会导致总时间很长。如果能把这些任务聚集起来,一次性查找多个,总时间要比各自查找的时间之和短得多。
可以在应用层面做处理,将一个时间区间内(比如 0.5 秒)的并发查找值收集起来,排序后一起查找再分别返回给各自的请求端。这样,每个任务最多等待 0.5 秒 + 批量查找时间,前端用户不会有明显的等待感。而如果分别查找的话,任务数较多时,被排在后面的任务就可能有明显的等待感了。
不过,这个机制要在应用程序的界面环节实现,这里无法给出相关的例程了。

