


行列方向都合并时去除重复项
列转行,去重,再行转列。关键函数:pivot和group
举例
有 csv 文件 csv1.csv,如下:
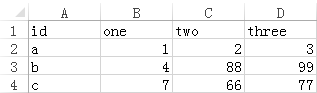
有 csv 文件 csv2.csv,如下:

现在需要把这两个表按 csv2、csv1 的顺序行列合并,遇到重复项时按顺序取第一个出现的值,结果如下:

编写 SPL 脚本:
A |
|
1 |
=file("csv1.csv").import@tc() |
2 |
=file("csv2.csv").import@tc() |
3 |
=A1.pivot@r(id;col,val) |
4 |
=A2.pivot@r(id;col,val) |
5 |
=(A3|A4).group@1(id,col) |
6 |
=A5.pivot(id;col,val) |
7 |
=file("result.csv").export@ct(A6) |
A1 从 csv 中读取数据
A2 从 csv 中读取数据
A3 列转行
A4 列转行
A5 合并后分组,取组内的第一个值,所以这里要注意合并时的顺序,会影响最终的结果。当有多组数据时,用 conj 合并,这里两个,用 | 合并即可
A6 行转列
A7 结果导出至 result.csv

