


如何实现 SQL 语句动态拼接
有结构相同的分表 A 及总表 B,将表 A 数据汇总到表 B。汇总时,根据条件,若 A 数据存在于 B 表中,则更新,若不存则插入。我们可采用 merge into 语句,它可以同时实现 update 和 insert 的功能,动态拼接成 merge into 语句让数据库执行操作。
若用 java 来实现,由 merge into 的语法特点知,需要对 on 条件,insert,update 进行多处循环拼接字段,update 处还需要去掉主键字段或索引字段,拼接 SQL 语句的一系列操作并不容易。用其它开发语言也面临类似的问题。
使用 SPL 对字段序列循环处理,实现相对容易且代码精简。
下面以同结构的源表 P_HOUSE 向目标表 T_HOUSE 数据汇总说明,其中由 ID 与 NODE_ID 组成主键。
| P_HOUSE | ID | NODE_ID | NAME | ADDRESS | CREATE_DATE |
| 1 | 100 | A | A1 | 2018-02-06 | |
| 1 | 300 | A | A10 | 2018-04-06 | |
| 2 | 100 | B | B2 | 2018-03-01 | |
| 2 | 300 | B | B20 | 2018-01-01 | |
| 3 | 100 | C | C3 | 2018-03-04 | |
| 3 | 300 | C | C30 | 2018-05-07 | |
| 10 | 300 | A | A10 | 2018-06-06 | |
| 20 | 300 | B | B20 | 2018-06-08 | |
| 30 | 300 | C | C30 | 2018-06-17 |
| T_HOUSE | ID | NODE_ID | NAME | ADDRESS | CREATE_DATE |
| 10 | 300 | AA | A100 | 2018-06-06 | |
| 20 | 300 | BB | B200 | 2018-06-08 | |
| 30 | 300 | CC | C300 | 2018-06-17 |
以 sqlserver 为例说明,动态生成的带条件 CREATE_DATE<'2018-06-10' 的 sql 语句为:
merge into T_HOUSE A using (select * from P_HOUSE where CREATE_DATE<'2018-06-10') B
on A.ID=B.ID and A.NODE_ID=B.NODE_ID
when matched then
update set A.NAME=B.NAME, A.ADDRESS=B.ADDRESS, A.CREATE_DATE= B.CREATE_DATE
when not matched then
insert values(B.ID, B.NODE_ID, B.NAME, B.ADDRESS, B.CREATE_DATE) ;
1. 集算器设置参数:
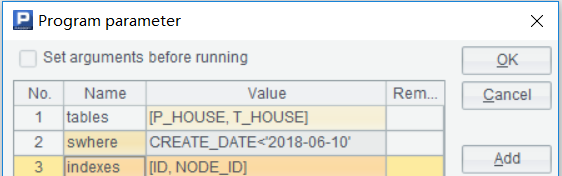
参数 tables:由源表、目标表组成的序列
swhere: 查询条件
indexes: 主键字段或索引字段组成的序列
2. 在集算器中编写脚本demo.dfx:
| A | B | |
| 1 | =connect("mssql") | / 连接数据库 |
| 2 | =A1.query("select top 1 * from "+tables(1)) | / 查询源表 |
| 3 | =A2.fname() | / 获取表字段 |
| 4 | >source=if (swhere!=null && swhere!="","(select * from "+ tables(1) +" where "+ swhere +")", tables(1)) | / 判断是否带条件的 SQL |
| 5 | ="merge into"+tables(2)+"as A using "+ source + "as B on"+ indexes.("A."+~+"=B."+~).concat(" and")+ " when matched then update set"+ (A3\indexes).("A."+~+"=B."+~).concat(",")+" when not matched then insert values("+A3.("B."+~).concat(",")+") ;" | / 动态拼接 sql 语句 |
| 6 | >A1.execute(A5) | / 执行 sql 语句 |
| 7 | >A1.close() | / 关闭连接 |
| A3 | Member |
| ID | |
| NODE_ID | |
| NAME | |
| ADDRESS | |
| CREATE_DATE |
| A5 | Value |
| merge into T_HOUSE as A using ( select * from P_HOUSE where CREATE_DATE<'2018-06-10') as B on A.ID=B.ID and A.NODE_ID=B.NODE_ID when matched then update set A.NAME=B.NAME,A.ADDRESS=B.ADDRESS,A.CREATE_DATE=B.CREATE_DATE when not matched then insert values(B.ID,B.NODE_ID,B.NAME,B.ADDRESS,B.CREATE_DATE) ; |
| T_HOUSE | ID | NODE_ID | NAME | ADDRESS | CREATE_DATE |
| 1 | 100 | A | A1 | 2018-02-06 | |
| 1 | 300 | A | A10 | 2018-04-06 | |
| 2 | 100 | B | B2 | 2018-03-01 | |
| 2 | 300 | B | B20 | 2018-01-01 | |
| 3 | 100 | C | C3 | 2018-03-04 | |
| 3 | 300 | C | C30 | 2018-05-07 | |
| 10 | 300 | A | A10 | 2018-06-06 | |
| 20 | 300 | B | B20 | 2018-06-08 | |
| 30 | 300 | CC | C300 | 2018-06-17 |
A5 :根据表字段信息动态拼接成 on 条件、insert 及 update 所需要的字段。
使用 SPL 不用去刻意记 Merge into...using... 语法,当涉及的表字段比较多时,也不需要去参考表结构信息去对照写这些字段,脚本根据参数能快速地拼接出 SQL 语句。
Java 中调用这段脚本:
public static void doWork() {
java.sql.PreparedStatement st = null;
try{
Class.forName("com.esproc.jdbc.InternalDriver");
con = DriverManager.getConnection("jdbc:esproc:local://");
// 调用脚本 demo.dfx
st =con.prepareCall("call demo(?,?,?)");
st.setObject(1, new String[]{"P_HOUSE","T_HOUSE"});
st.setObject(2, "CREATE_DATE<'2018-06-10'");
st.setObject(3, new String[]{"ID","NODE_ID"});
st.execute();
// 获取结果集
ResultSet rst = st.getResultSet();
System.out.println(rst);
}catch(Exception e){
System.out.println(e);
}finally{
// 关闭连接
if (con!=null) {
try {
con.close();
}catch(Exception e) {
System.out.println(e);
}
}
}
}

