


合并列相同的表时处理重复数据
重复数据分为以下两种情况:
1、整行重复
2、关键列重复
在处理重复数据时,又有以下三种情况:
1、只保留相同记录的其中一条
2、只保留不为空的记录
3、去掉所有重复数据
举例
例1【整行重复,去掉所有重复数据】
有 Excel 文件 600.xlsx,部分数据如下所示:

有 Excel 文件 100.xlsx,部分数据如下所示:

100.xlsx的数据是 600.xlsx 的子集
现在需要将 600.xlsx 中将出现在 100.xlsx 中的数据删除,结果如下:

编写 SPL 脚本:
A |
|
1 |
=file("600.xlsx").xlsimport@t() |
2 |
=file("100.xlsx").xlsimport@t() |
3 |
=[A1,A2].merge@d() |
4 |
=file("500.xlsx").xlsexport@t(A3) |
A1和 A2 分别读取 600.xlsx 和 100.xlsx 的数据
A3 A1中去掉与 A2 重复的记录
A4 将 A3 的结果导出到 500.xlsx
例2【关键列重复,只保留不为空的记录、只保留相同记录的其中一条】
有 Excel 文件 book1.xlsx,数据如下所示:
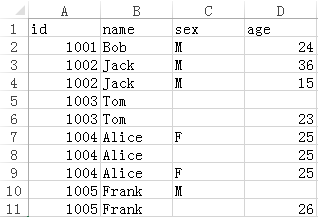
现在要去掉 sex 和 age 同时为空,并且只保留一条相同的记录,结果如下:
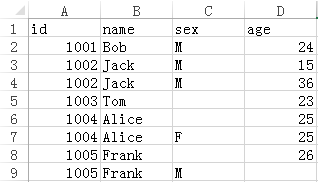
编写 SPL 脚本:
A |
|
1 |
=file("book1.xlsx").xlsimport@t() |
2 |
=A1.select(sex||age) |
3 |
=A2.group@1(id,name,sex,age) |
4 |
=file("result.xlsx").xlsexport@t(A3) |
A1 读取Excel数据,选项 @t 表示首行是列标题
A2 去掉 sex 和 age 同时为空的记录
A3 只保留一条相同的记录
A4 结果导出至 result.xlsx

