


复杂格式的行式文本提取
1. 思路
在数据处理中,有时数据来源于格式复杂的文本文件,要从中提取有用的数据,需从以下几点来思考:
1、 确定要提取数据的结构,有哪几个要提取的字段
2、 确定一行文本是否包含有效数据
3、 从有效数据行中找到提取各字段的规律
不同文本数据的规律可能不一样,但总是要有规律才能解析。
2. 举例
现有一个文本格式的客户报价单数据item.txt如下图所示:
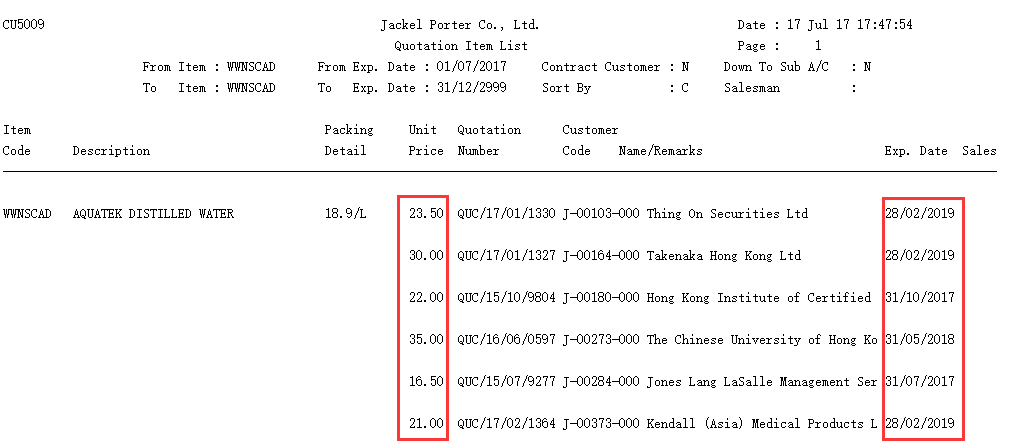
横线之前的行是复杂的表头,之后的每一行是一条报价记录,记录之间有空行。图中所示只是一个表头和报价记录区,这样的区域在文本文件中会不断地重复出现。红框所示分别是Unit Price和Exp. Date字段列,中间还有Quotation Number、Customer Code、Customer Name字段列,各列数据之间都是空格。
现在需要把文本文件中的报价单数据提取出来,存到Excel文件中如下图所示:

1、 观察并发现文本中的规律
我们发现这个文本有这样的规律:
(1)、少于136个字符的行都没有有效信息,可以跳过
(2)、所需数据位于每行59列至136列
(3)、把每行有效信息部分按空格为分隔符拆分,若第1个拆分值是数值类型,则此行是报价记录,否则可跳过。第1个拆分值是Unit Price列,第2个是Quotation Number列,第3个是Customer Code列,最后1个是Contract Expiry Date列,第4个至倒数第2个用空格连接起来是Customer Name列。
2、 编写脚本:
A |
B |
C |
|
1 |
=create(Customer_Code,Customer_Name,Quotation_No,Unit_Price,Contract_Expiry_Date) |
||
2 |
=file("E:/txt2excel/item.txt").read@n() |
||
3 |
for A2 |
if len(A3)<136 |
next |
4 |
=right(left(A3,136),-58) |
=B4.split@tp() |
|
5 |
if !ifnumber(C4(1)) |
next |
|
6 |
=C4.m(4:C4.len()-1).concat(" ") |
||
7 |
>A1.insert(0,C4(3),B6,C4(2),C4(1),C4(C4.len())) |
||
8 |
=file("E:/txt2excel/item.xlsx").xlsexport@t(A1) |
||
A1 创建目标数据集
A2 打开报价单文本文件item.txt,读入文件内容,选项@n表示每一行读成一个字符串
A3 循环处理每一行文本,实施前面找出来的规律
B3C3 如果本行长度小于136,则跳过此行
B4 提取本行数据的第59至136列
C4 对B4中提取出来的数据按空白符进行拆分,选项t表示拆分后去除两端的空白,选项p表示把拆分后的串解析成对应的数据类型
B5C5 如果C4拆分出的第一个值不是数值类型,则跳过此行
B6 将C4拆分出来的第4个值到倒数第二个值用空格连接成串
B7 将C4拆分出的第3个值、B6、C4拆分出的第2个值、第1个值、最后一个值按顺序插入到A1的新记录中
A8 将所有提取的数据保存到Excel文件item.xlsx中


英文已更新