


相邻格重复值未填时,如何批量搜索匹配顶的详细数据
例题描述和简单分析
有 Excel 文件 book1.xlsx,数据如下所示:
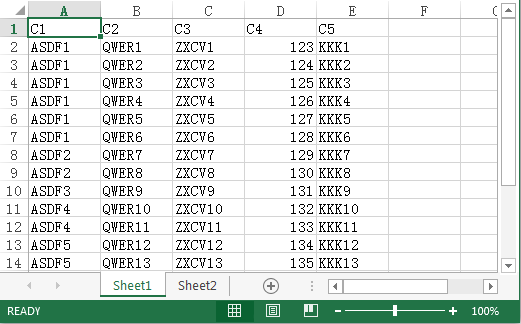
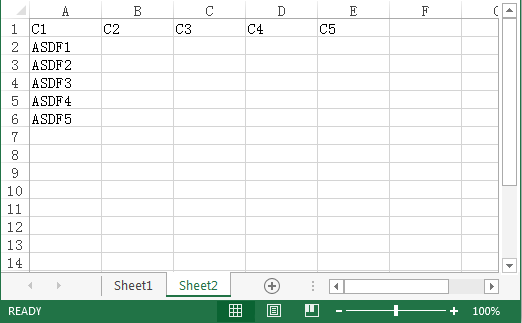
行式工作表 sheet1 是源数据,C1-C5 是列名,其中 C1 是分类列,数据已按 C1 排序;sheet2 是序列类型的参数,对应 C1;现在要根据参数从 sheet1 取 C1-C5 列,形成新工作表,其中 C1 列只保留每类第 1 条,其他条置空,结果如下:
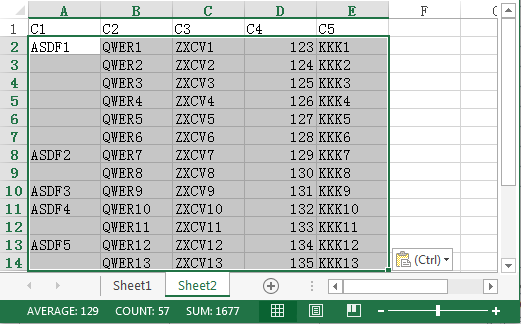
解法及简要说明
在集算器中编写脚本 p1.dfx,如下所示:
A |
|
1 |
C1 C2 C3… |
2 |
ASDF1… |
3 |
=A1.import@t() |
4 |
=A2.import@i() |
5 |
=A3.select(A4.pos(#1)) |
6 |
=A5.group(#1).(~.run(if(#==1,,#1=null))).conj() |
简要说明:
A1 复制 sheet1 中的数据(包括表头)
A2 复制 sheet2 中的数据(不包括表头)
A3 将 A1 读成序表
A4 将 A2 读成序列
A5 批量查找序表的第一列与序列匹配的记录
A6 按第一列分组,将每组内的第一列(除第一行)的值设为空值,合并。
执行程序后,在集算器中选中 A6 单元格,再点击右侧对应的“copy data”按钮。在 Excel 的 sheet2 中,点击 A2 单元格,按 Ctrl+V 就可以把计算结果粘贴过来。


英文版
英文已更新