


行式文本文件比对
1. 整行比对
有两个文本文件,其每一行是一个字符串,要对这两个文件中整行内容进行比对。处理此问题可以把文件的每一行读成一个字符串,组成一个集合,然后通过两个集合的运算得出结果。
报名绘画、舞蹈兴趣班的同学学号姓名分别记录在paint.txt和dance.txt中,paint.txt部分数据如下所示:
20121102-Joan
20121107-Jack
20121113-Mike
1.1 找相同
把两个文件中整行内容相同的行都找出来,即求两集合的交集。
示例:请找出报了这两个兴趣班的所有同学,记录在p_d.txt文件中。
esProc SPL脚本如下:
A |
|
1 |
=file("e:/txt/paint.txt").read@n() |
2 |
=file("e:/txt/dance.txt").read@n() |
3 |
=file("e:/txt/p_d.txt").write(A1^A2) |
A1 读出paint.txt的数据,选项@n表示每行读成一个字符串,所有行串组成一个集合返回
A2 读出dance.txt的数据
A3 将A1、A2集合的交集写入文件p_d.txt中
1.2 找不同
找不同有以下两种情况:
1、 找出两个文件中所有不相同的行。
示例:找出所有只报了一个兴趣班的同学, esProc SPL脚本如下:
A |
|
1 |
=file("e:/txt/paint.txt").read@n() |
2 |
=file("e:/txt/dance.txt").read@n() |
3 |
=file("e:/txt/p_d.txt").write(A1%A2) |
A1 读出paint.txt的数据,选项@n表示每行读成一个字符串,所有行串组成一个集合返回
A2 读出dance.txt的数据
A3 将A1、A2集合的异或集写入文件p_d.txt中
2、找出一个文件中有而另一个文件中没有的行。
示例:找出只报了绘画班的同学和只报了舞蹈班的同学, esProc SPL脚本如下:
A |
|
1 |
=file("e:/txt/paint.txt").read@n() |
2 |
=file("e:/txt/dance.txt").read@n() |
3 |
=file("e:/txt/p_1.txt").write(A1\A2) |
4 |
=file("e:/txt/d_1.txt").write(A2\A1) |
A1 读出paint.txt的数据,选项@n表示每行读成一个字符串,所有行串组成一个集合返回
A2 读出dance.txt的数据
A3 将绘画班A1减去舞蹈班A2所得的差集,即只报了绘画班的同学,写入文件p_1.txt中
A4 将舞蹈班A2减去绘画班A1所得的差集,即只报了舞蹈班的同学,写入文件d_1.txt中
2. 关键列比对
两个文本文件,有多列数据,第一行是列名,第二行开始是数据记录,要对两个文件中关键列的内容进行比对。处理此问题可以把文件读成数据集,取出关键列的记录值组成一个集合,然后通过两个集合的运算得出结果。
有2018、2019年的销售订单表order_2018.txt和order_2019.txt,两文件有相同的列结构,部分数据如下所示:
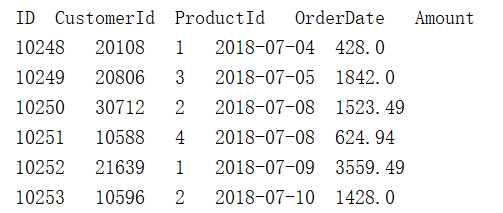
2.1 找相同
把两个文件中关键列值相同的都找出来。
示例:请找出这两年都购买了同一种产品的用户CustomerId和产品ProductId,记录在c_p.txt文件中。
esProc SPL脚本如下:
A |
|
1 |
=T("e:/txt/order_2018.txt";CustomerId,ProductId) |
2 |
=T("e:/txt/order_2019.txt";CustomerId,ProductId) |
3 |
=[A1,A2].merge@io() |
4 |
=T("e:/txt/c_p.txt",A3) |
A1 读出order_2018.txt的关键列CustomerId,ProductId数据,T函数会自动根据文件扩展名选用适合的分隔符
A2 读出order_2019.txt的关键列CustomerId,ProductId数据
A3 对两年数据进行归并,@i表示返回共同包含的记录
A4 将A3中的结果写入c_p.txt中,T函数会自动根据文件扩展名选用适合的分隔符
c_p.txt文件中部分数据如下:
CustomerId ProductId
20108 1
20806 3
2.2 找不同
示例1:找出2019年新增客户的订单情况,保存在文件new_c.txt中, esProc SPL脚本如下:
A |
|
1 |
=T("e:/txt/order_2018.txt") |
2 |
=T("e:/txt/order_2019.txt") |
3 |
=A2.id(CustomerId)\A1.id(CustomerId) |
4 |
=A2.select(A3.contain(CustomerId)) |
5 |
=T("e:/txt/new_c.txt",A4) |
A1 读出order_2018.txt的数据,T函数会自动根据文件扩展名选用适合的分隔符
A2 读出order_2019.txt的数据
A3 用2019年所有客户Id减去2018年的,得到新增的客户Id
A4 从2019年订单表筛选出新增客户的订单
A5 将A4中的结果写入new_c.txt中,T函数会自动根据文件扩展名选用适合的分隔符
new_c.txt中部分数据如下:
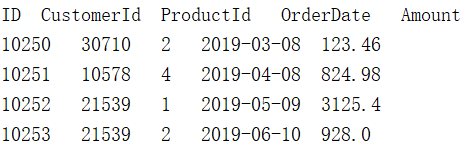
示例2:找出2019年所有流失的客户Id,保存在文件lost_c.txt中, esProc SPL脚本如下:
A |
|
1 |
=T("e:/txt/order_2018.txt") |
2 |
=T("e:/txt/order_2019.txt") |
3 |
=A1.id(CustomerId)\A2.id(CustomerId) |
4 |
=file("e:/txt/lost_c.txt").write(A3) |
A1 读出order_2018.txt的数据,T函数会自动根据文件扩展名选用适合的分隔符
A2 读出order_2019.txt的数据
A3 用2018年所有客户Id减去2019年的,得到流失的客户Id
A4 将A3中的结果写入lost_c.txt中,因为A3中的结果是序列,不是序表,所以这里不能用T函数来保存数据
注:以上几例中,如果是csv格式的文本文件,除了文件扩展名不同,脚本的写法是完全一样。

