


行式 Excel 文件去重
一个文件,有多列数据,第一行是列名,第二行开始是数据记录,要对文件中关键列的内容进行比较,对关键列内容重复的行进行删除或只保留重复的行。
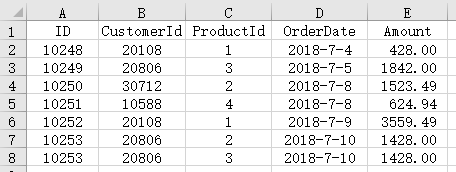
现有2018年的销售订单表order_2018.xlsx,部分数据如下所示:
1. 删除重复
示例1:请求出2018年购买产品的所有不同的客户Id,保存在文件2018c.xlsx中。
esProc SPL脚本如下:
A |
|
1 |
=T("e:/orders/order_2018.xlsx") |
2 |
=A1.id(CustomerId) |
3 |
=T("e:/orders/2018c.xlsx",A2) |
A1 读入order_2018.xlsx中数据
A2 取出A1中所有不重复的CustomerId
A3 将A2中的数据写入文件2018c.xlsx中
示例2:请求出2018年各位客户购买了哪些不同产品,将CustomerId和ProductId保存在文件2018c_p.xlsx中。
esProc SPL脚本如下:
A |
|
1 |
=T("e:/orders/order_2018.xlsx";CustomerId,ProductId) |
2 |
=A1.group@1(CustomerId,ProductId) |
3 |
=T("e:/orders/2018c_p.xlsx",A2) |
A1 读入order_2018.xlsx中CustomerId,ProductId两列数据
A2 按关键列分组,@1表示只取分组中的一条记录
A3 将A2中的数据写入文件2018c_p.xlsx中
2. 只保留重复
示例:请求出2018年回头客(即多次购买同种产品的客户)的订单情况,将结果保存在文件2018c_rebuy.xlsx中。
esProc SPL脚本如下:
A |
|
1 |
=T("e:/orders/order_2018.xlsx") |
2 |
=A1.group(CustomerId,ProductId) |
3 |
=A2.select(~.count()>1).conj() |
4 |
=T("e:/orders/2018c_rebuy.xlsx",A3) |
A1 读入order_2018.xlsx数据
A2 按关键列分组, 同一客户购买同种产品的订单分为一组
A3 选出订单数大于1的组,把各组的订单并集为一个数据表
A4 将A3中的数据写入文件2018c_rebuy.xlsx中


英文已更新