


数据挖掘中的数据类型
无论是做数据分析还是数据挖掘,数据类型是最基础的问题,不同的数据类型分析方法和处理方法是完全不同的。所有的数据都可分为两大类:定量数据(quantitative data)或定性数据(qualitative data)。
定量数据,顾名思义就是指能够用数值尺度来测量的数据,比如某产品当月的销售额,某商场每天的客流量……,通俗点讲定量数据是有大小的,一般可以进行四则运算。定量数据又可以细分为数值型变量(也就是带小数点的变量)、计数型变量(也就是整数变量)、和时间日期变量。很多时候一个变量被存储为数值型还是计数型变量,表示的实际意义是没有什么差别的,之所以区分是考虑充分利用计算机的计算效率,例如一件商品的售价存储成 50 元和 50.00 元,对业务来讲是一样的,但是对计算机来讲显然整数的运算效率要高很多。
定性数据是指不能用数值尺度记录的数据,他们仅仅能被分成不同的类别,比如人的性别分为男、女,美国 50 名 CEO 的政治背景(民主党、共和党或无党派),消费者对某产品的满意程度(十分满意,一般,不满意等)……。定性数据通常又可以区分为单值变量、二值变量、分类变量和长文本变量。单值变量是指只包含一个类别的变量,也就是变量的取值是一个单一的值,比如家用电压 [220,220,,…]。二值变量是指变量的分类有两个类别,在数据挖掘项目中,目标变量常常是这种类型的,比如贷款用户是否发生了违约行为 [是,否]。类似的分类数多于两个类别的变量称为分类变量。长文本变量则是指较长的字符串或分类数特别多的文字型变量,例如家庭住址 [北京市海淀区某某小区,湖北省武汉市某某小区,…]。在这里之所以区分这么多数据类型是基于数据挖掘对数据的要求,比如单值变量通常对建模是没有实际意义的,很多时候可以直接剔除,预测目标通常是二值变量,而长文本变量一般是无法直接利用的,需要人工提取有用信息。
另外还有一种变量称为 ID,比如每一笔订单的订单号,它的取值是唯一的,不会有重复。这种变量通常对于建模也没有意义。
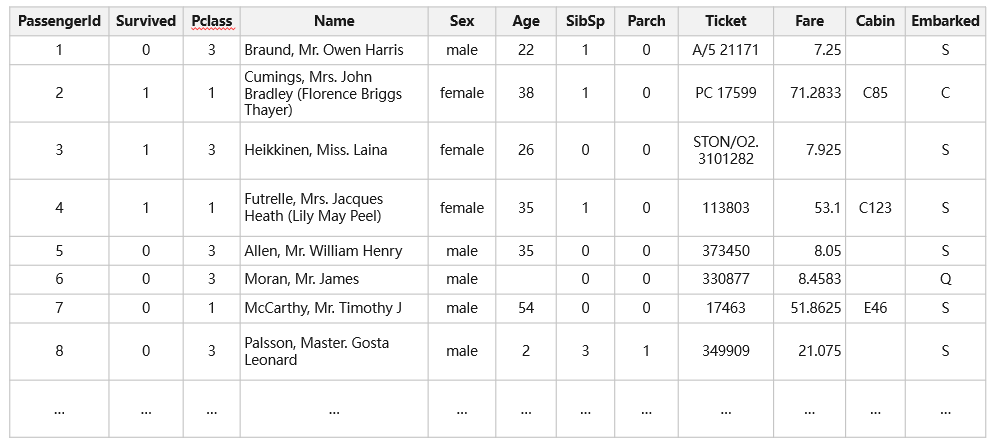
下面是 kaggle 上的经典案例,泰坦尼克生存预测为例来判断其变量的数据类型。数据部分截图如下,共计 12 个变量:
启动易明建模 YModel 软件,
将数据导入软件,数据预览:
选择检测全部数据
可以自动识别出变量数据类型
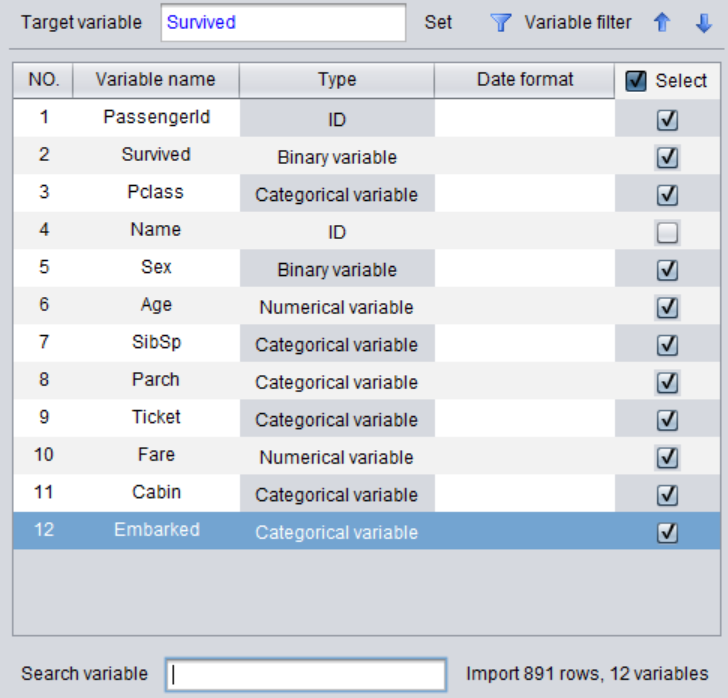
可以看到在泰坦尼克数据中有 ID,二值变量,分类变量,数值变量。数据类型的确定是数据分析和挖掘的第一步,下一步就可以根据数据类型来进行统计分析。

