如何处理巨大的 xls 文件
面对巨大的xls文件,Excel软件的性能表现很差。通常我们会想到把xls的数据放到数据库,借助数据库的计算能力来处理数据。但是有些时候,可能因为各种原因,无法导入数据库。是否有可以直接对巨大的xls文件进行数据处理的软件呢?
例如,有员工信息文件emp.xls,部分数据如下:
EID |
NAME |
SURNAME |
GENDER |
STATE |
BIRTHDAY |
HIREDATE |
DEPT |
SALARY |
1 |
Rebecca |
Moore |
F |
California |
1974-11-20 |
2005-03-11 |
R&D |
7000 |
2 |
Ashley |
Wilson |
F |
New York |
1980-07-19 |
2008-03-16 |
Finance |
11000 |
3 |
Rachel |
Johnson |
F |
New Mexico |
1970-12-17 |
2010-12-01 |
Sales |
9000 |
4 |
Emily |
Smith |
F |
Texas |
1985-03-07 |
2006-08-15 |
HR |
7000 |
有州信息文件states.xls,部分数据如下:
STATEID |
NAME |
POPULATION |
ABBR |
AREA |
CAPITAL |
REGIONID |
1 |
Alabama |
4779736 |
AL |
52419 |
Montgomery |
6 |
2 |
Alaska |
710231 |
AK |
663267 |
Juneau |
9 |
3 |
Arizona |
6392017 |
AZ |
113998 |
Phoenix |
8 |
4 |
Arkansas |
2915918 |
AR |
52897 |
Little Rock |
7 |
现需要将两份数据,通过emp的STATE列和states的NAME列关联,并筛选工资大于5000,且人口小于500万的记录结果。
借助集算器可以很方便地完成这件事。
集算器安装包可去润乾网站下载集算器职场版,运行时需要一个授权,免费版本就够用。
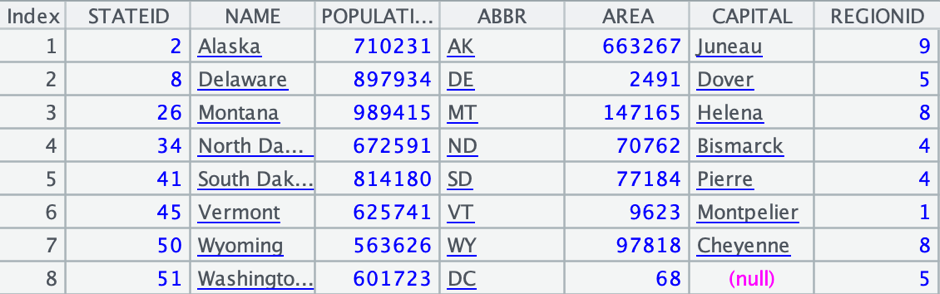
1. 过滤出州信息数据中,人口小于100万的记录:
在集算器中编写脚本wherexls.dfx:
A |
|
1 |
$select * from states.xls where POPULATION<1000000 |
A1使用简单SQL,过滤出人口小于100万的记录
执行后,A1中的结果如下:
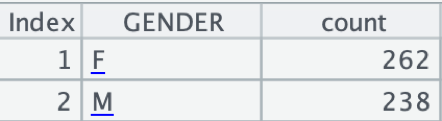
2. 对员工信息数据,按性别分组,统计人数:
在集算器中编写脚本groupxls.dfx:
A |
|
1 |
$select GENDER,count(*) as count from emp.xls group by GENDER |
A1 使用简单SQL,按性别分组,统计人数
执行后,A1中的结果如下:
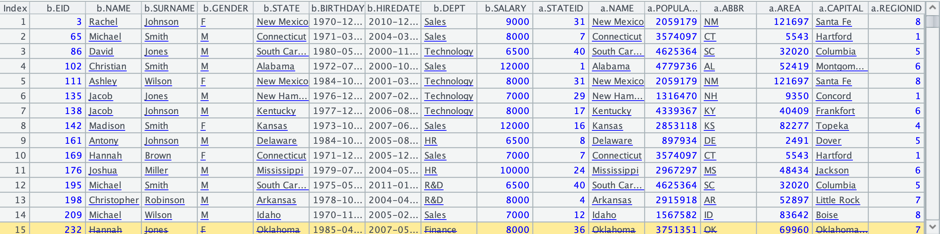
3. 连接员工信息与州信息数据,按员工信息中的STATE与州信息中的NAME关联,并过滤所在州人口小于500 万,员工工资大于5000的记录:
在集算器中编写脚本joinxls.dfx:
A |
|
1 |
$select * from emp.xls b join states.xls a on a.NAME=b.STATE where a.POPULATION<5000000 and b.SALARY >5000 |
A1 使用简单SQL完成两份数据的关联过滤运算
执行后,A1中的结果如下:
还可以将xls文件转为集文件,集文件是集算器内置的二进制文件格式,采用了简单压缩机制,相同数据量比数据库的占用空间会更小,所以读取文件的时间也就更少。
例如,现有订单表文件orders.xls,需要转为集文件,脚本如下:
A |
|
1 |
=file("orders.xls").xlsimport@t() |
2 |
=file("orders.btx").export@b(A1) |
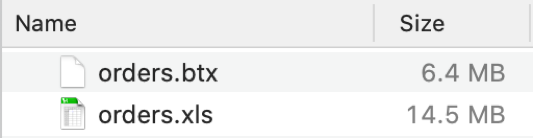
转为集文件后,两者占用硬盘空间对比如下:
集文件也可以像Excel文件一样,使用集算器进行数据处理,例如:
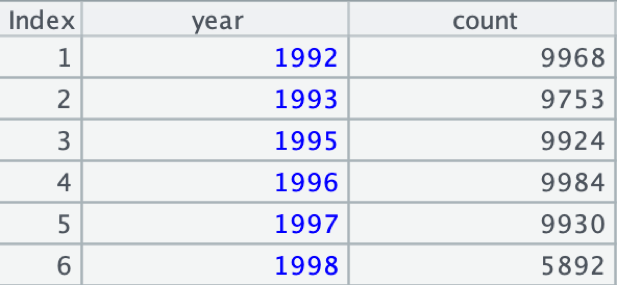
对订单文件orders.btx,按年份分组,统计订单个数小于1万的结果:
在集算器中编写脚本groupbtx.dfx:
A |
|
1 |
$select year(O_ORDERDATE) as year,count(*) as count from orders.btx group by year(O_ORDERDATE) having count(*)<10000 |
A1 使用简单SQL,按年份分组,统计订单个数
执行后,A1中的结果如下: