


数据挖掘模型的衰减是什么意思?为什么要经常要重新建模?
数据挖掘模型建好后,我们通常会关注建模时的准确率查全率等指标,但是常常会忽略模型另一个重要指标:模型的衰减程度,也就是模型在实际应用中预测能力的变化(一般都会越用越差)。
为什么会发生模型衰减呢?我们知道数据挖掘的本质是发现过去事物发生的历史规律然后对未来进行预测,因此模型能够准确预测的前提就是,要预测的未来必须是历史规律的延续。但是在几乎所有的商业场景中,市场是在不断变化的,数据也在不断变化的,也就是说历史规律也是在不断的变化。而用来训练模型的数据集通常是一个静态数据集,只能描述某一段历史时期的规律模式,随着市场的变化, 训练数据中的规律模式会逐渐不再准确,这必然导致模型在使用一段时间后会出现预测能力下降,模型结果不可靠。例如,房屋价格的预测模型,使用从 2010 年到 2020 年的数据训练出的模型,可能会能够非常准确的预测 2021 年房屋价格,但是在预测 2050 年的房屋价格时效果就会非常差了,因为房地产市场在未来几十年会不断的在发生变化。
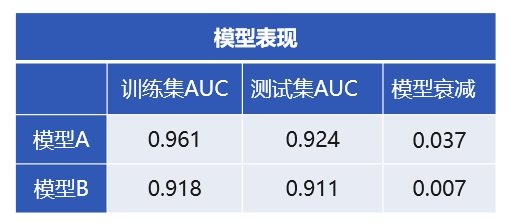
那么,模型衰减程度如何来考察呢,简单来讲可以看模型在训练数据和测试数据上的指标之差,它能够反映模型指标在预测数据(即未知数据)上的下降程度。如下表所示,模型 A 和模型 B 是在同一份数据上建立的两个模型,表中的数值是两个模型分别在训练数据和测试数据的 AUC 指标(AUC 是一种常用的模型评估指标,取值范围 0-1,越大越好)。如果仅从评估指标值的大小来判断显然使用模型 A 效果比较好,但是进一步分析模型在训练数据和测试数据上的指标变化,则发现模型 A 衰减比较快,存在一定程度的过拟合;反而模型 B 的 AUC 虽然低一些,但是衰减很小,在未知数据上的泛化能力比较好,模型比较稳定。因此应用的角度分析,模型 B 对未来数据的预测能力要好于模型 A。
既然模型是有生命周期的,那么想一劳永逸的用一个模型打遍市场就是不可能的。预测模型在生产环境中部署一段期间后,预测准确度会随着时间而下降。当性能下降到某一阈值时,就应该淘汰旧模型,重新建立新的模型。但是对于数据挖掘模型来说,重新建模就意味着要重新去分析数据的分布特点,重新预处理,重新选择算法和调参,几乎和初次建模的工作量差不多。如果更新模型和初次建模的不是同一个人,那就更加麻烦。如果有自动建模工具,模型的更新就非常方便了,只需要设定一个触发条件(比如一个月更新一次或 AUC 下降到某个值时更新),软件就会自动的建好新的模型,完全无需人工参与。
自动建模技术是将统计学家和数学家的数据处理经验和理论融入到软件中,使得软件能够智能的去完成数据预处理,建模型,选参数,做评估等一系列的工作。对于使用者来讲只需要将数据丢进自动建模工具,并且配置好目标,工具就能够自动建出优质模型。因此无论是业务人员还是普通的 IT 程序员都可以通过自动建模技术来做数据挖掘业务,连简单的 Python 都不用再学就可以享受 AI 技术带来的福利。
对进一步数据挖掘和 AI 技术感兴趣的同学还可以搜索“乾学院”,上面有面向小白的零基础“数据挖掘”免费课程,或者直接点下面的链接也可以:
http://www.raqsoft.com.cn/wx/course-data-mining.html

