


数据挖掘是什么?能解决什么问题?
数据挖掘其实是个“古老”的技术,已经有几十年历史了,近年来红火的人工智能又让这个古老技术有了更多关注。
那么,到底什么是数据挖掘呢?它又能做什么事呢?
傍晚小街路面上沁出微雨后的湿润,和煦的细风吹来,抬头看看天边的晚霞,嗯,明天又是一个好天气。走到水果摊旁,挑了个根蒂蜷缩、敲起来声音浊响的青绿西瓜,心里期待着享受这个好瓜。
由路面微湿、微风、晚霞得出明天是个好天气。根蒂蜷缩、敲声浊响、色泽青绿推断出这是个好瓜,显然,我们是根据以往的经验来对未来或未知的事物做出预测。
人可以根据经验对未来进行预测,那么机器能帮我们做这些吗?
能,这就是数据挖掘。
“经验”通常以“数据”的形式存在,数据挖掘的任务就是从历史数据(之前挑瓜的经历,注意是经历还不是经验)中挖掘出有用的“知识”,也就是所谓“模型”(现在就形成经验了),在面对新情况时(未抛开的瓜)模型就可以用来预测(是不是好瓜)。
用高中生能理解的数学语言来讲,数据挖掘建模任务的本质就是,根据一些历史已有的、从输入空间 X(如 {[色泽青绿;根蒂蜷缩;敲声浊响],[色泽乌黑;根蒂蜷缩;敲声沉闷],[色泽浅白;根蒂硬挺;敲声清脆]} )到输出空间 Y(如 {好瓜,坏瓜,坏瓜})的对应,找出一个函数 f,来描述这个对应关系,这个函数就是我们要的模型。有了模型之后再做预测就简单了,也就是拿一套新 x,用这个函数算一个 y 出来就完了。
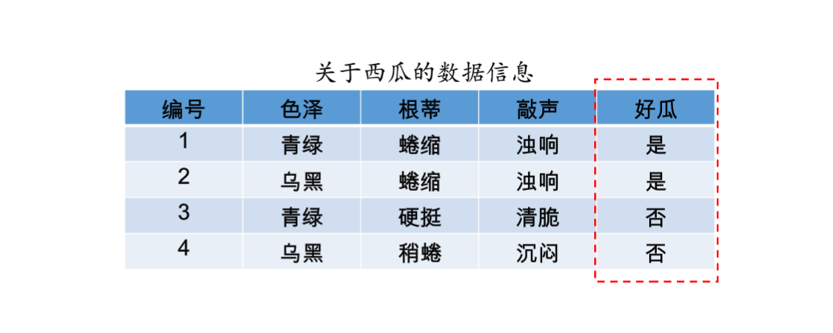
那么,模型又是怎么建立出来,也就是这个函数是怎么找出来的呢?
想想如何让一个人拥有判断瓜好坏的能力呢?
需要用一批瓜来练习,获取剖开前的特征(色泽、根蒂、敲声等),然后再剖开它看好坏。久而久之,这个人就能学会用剖开前瓜的特征来判断瓜的好坏了。朴素地想,用来练习的瓜越多,能够获得的经验也就越丰富,以后的判断也就会越准确。
用机器做数据挖掘是一样的道理,我们需要使用历史数据(用来练习的瓜)来建立模型,而建模过程也被称为训练或学习,这些历史数据称为训练数据集。训练好了模型后,就好象发现了数据的某种规律,就可以拿来做预测了。
也就是说,数据挖掘是用来做预测的,而要做到这种预测,需要有足够多已经有结果的历史数据为基础。
那么,这种预测技术如何在我们的生产销售过程中应用呢?
以贷款业务为例,金融机构要做风险控制,防止坏帐,就要在放贷前知道这个贷款人将来不能按时还款的风险,从而决定是否放贷以及贷款利率。
要做到这件事,我们要有一定数量的历史数据,也就是以前贷款人及贷款业务的各种信息,比如贷款人的收入水平、受教育程度、居住地区、信用历史、负债率等等可能会影响违约率的因素,还有贷款本身的金额、期限、利率等等。需要注意的是历史数据中一定要同时包含好客户和坏客户(也是在发生违约不还款的客户),并且坏客户的数量不能过少。
通常可以截取近几个月或近一年的历史数据作为训练数据,定义好目标变量 Y(如坏客户为 1,好客户为 0),然后就可以使用数据挖掘技术建立模型来寻找用户及贷款的各种信息 X 和目标 Y 之间的关系。建好的模型可以用来预测,及时发现高风险用户。
需要说明的,数据挖掘模型的预测并不能保证 100% 准确(有很多种办法来评估它的准确率),所以如果只有一例目标(比如只有一笔贷款)需要预测时,那就没有意义了。但通常,我们会需要都会有很多例目标需要预测,这样即使不是每一例都能预测正确,但能保证一定的准确率,这仍然是很有意义的。对于贷款业务,模型找出来的高风险客户未必都是真地,但准确率只要足够高,仍然能够有效的防范风险。
数据挖掘技术可以广泛地应用于各行各业,工业领域中可以根据历史生产数据来预测良品情况,从而改进工艺参数降低不良率;畜牧业可以使用数据挖掘技术根据测量牲畜体温来预测牲畜是否生病,从而提前防治;医院也可以使用历史医疗记录基于数据挖掘技术找出关联规律,帮助医生更好地诊断疾病。
对进一步数据挖掘和 AI 技术感兴趣的同学还可以搜索“乾学院”,上面有面向小白的零基础“数据挖掘”免费课程,或者直接点下面的链接也可以 :
http://www.raqsoft.com.cn/wx/course-data-mining.html

