


多层分组交叉报表的性能优化
需求说明

客户表样如上图所示,基础数据是 45 万条,按照扩展展开后,大约有 6 万行,13 列,需要计算后展现到页面
制作过程中的问题
1、如果直接数据集从数据库取数,展现到 web 端,那么会报错:java heap space
2、如果数据集改用集算器脚本,只对取数部分进行性能优化,那么会发现在报表单元格计算上会占用很长时间,页面加载时间过长
优化方法
思路: 在集算器脚本中完成报表样式的取数,减少单元格处理量
(感谢虎哥、猴哥的指导)
完整示例下载:
多层交叉性能优化示例.zip
使用时连内置 demo 库即可查看结果
具体实现步骤:
1、集算器脚本编辑
| A | B | C | D | |
|---|---|---|---|---|
| 1 | =connect(“demo”) | =A1.query(“select min( 雇员 ID) 最小 ID,max(雇员 ID) 最大 ID from 雇员”) | ||
| 2 | =b=B1. 最小 ID | =e=B1. 最大 ID | ||
| 3 | =p=4 | // 并行数 | ||
| 4 | =range(b,e+1,p) | |||
| 5 | =A4.to(,p) | // 分段参数初值 | ||
| 6 | =A4.to(2,) | // 分段参数终值 | ||
| 7 | fork A5,A6 | |||
| 8 | =connect(“demo”) | |||
| 9 | >output (A7) | |||
| 10 | =B8.query(“select a. 客户 ID,a. 雇员 ID,a. 货主城市,a. 运货商,a. 订单 ID,b. 职务 from 订单 a, 雇员 b where a. 雇员 ID=b. 雇员 ID and a. 雇员 ID >=? and a. 雇员 ID<?”,A7(1),A7(2)) | |||
| 11 | =A7.conj() | |||
| 12 | =A11.groups(货主城市, 运货商, 雇员 ID; 职务, 订单 ID, 客户 ID,null:fno) | =A12.groups@o(货主城市, 运货商) | ||
| 13 | =A12.run(~.fno=B12.pselect(~. 货主城市 ==A12. 货主城市 && ~. 运货商 ==A12. 运货商)) | |||
| 14 | =A13.group(雇员 ID) | |||
| 15 | =B12.(“f”/#).concat(“,”) | |||
| 16 | =create(${A15}).record(B12.( 货主城市)).record(B12.( 运货商)) | |||
| 17 | =A16.new(${“null:f0,null:f00,null:f01,”/A15}) | =A17(1).f0=“雇员 ID” | =A17(1).f00=“职务” | =A17(1).f01=“客户 ID” |
| 18 | for A14 | =A18.(订单 ID/“:f”/fno).concat(“,”)/“,”/A18(1). 雇员 ID/“:f0”/“,"”/A18(1). 职务 /“":f00”/“,"”/A18(1). 客户 ID/“":f01” | ||
| 19 | =A17.insert(0,${B18}) | |||
| 20 | result A17 |
如果 B18 中 concat 的字段值是中文,那么需要改为:
= A18.("\""/职务/"\":f"/fno).concat(",")
fork 函数使用说明可以参考: 集算器 fork 函数使用说明
后半部分程序是把数据整理成多层交叉表的展现格式,减少单元格计算量
2、报表绘制
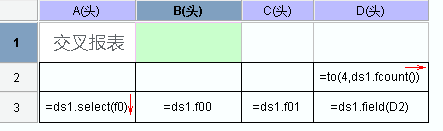
使用数据集的 fcount 函数获取字段个数,然后根据扩展值使用 field 函数分别取出数据。
优化结果
在客户本地环境测试,4 个并发进程,45 万基础数据,报表展现用了不到 20S,其中数据集取数计算 6S,单元格计算 5S,那么在正式服务器上由于配置比较高,所以这里性能还会更好一些。
客户实际数据测试上半部分取数执行时间如下:



