解析 json,整理分散数据入库
解析 json,整理分散数据入库
【问题】
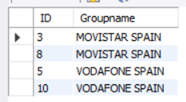
在 json 文件中有以下内容:
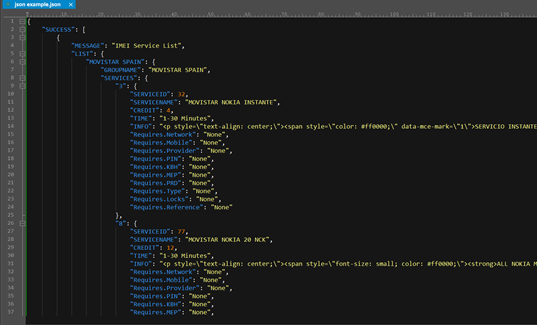
现在需要将 json 中分散的数据整理入库。
“LIST”中包含多个子孙记录,主要目标是”GROUPNAME”、”SERVICES”。
“GROUPNAME”值、”SERVICES”中的键编号对应了数据库表 _groups 的 Groupname 和 ID。

“SERVICES”每个值对应数据库表 Services 中的一条记录
【回答】
这里的 JSON 串由于包含多层且很多层都是动态的(如 LIST 和 SERVICES 下的节点数量和名称都不固定),这为解析带来了很大难度;而且其中属性名部分还包含空格(如 MOVISTAR SPAIN)和点号(如 Requires.Network)这也大大增加了解析难度,使用 JAVA 或 C# 太难写。SPL 提供了 JSON 解析功能,还可以将解析结果写入数据库:
| A | B | C | |||
|---|---|---|---|---|---|
| 1 | =json(file(“D:/test/json example.json”).read()) | ||||
| 2 | =A1.SUCCESS.LIST | ||||
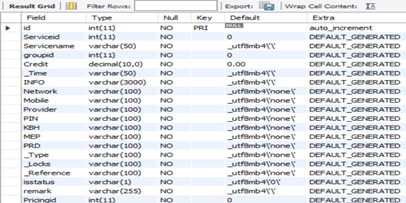
| 3 | =create(Groupname,groupid) | ||||
| 4 | =create(Serviceid,Servicename,Credit,Time,INFO,Network,Mobile,Provider,PIN,KBH,MEP,PRD,Type,Locks,Reference,groupid) | ||||
| 5 | for A2.fno() | =A2.field(A5) | |||
| 6 | =B5.SERVICES | ||||
| 7 | for B6.fno() | =B6.fname(B7) | |||
| 8 | =B6.field(B7) | ||||
| 9 | =A3.record([B5.GROUPNAME,C7]) | ||||
| 10 | =A4.record(C8.array()|C7) | ||||
| 11 | =connect(“test”) | ||||
| 12 | =A11.update(A3,_groups,Groupname,ID:groupid;ID) | ||||
| 13 | =A12.update(A4,Services,Serviceid,Servicename,Credit,_Time:Time,INFO,Network,Mobile,Provider,PIN,KBH,MEP,PRD,_Type:Type,_Locks:Locks,_Reference:Reference,groupid;Serviceid) | ||||
A1: 读取 json 文件成字符串,导入为序表。
A2:取 SUCCESS.LIST 记录
A3、A4:生成两个新的序表,用于提交。
根据 A2 字段数量循环,每个字段的值(子记录)可以在 B5 取到形如:![]
根据 B5.SERVICES 记录里的字段数量循环,每个字段的名字可以在 C7 获得,每个字段的值可在 C8 取到。B5.SERVICES 形如:
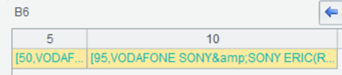
到此我们可以获得开篇所述“GROUPNAME”值、”SERVICES”中的键编号和“SERVICES”的值。向 A3、A4 新序表中循环添加记录:
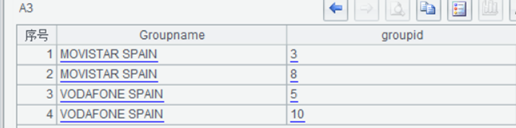
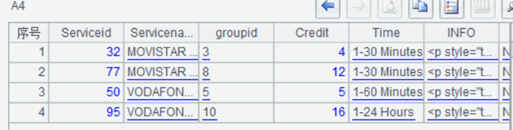
入库结果
services 表

_group 表