


集算器组表实现轻量级全文检索服务
背景
前一阵,润乾在线文档系统的全文检索变得非常慢,有时二十多秒才返回结果,甚至超时失败。全文检索服务是用的第三方服务商 Algolia,经查,其服务器在香港,用它的 WEB 管理界面查询很快,但用 Java API 查询就很慢。可能是因为使用了免费服务,也可能是连接大陆境外的网络受限制,反正不稳定。考虑自身情况,没有太复杂的搜索需求,能有简单切词、速度较快就够用,基于这种要求,调研了几种改善方案:
1、 MYSQL 的 like 函数模糊匹配:用起来简单,数据库保证了数据的实时性,一句 SQL 就搞定,试验了下性能,两千个文章时,还能一秒内返回结果,但我们有 24 万条文章,要 80 多秒才返回结果,这就不可用了。
2、 Apache Lucene:比较常规,可控制细节也非常丰富,但学习成本不低,需要专业的 JAVA 程序员开发维护。
3、 集算器组表的全文检索函数:前一阵集算器新加了全文检索功能,正好借这个机会做下测试。
初始化
简单数据存入组表
待检索文章属性:ID,标题、关键字、摘要、正文、更新时间。数据存在 MYSQL 数据库里,每个文章一条记录。

把这些数据存入集算器组表文件 article.ctx:
A |
|
1 |
d:/dfx/index/ |
2 |
=connect("mysqlDB") |
3 |
=A2.cursor("select * from article order by id asc") |
4 |
=file(A1+"article.ctx").create(#id,title,tags,summary,content,upttime) |
5 |
>A4.append(A3) |
6 |
>A2.close() |
A2:连接数据库;
A3: 从数据库查询得到游标,id 升序
A4: 定义组表结构,#id指明 id 为主键;
A5: 把数据库游标的数据存入组表
A6: 别忘了关闭数据库连接。
ETL 复杂数据存入组表
库外以独立文件存储的正文
有时候,因为文章内容太大,会把正文单独保存到一个文件里,然后数据库里相应的字段只记录文件名称,例如 contentFile,那 A3 数据库游标增加从文件加载内容的代码:
A |
|
3 |
=A2.cursor("select * from article order by id asc") .derive(file("d:/articleFiles/"+contentFile).read():content) |
derive 函数里通过 contentFile 字段值得到文件内容,存入新字段 content 里。
去除正文中 HTML 标签
互联网上的一些文章,为了方便网页显示,往往连同 HTML 标签一起存入正文,它们的大小有时会数倍于文章本身,即耗费性能,又可能对搜索结果产生干扰,所以还是要清理一下:
A |
|
3 |
=A2.cursor("select * from article order by id asc") .derive(file("d:/articleFiles/"+contentFile).read():content) .run(content.split@r("<[^>]+>").concat(" "):content) |
run 函数把去掉 HTML 标签的内容更新到 content 字段里。
实测性能
测试的文章共 24 万个,使用 MYSQL 数据库存文章属性,24 万个文章文件在硬盘上共 3.6GB;用惠普笔记本(i7CPU+24G 内存)测试。
本来上面这些 ETL 步骤,可以直接定义在游标里,然后把游标直接存入组表,这样支持无限大的数据,只要硬盘足够。但我实际测试时,用了内存方式,目的是想观察下:从数据库加载数 24 万条数据、从硬盘读取 24 万个文章文件、去除文章里 HTML 标签、存入组表这四个耗时动作,各自都有怎样的性能表现。
A |
B |
|
1 |
d:/dfx/index/ |
|
2 |
=connect("mysqlDB") |
=now() |
3 |
=A2.query("select * from article") |
=now() |
4 |
=A3.derive(file("d:/dfx/index/htmls/"+contentFile).read():content) |
=now() |
5 |
=A4.run(content.split@r("<[^>]+>").concat(" "):content) |
=now() |
6 |
=A5.new(id,title,tags,summary,content,upttime) |
|
7 |
=file(A1+"article.ctx").create(#id,title,tags,summary,content,upttime) |
|
8 |
>A7.update(A6),A7.close(),A2.close() |
=now() |
9 |
>debug("从数据库加载时间 (秒) : "/interval@s(B2,B3)) |
|
10 |
>debug("从硬盘加载文件时间 (秒) : "/interval@s(B3,B4)) |
|
11 |
>debug("去除 HTML 标签时间 (秒) : "/interval@s(B4,B5)) |
|
12 |
>debug("存入组表时间 (秒) : "/interval@s(B5,B8)) |
执行完,在控制台看结果:

可以看到,从数据库加载数据,和数据存入组表比较快,几秒内完成;读入 24 万个文章文件耗时 762 秒,清理 HTML 标签 29 秒。
题外话:如果不是实际测试,凭直觉印象猜测,一些复杂任务的性能瓶颈还真不容易猜准,有了精确的数据,性能调优才有了真凭实据。
组表建全文检索索引
生成组表文件 article.ctx 之后,我们继续测试它的全文检索功能,用 index 函数针对 content 字段,生成名为contentIdx的全文检索索引,index 的@w 选项表示所建索引为全文检索类型:
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=now() |
4 |
=A2.index@w(contentIdx;content;id) |
5 |
>debug(interval@s(A3,now())) |
执行后,在 article.ctx 同目录多了一个单独的全文检索文件:article.ctx__contentIdx;控制台打印43 秒,看来有一定量的内容时,完整创建一次全文索引也是个耗时的动作。
对比字符串查找与全文检索性能
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=now() |
4 |
=A2.cursor(id,content;like@c(content,"*组表 *")).fetch() |
5 |
=now() |
6 |
=A2.icursor(id,content;like@c(content,"*组表 *"),contentIdx).fetch() |
7 |
>debug("字符串查找 :"/interval@(A3,A5)) |
8 |
>debug("全文检索 :"/interval@(A5,now())) |
A2: 打开已经存在的组表文件;
A4: 不使用全文检索,搜索含有“组表”的文章;
A6: icursor 函数利用contentIdx索引做全文检索,测试结果和 A4 一致;
最后打印出来结果字符串查找 54 秒vs全文检索 0.8 秒,全文检索的性能还是显而易见的。
检索
返回检索结果
组表检索出包含关键字的结果是一个多条记录的序表,通过检索结果里的 id 字段就能关联上业务系统的文章。
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=A2.icursor(id,content;like@c(content,"*"+key+"*"),contentIdx) |
4 |
return string(A3.fetch().(id)) |
A2: 加载组表对象
A3: 表达式里的 key 是参数,传入要搜索的关键字
A4: 返回检索结果,检索到的 id 拼成以逗号分割的字符串。
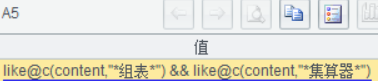
运行代码,key 值为“组表”,可以看到 A4 返回的结果:

对接业务系统
上一步的 SPL 脚本,需要能频繁的被客户业务系统的 JAVA 代码调用,互传数据。常用的是 JDBC 连接方式;有单独的集算器 SERVER,可以提供远程服务,参考 《如何远程调用 SPL 脚本》;也有嵌入的方式,参考 《如何调用 SPL 脚本》。多关键词检索
有时会组合多个关键字进行检索,我们定义 key 是以逗号分开的多个关键字,如:word1,word2,word3,查找同时含有这三个关键字的文章。基于上一步 SPL 代码,替换 A3 中条件查找部分的代码就可以了:
A |
|
3 |
=A2.icursor(id,content; like@c(content,"*"+key+"*") ,contentIdx) |
替换为:
A |
|
3 |
=A2.icursor(id,content; ${mid(key.split(",").("&& like@c(content,\"*"+~+"*\")").export(),5)} ,contentIdx).fetch() |
为了看清楚这段代码执行过程,我们把每个函数拆开执行,观察结果:

A1 假定传入的 key 值为组表, 集算器:

A2 把字符串拆成序列
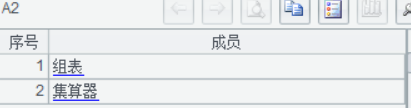
A3 把每个序列的值转变成条件表达式

A4 把条件序列再拼成字符串

A5 去掉字符串前面无用的“ && ”
上面还有一个知识点,上面算出来的条件表达式里是字符串类型,应用在函数里时,需要宏替换 ${string},这样宏替换后,才是最终要执行的函数表达式。看下面例子体会下区别:
A |
B |
|
1 |
>a=1,b=2 |
|
2 |
=”a+b” |
/结果是 "a+b" 这个字符串 |
3 |
=${a+b} |
/宏替代后,最终执行的是 =a+b,结果是 3 |
多全文检索字段
有时会有这样的需求,摘要和正文都想要被全文检索,而且摘要的优先级高于正文,所以摘要的检索结果排在前。
先创建一下摘要字段的索引:
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=A2.index@w(summaryIdx;summary;id) |
这时看到目录下两个字段的索引文件都存在了

基于最早的 SPL 检索脚本改造:
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=A2.icursor(id,summary;like@c(summary,"*"+key+"*"),summaryIdx).fetch() |
4 |
=A2.icursor(id,content;like@c(content,"*"+key+"*"),contentIdx).fetch() |
5 |
return string(A3.(id) & A4.(id)) |
新增 A3,得到摘要字段的全文检索结果;
A5 里把两个结果的 id 字段去重合并起来,并且保持了检索摘要结果在前的顺序。
分类、日期等非全文检索字段的复合条件
想把搜索限定在某些标签分类下、想把时间限定在某段内,这些复合条件的搜索可以分步实现,对全文检索的结果进行二次过滤。之前对内容建全文检索索引时,只包含了 id 字段,这次我们重建全文检索索引,把标签、时间字段都包含进来:
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=A2.index(contentIdx) |
4 |
=A2.index@w(contentIdx;content;id,title,tags,upttime) |
A3: 删除 contentIdx
A4: 增加上 title,tags,upttime 字段重建 contentIdx
基于最早的 SPL 检索脚本改造,先增加 tag,beginTime,endTime 三个参数:
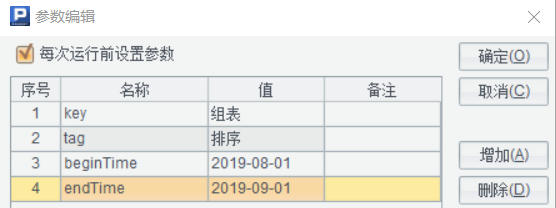
A |
|
1 |
d:/dfx/index/ |
2 |
=file(A1+"/article.ctx").create() |
3 |
=A2.icursor(id,tags,upttime,content;like@c(content,"*"+key+"*"),contentIdx).fetch() |
4 |
=A3.select(like(tags,"*"+tag+"*") && upttime>=beginTime && upttime<endTime) |
5 |
return string(A4.(id)) |
A3: 全文检索时结果里带上tags,upttime,content字段;
A4: 对全文检索结果做二次过滤。
定制结果顺序
有时,对结果的返回顺序有要求,按 id 升序、按时间降序等等。为了更通用灵活,我们把整个排序的 SPL 表达式作为字符串传进去,比如“sort(id)”、“sort@z(upttime)”分别表示按 id 升序、按 upttime 降序,程序里用 eval 函数执行表达式字符串:
A |
|
5 |
=eval("A4."+sortStr) |
支持分页返回
继续增加控制参数,还可以实现分页返回:
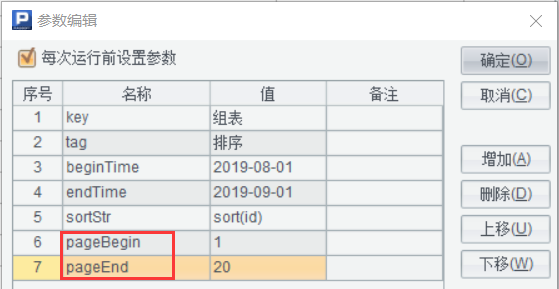
A |
|
6 |
return string(A5.m(to(pageBegin,pageEnd)).(id)) |
A6: to 函数得到序号 [1,2,3…20],m 函数从目标序表里按序号取记录。
更新
方案概述
业务系统的数据是零散时间逐渐积累起来的,那业务系统的增删改的操作,如何及时的同步到组表里,如何更新全文检索索引,有多种控制粒度的方案可选。
1、 业务系统数据每次发生变化,通知组表管理程序,重新获取业务系统全部数据,这种粒度最粗犷,不用关心哪些数据发生了何种(增删改)变化。
2、 业务系统数据每次发生变化时,只把增删改的数据通知组表管理程序,进行局部更新;
3、 在业务系统积累一批变动的数据,增加、修改的数据记录最后修改时间;删除的数据记录删除 id;隔一段时间批量提交一次。这种批量改动的数据,可以在业务系统数据库里积累,也可以选择提交到组表管理程序,在库外用集算器文件记录;
4、 批量更新,造成的结果是把数据分成了两部分,新的临时数据和全量历史数据。对检索实时性要求不高时,新的临时数据可以不在检索范围内,只检索全量历史数据,比如当天更新的数据,半夜批量更新后,第二天才能被检索到。
5、 如果非要 T+0 实时检索,那就要对两部分数据分别检索,然后再合并结果,临时数据因为量很小,不论是存在数据库,还是存在库外的集算器组表文件里,都能快速响应,根据自己的情况自由选择。
方案示例(数据库积累更新数据,定时批量提交、T+0 检索)
数据
数据库article 表和组表 article.ctx 同结构:id,title,tags,summary,content,uptime。其中 id 为主键,upttime 记录最后更新时间,每天深夜定时批量提交当天更新的文章数据。
删除的文章时,把删除信息传递到组表有这么三种方式:
1、article 表里不删除记录,只通过字段标识删除状态,那更新到组表时,把这些删除 id 也提交了就可以;
2、对比article 表和article 组表,组表里的 id 在数据库表里找不到,那就是删除了;两表的数据量大时,这种方式会比较慢;
3、单独创建一个数据库表记录删除文章,每天提交当天删除的文章 id 即可;
我们采用第 3 种方式, deletedArticle 表,id,deleteTime;
SPL 更新程序 update.dfx
每天深夜 12 点过后执行,把前一天更新、删除的数据更新到组表,重建全文检索。
A |
|
1 |
d:/dfx/index/ |
2 |
=connect("mysqlDB") |
3 |
=A2.query("select * from article where upttime>=? and upttime<?",elapse(date(now()),-1), date(now())) |
4 |
=A2.query("select id from deletedArticle where deleteTime>=? and deleteTime<?",elapse(date(now()),-1), date(now())) |
5 |
=file(A1+"/article.ctx").create() |
6 |
>A5.update(A3), A5.delete(A4), A5.close() |
7 |
>file(A1+"/article.ctx").reset() |
8 |
>A2.close() |
A3: 从数据库得到昨天整天积累的更新文章;
A4: 从数据库得到昨天整天积累的删除文章 id;
A5: 打开组表文件;
A6: 更新组表文件;
A7: 重置组表,自动重建全文检索索引。
SPL T+0 检索程序 index.dfx
为了演示 T+0 查询方案,这里只用最简单的单个关键字查询;明白原理后,参考之前多种检索需求灵活结合就可以了。数据库检索慢,但因为涉及的数据量很小,对性能几乎没有影响。

A |
|
1 |
d:/dfx/index/ |
2 |
=connect("mysqlDB") |
3 |
=A2.query("select id from article where upttime>=? and content like ?", "%"+key+"%") |
4 |
=A2.query("select id from article where upttime>=?", date(now())) |
5 |
=A2.query("select id from deletedArticle where deleteTime>=?", date(now())) |
6 |
=file(A1+"/article.ctx").create() |
7 |
=A6.icursor(id;like@c(content,"*"+key+"*"),contentIdx).fetch() |
8 |
=A7.select((A4 & A5).(id).pos(id)==null) |
9 |
=string((A3 & A7).(id)) |
10 |
return A9 |
A2: 创建数据库连接;
A3: 从数据库检索今天更新且包含 key 的文章 id;
A4: 从数据库取出今天更新的文章 id;
A5: 从数据库取出今天删除的文章 id;
A6: 打开组表文件;
A7: 从组表里检索包含 key 的历史文章 id;
A8: 组表检索结果里剔除今天增删改的文章;
A9: 合并数据库和组表里符合条件的结果。

