

























回帖
请输入回帖内容
...

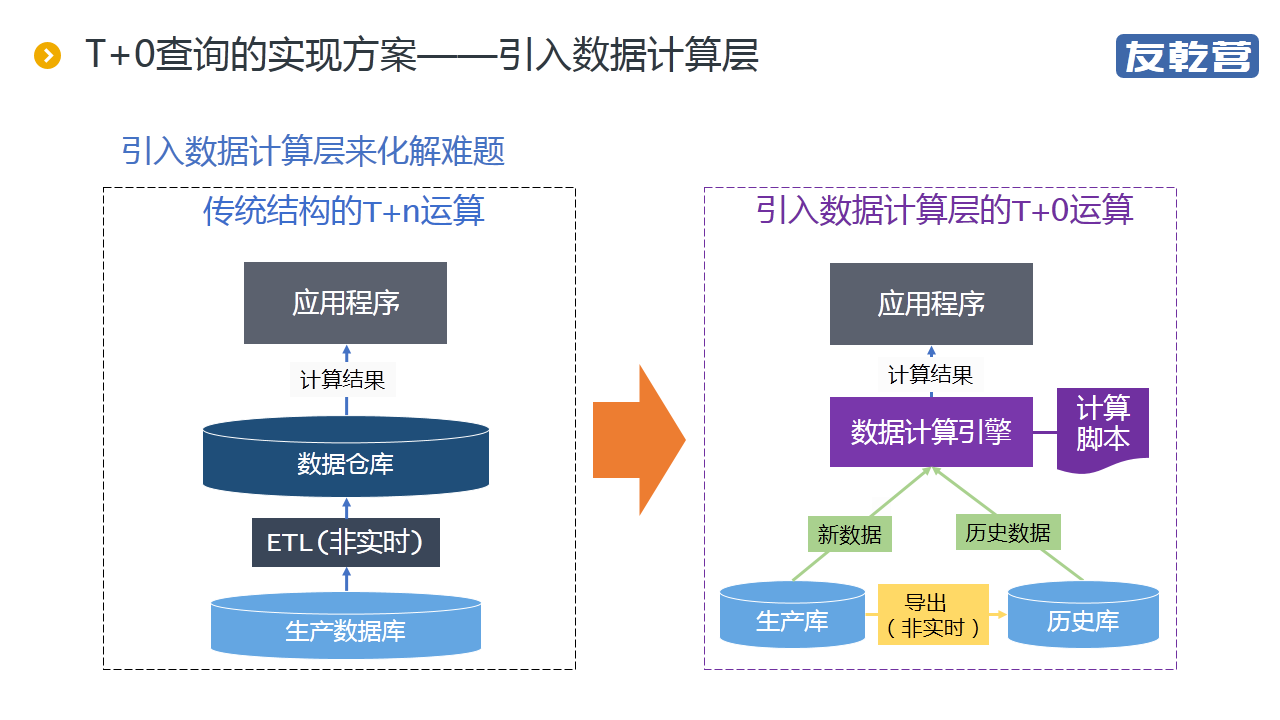
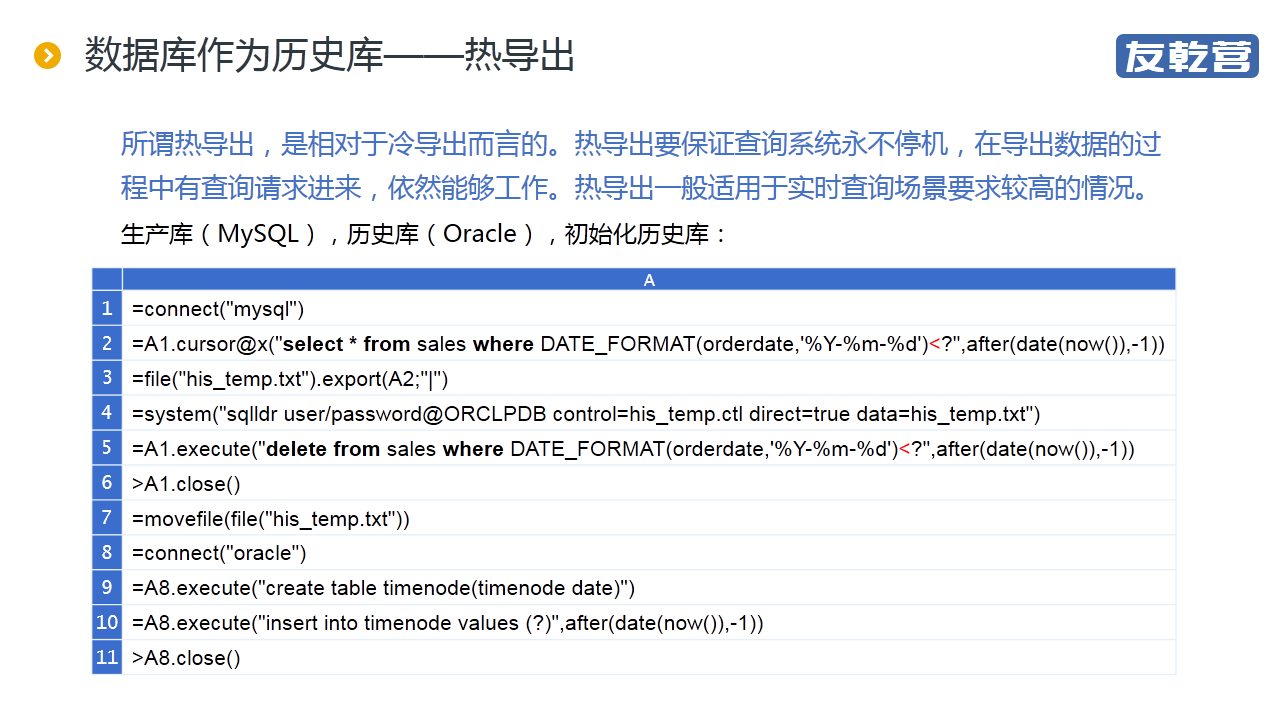
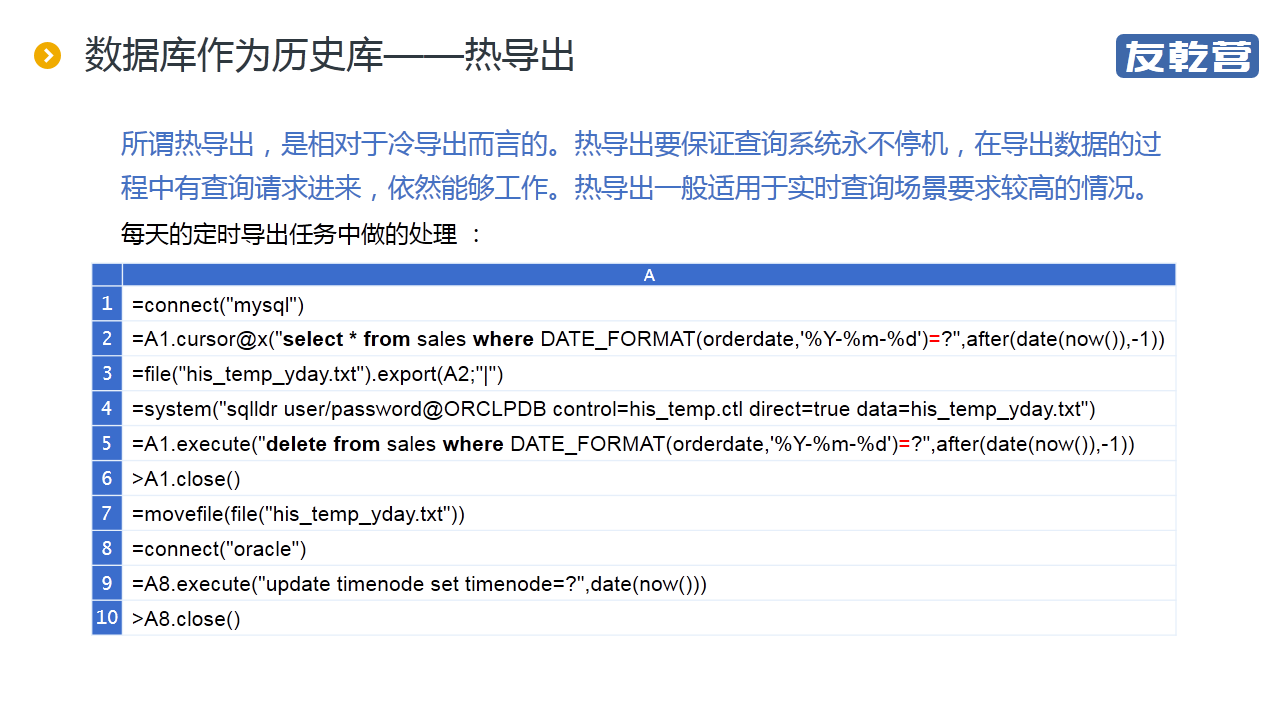
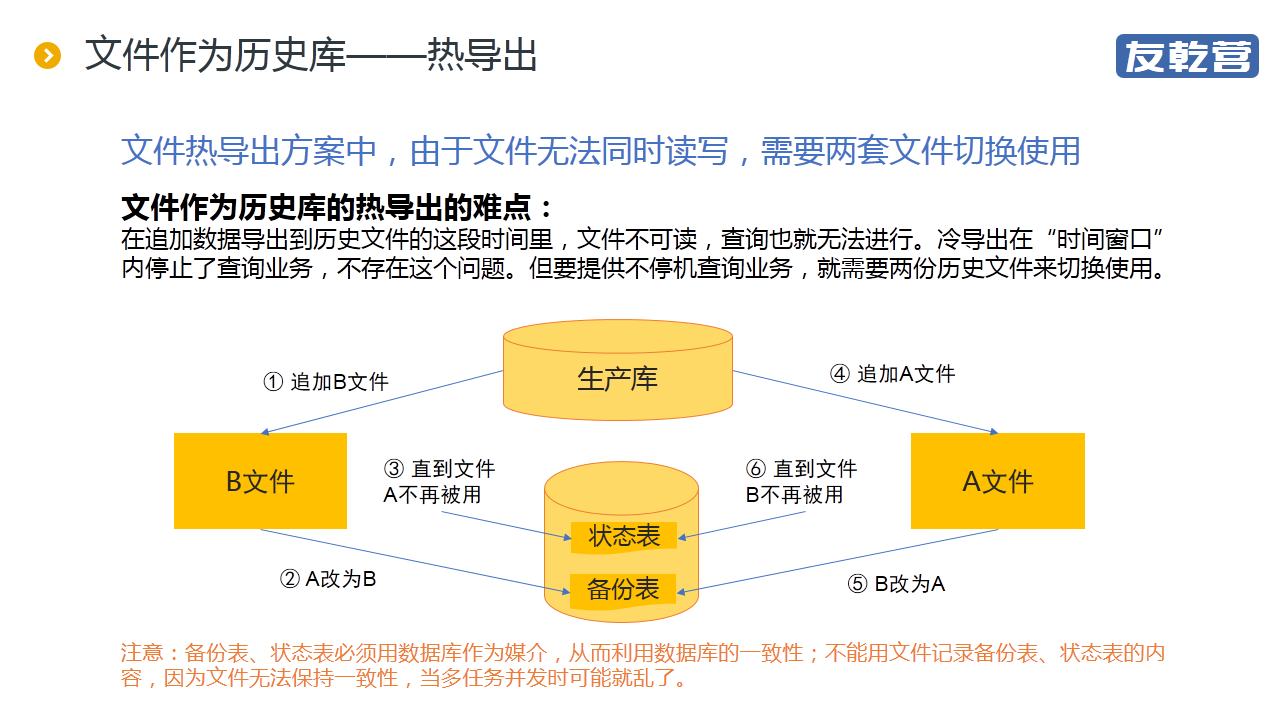
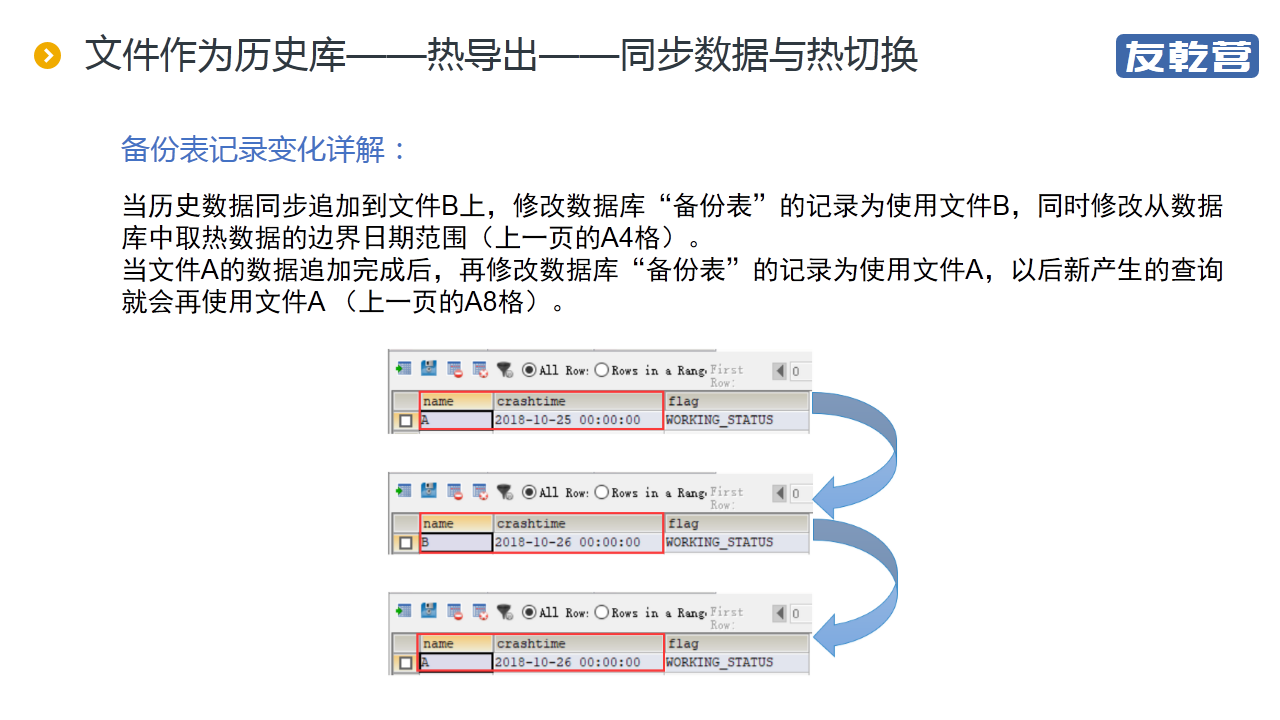
"【摘要】 定期将大数据导出到历史库以减轻生产库的压力,再基于分库计算技术,不难实现高性能的 T+0 查询报表。但如何导出却是个问题。 冷导出相对容易,但导出过程中必须停止服务。若要保证提供不间 .."

