分组后组内成员对齐
分组后组内成员对齐
【问题】
I am working on a jasper report in that I am using a field “RACE_CODE” which contains values like ‘abc’,‘lmn’,‘pqr’,‘xyz’. For one person there can be multiple RACE_CODE assigned to it.
So I want the output in term of four digits like:
If a person have RACE_CODE ‘abc’ and ‘xyz’ then it should display ‘1001’ and so on.
I can use conditional statement like:
$F{RACE_CODE} == ‘abc’ && $F{RACE_CODE} == ‘xyz’ ?
‘1001’ : ($F{RACE_CODE} == ‘abc’ ? ‘1000’ : (so on…
But this is not a feasible way because for four digits I will be having 16 combinations.
In practical I have 7 race codes. SO its not possible to have so many combinations in the default_value_expression clause.
Is there any other way in which I can achieve this? Please help to solve this.
What I want is given in the pseudo code below:
if RACE_CODE CONTAINS (‘abc’,‘pqr’)
then display 1010
if RACE_CODE CONTAINS (‘lmn’,‘pqr’,‘xyz’)
then display 0111
and so on
…
【回答】
提问者有人物 - 代码表,代码是一系列固定值的有序的字符串,一个人物可以对应多个代码。他希望将每个人物对应的代码汇总成一串 1 和 0 组成的字符串,当人物有某个代码记录时,汇总字符串对应顺序上的数字是 1,反之是 0。
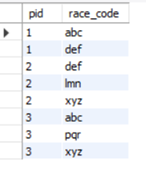
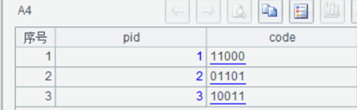
原表如上图所示,如共有 5 种字符串代码,abc 对应第一位、def 对应第二位……那么 id 为 1 的人汇总码应该为 11000。解决思路是将数据按 pid 分组,将组内的 race_code 按照固定顺序的字符串组 [“abc”,“def”,“lmn”,“pqr”,“xyz”] 对齐,再翻译为 01 编码。用 SPL 可以这样做:
| A | |
|---|---|
| 1 | =connect(“test”) |
| 2 | =A1.query@x(“select * from race_code_table”) |
| 3 | =[“abc”,“def”,“lmn”,“pqr”,“xyz”] |
| 4 | =A2.group(pid;~.align(A3,race_code).(if(~,“1”,“0”)).concat():code) |
A1: 连接 test 数据库。
A2:查原表。
A3:作为对齐标准的有序字符串序列。
A4:按照 pid 对原始数据分组,并根据原始记录计算出 code 列:与 A3 序列按 race_code 对齐后,非空为 1,空值为 0,并将这个结果拼成字符串。
A4