


合并 mongodb 子文档
来源:https://groups.google.com/forum/#!topic/mongodb-user/BpgEaRqrKsA
**【摘要】**
Mongodb 的 BSON 存储格式灵活多样,有助于 MongoDB 的入门学习。有集算器 SPL 语言支持后,Mongodb 能实现像数据 SQL 那样的方便查询。若想了解更多,请前往乾学院:合并 mongodb 子文档!
MongoDB文档的存储格式是BSON,一种类JSON的二进制形式的存储格式。如果熟悉JSON格式,将非常有助于MongoDB的入门学习,不过和JSON一样, BSON结构灵活,组织形式多样,在提供了强大的数据表达能力的同时,要实现类似数据SQL那样的方便查询却变成了一件非常不容易的事。
针对这个问题,集算器SPL语言内置了丰富的接口,能够极大地方便用户使用Mongodb。 下面就用合并内嵌子文档结构的例子来举例说明。
Collection C1的部分数据如下:
{ |
要求按name分组,每组数据是相同的name对应的子文档中的users字段,且数据不能重复。最后的计算结果类似下面这样:
{ |
使用集算器SPL的代码如下:
| A | B | ||
| 1 | =mongo_open("mongodb://localhost:27017/local?user=test&password=test") | ||
| 2 | =mongo_shell(A1,"c1.find(,{_id:0};{name:1})") | ||
| 3 | for A2;name | =A3.(acls.read.users|acls.append.users|acls.edit.users|acls.fullControl.users) | |
| 4 | =B3.new(A3.name:_id,B3.union().id():readUsers) | ||
| 5 | =@|B4.group@1(~._id,~.readUsers) | ||
| 6 | =mongo_close(A1) | ||
A1:连接MongoDB,连接字格式为mongo://ip:port/db?arg=value&…
A2: 使用find函数从MongoDB中取数并排序,形成游标:collectoin是c1,过滤条件是空,取出_id之外的所有字段,并按name排序。
A3: 循环从游标读数,每次取name字段相同的一组文档。A3循环的作用范围是缩进的B3到B5,在这个作用范围内可以用A3来引用循环变量。
B3:取出本组文档的所有users字段,如下:
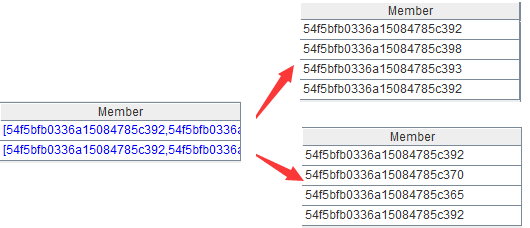
B4:合并本组各文档的users。
B5:将B4去除重复记录后不断地追加到B5中,其中group@1实现去重处理。B5如下:
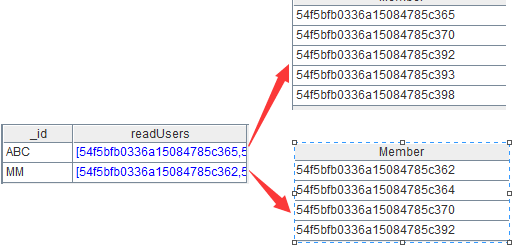
B5就是本案例的计算目标。如果计算结果太多导致内存放不下,可以在B5中用函数export@j将B4转为json串,不断地追加到文本文件中。
A6:关闭mongodb。
MongoDB丰富灵活的存储结构轻量化、高效性,让人印象深刻,而集算器能与它天然融合,提高使用效率,扩展了应用空间。


英文版