按列取数据,找出文本 distinct 的列
【问题】
I am new to all this, and this is probably a rather simple question, but I am stuck:
I have a large number of individual files that contain six columns each (number of rows can vary). As a simple example:
1 0 0 0 0 0
0 1 1 1 0 0
I am trying to identify how many unique columns I have (i.e. numbers and their order match), in this case it would be 3.
Is there a simple one-liner to do this? I know it is easy to compare one column with another column, but how to find identical columns?
【回答】
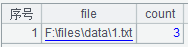
除了awk,该问题使用SPL也是个不错的选择,可以处理更复杂些的逻辑,比如下面这句代码可以完成/data目录下所有文件的唯一列统计:
A |
|
1 |
=directory@p("F:\\files\\data").new(~:file,(a=file(~).import(),a.fno().(a.field(~)).id().count()):count) |
A1:按顺序计算每个文件中不同列值的数量,并将结果写到一个由file和count构成的二维表,结果如下: