


SPL 简化 SQL 案例详解:多级关联
在数据库应用开发中,我们经常需要面对复杂的SQL式计算,多级关联就是其中一种。SQL的join语句比较抽象,只适合表达简单的关联关系,一旦关联的层级较多,相应的代码就会变得非常复杂。而SPL则可以利用对象引用来表达关联关系,从而使代码更加直观,下面就用一个例子来加以说明。
表channel存储着某网站所有的频道及其上级频道的对应关系,分别用ID和PARENT字段来表示,最多四级,其中root代表网站本身(即根节点)。表中部分数据如下:
ID |
PARENT |
NAME |
p1 |
root |
news |
p2 |
root |
health |
p3 |
root |
manage |
c11 |
p1 |
Scenic Introduction |
c12 |
p1 |
Places of Interest |
c13 |
p1 |
Local culture |
c21 |
p2 |
Scenic Service |
c22 |
p2 |
E-commerce |
c31 |
p3 |
Travel Tips |
d111 |
c11 |
Investment Projects |
d112 |
c11 |
Virtual tour |
d113 |
c11 |
Places of Interest |
d114 |
c11 |
Historical legends |
d115 |
c11 |
Resort weather |
d121 |
c12 |
Ticket booking |
现在想要根据参数输入的ID,分层列出该频道所有下级的名称,同一层的下级之间用逗号分隔。假设参数arg1的值是p1,我们期望的结果如下图所示:

SPL代码如下:
A |
B |
|
1 |
=db.query("select * from channel") |
>A1.switch(PARENT,A1:ID) |
2 |
=create(ID,LEVEL,SUB) |
|
3 |
=A1.select(PARENT.ID==arg1) |
>A2.insert(0,arg1,1,A3.(NAME).string()) |
4 |
=A1.select(PARENT.PARENT.ID==arg1) |
>A2.insert(0,arg1,2,A4.(NAME).string()) |
5 |
=A1.select(PARENT.PARENT.PARENT.ID==arg1) |
>A2.insert(0,arg1,3,A5.(NAME).string()) |
6 |
>file("channel.xlsx").xlsexport@t(A2) |
A1:查询表channel,部分结果如下图所示:

B1:>A1.switch(PARENT,A1:ID),使用函数switch将表中PARENT字段替换成对应的记录引用,如下图所示:
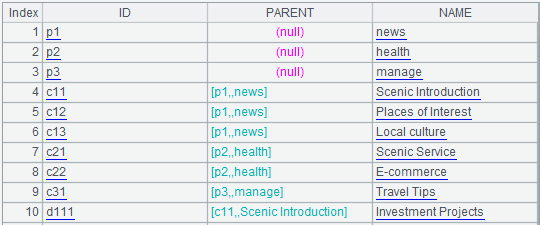
切换后,可以直接用PARENT.ID来表示上级(父)频道,而PARENT. PARENT. PARENT.ID则可以直接表示上三级(曾祖父)频道。虽然在SQL中也可以用join来表示这种自连接,但层级多了后显然容易产生混乱。
A2:=create(ID,LEVEL,SUB),建立一个空序表,用来存储最终的计算结果。
A3:=A1.select(PARENT.ID==arg1),从表中查询出上级(父)频道等于参数arg1的记录,即:arg1的下一级(子)频道。计算结果如下:
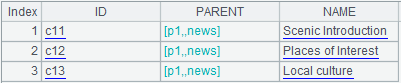
B3:>A2.insert(0,arg1,1,A3.(NAME).string()),在A2中追加一条记录,第一个字段值是arg1;第二个字段值为1,表示第一级子频道;第三个字段为表达式A3.(NAME).string(),表示取出A3中的列NAME,拼成逗号分隔的字符串。计算结果如下:

A4:=A1.select(PARENT.PARENT.ID==arg1),这句代码和A3类似,表示从表中查询出arg1的下两级(孙子)频道。结果如下:
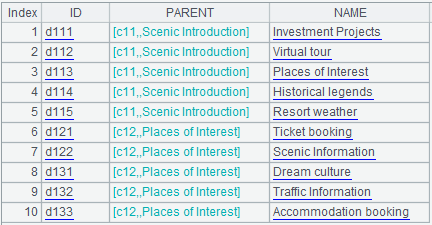
A5和A4类似,表示取出arg1的下三级(曾孙)频道。用类似的办法可以轻松取出下N级的频道。
B4、B5和B3类似,都是向A2中追加新记录,只是level字段改为2和3。执行完B5后,A2就是本次运算的最终结果:

刚才参数arg1的值为p1,如果输入c12,则计算结果如下:

有时我们希望看到更清晰的数据,比如将某个频道的所有下级频道一条条列出,并标出层级关系。如下图所示:

要想实现这种算法,可以使用下面的代码:
A |
B |
|
1 |
=db.query("select * from channel") |
>A1.switch(PARENT,A1:ID) |
2 |
=create(ID,LEVEL,SUB) |
|
3 |
=A1.select(PARENT.ID==arg1) |
=A2.insert(0,arg1,1,A3) |
4 |
=A1.select(PARENT.PARENT.ID==arg1) |
=A2.insert(0,arg1,2,A4) |
5 |
=A1.select(PARENT.PARENT.PARENT.ID==arg1) |
=A2.insert(0,arg1,3,A5) |
6 |
=A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)) |
|
7 |
=A6.union() |
红色字体为变动后的代码,其中B3中的代码是=A2.insert(0,arg1,1,A3),这表示直接将A3的记录存储在A2中,假设参数arg1的值为p1,则计算结果如下:

点开SUB字段,可以看到详细的记录:

可以看到,SPL的字段值是泛型的,可以存储记录组,或者单条记录。而函数switch的本质就是将外键切换为主表中对应的记录。
执行完B5后,A2中的结果如下:

A6:=A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)),用来将A2中ID和LEVEL拼到SUB字段里的每条记录中。其中A2.()表示对A2进行计算,计算中可以使用“~”来表示A2中的每条记录,~.SUB则表示每条记录的SUB字段(记录组)。函数new用来生成新的序表,即:A2中的ID字段、LEVEL字段,SUB中的ID字段、NAME字段。计算完成后,A6的值如下:

A7=A6.union(),这句代码用来将A7的各组记录拼在一起,形成最终计算结果:
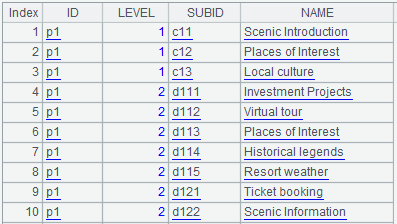
有时我们需要直接列出每个频道的所有下级频道。要想实现这种算法,可以使用SPL的for语句,代码如下:
A |
B |
C |
|
1 |
=db.query("select * from channel") |
>A1.switch(PARENT,A1:ID) |
|
2 |
=create(ID,LEVEL,SUB) |
||
3 |
for A1.(ID) |
=A1.select(PARENT.ID==A3) |
=A2.insert(0,A3,1,B3) |
4 |
=A1.select(PARENT.PARENT.ID==A3) |
=A2.insert(0,A3,2,B4) |
|
5 |
=A1.select(PARENT.PARENT.PARENT.ID==A3) |
=A2.insert(0,A3,3,B5) |
|
6 |
=A2.(~.SUB.new(A2.ID,A2.LEVEL,ID:SUBID,NAME)) |
||
7 |
=A6.union() |
A3中的代码for A1.(ID)表示循环A1的ID字段,每次取出一条,可以用循环语句所在的单元格A3来表示循环变量。循环的作用范围可以用缩进来表示,例子中的循环范围就是B 3:C5。最终的计算结果在A7中,部分数据如下:

从这些例子可以看出,使用SPL简化多级关联问题时,思路直观明了,代码简洁易懂,层级关系清晰可见。与SQL相比,这样的SPL代码可以大幅度降低开发成本,并极大地简化后期优化和维护工作。
相关文章:

