


SPL 的集合思维
和传统的程序设计语言不同,SPL中集合的应用非常普遍,实际上最常见的序列和序表等本质上都是集合,可以对它们进行真正的集合运算,从而大幅度提高开发效率和代码性能。因此,在使用SPL时,需要特别重视对集合概念的理解。
1 SPL中的序列与集合
SPL中,序列如同整数、字符串一样是非常常用的基本数据类型,也能进行相应的基本运算。从集合角度出发,SPL提供了两个集合A、B的交、并、联、差等基本运算符:A^B,A|B,A&B,A\B等。如果能够从这些运算开始深刻理解并熟练运用,解决问题时就能更主动地采用集合思维,从而充分利用已知的数据,思路更直接和简洁,方法也更加简易清晰。
下面的例子显示了如何利用集合运算来简化代码:
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, SURNAME, GENDER, STATE from EMPLOYEE") |
| 2 | =A1.select(GENDER=="M") |
| 3 | =A1.select(STATE=="California") |
| 4 | =A2^A3 |
| 5 | =A1.select(GENDER=="M" && STATE=="California") |
| 6 | =A2&A3 |
| 7 | =A1.select(GENDER=="M" || STATE=="California") |
| 8 | =A2\A3 |
| 9 | =A1.select(GENDER=="M" && STATE!="California") |
代码中,A4、A6、A8采用了集合运算,分别统计了California州的男员工、所有男性或者位于California州的员工、不在California州的男员工,形式上和A5、A7、A9的传统统计方式相比,明显简洁了很多。
但是,需要注意的是,A6与A7中虽然获得的员工资料一致,但结果中记录的顺序不同,如下所示:
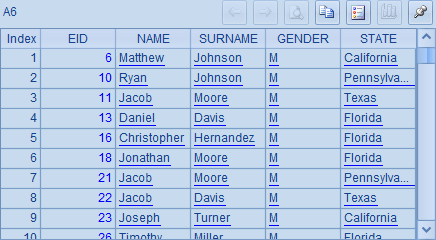
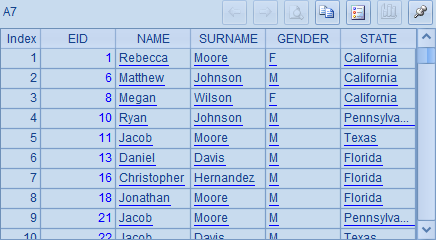
造成这种情况的原因是,与数学上的集合不完全相同,SPL中的集合称为有序集合,是有次序的,同时也可以有重复的成员。序列、序表、排列等全都是这种有序集合。
| A | |
|---|---|
| 1 | [1,2,3,4] |
| 2 | [1,3,3,2] |
| 3 | =[1,2,3]==[1,3,2] |
上表中,A2中的序列有重复的成员,而A3中两个序列中成员顺序不同,直接比较时会认为它们不相等,结果为false:

另外,数学上集合的交并运算是可交换的,即A∩BºB∩A和A∪B º B∪A,但由于SPL中的集合是有序集合,因此交换律并不成立,交并运算的结果集合将以左操作数的次序为准。
| A | |
|---|---|
| 1 | [1,2,3] |
| 2 | [3,1,5] |
| 3 | =A1^A2 |
| 4 | =A2^A1 |
| 5 | =A1&A2 |
| 6 | =A2&A1 |
A3,A4,A5和A6中的计算结果依次如下:
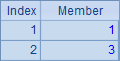
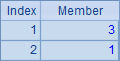
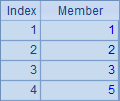
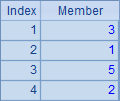
由于SPL中的序列是有序集合,因此判断两个序列是否有同样成员不能简单地用比较符==,而要用函数A.eq(B):
| A | |
|---|---|
| 1 | =[1,2,3]==[3,2,1] |
| 2 | =[1,2,3]==[3,2,1].sort() |
| 3 | =[1,2,3].eq([3,2,1]) |
| 4 | =[1,2,3].eq([3,2,2]) |
| 5 | =[1,2,2,3].eq([3,2,1,2]) |
| 6 | =[1,2,2,3].eq([3,2,3,1]) |
A1与A2中判断两个序列是否相同,结果如下:

这是因为A2中[3,2,1]执行sort函数排序后,得到的结果是[1,2,3],次序也和A1一样了。
A3、A4、A5和A6分别都使用函数A.eq(B)来判断两个序列是否有着同样的成员,结果依次如下:
如果两个序列中的所有成员全相同,则称这两个序列互为置换列。特别的,如果序列中出现了重复的成员,那么它的置换列中,这个成员也需要有同样的重复数量。
2 循环函数
有了集合数据类型,许多针对集合中成员的运算就可以方便地一句写出来,不再需要编写循环代码了。
| A | |
|---|---|
| 1 | [3,4,1,3,6] |
| 2 | =A1.sum() |
| 3 | =A1.avg() |
| 4 | =A1.max()-A1.min() |
上表用到了4个循环函数,A2中的sum()计算序列中成员的总和,A3中的avg()计算序列成员的平均值,A4中的max()和min()计算序列中最大值与最小值的差。它们的计算结果依次如下:
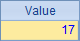

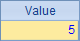
循环函数计算时不仅可以使用集合成员本身的值,而且可以使用成员计算出来的值,包括成员值的计算结果,以及具有结构的集合成员的属性值。这时可以在函数的参数中指明计算式,其中用符号~表示循环计算中的当前成员。
| A | |
|---|---|
| 1 | [3,4,1,3,6] |
| 2 | =A1.sum(~*~) |
| 3 | =demo.query("select * from EMPLOYEE") |
| 4 | =A3.min(~.BIRTHDAY) |
| 5 | =A3.min(BIRTHDAY) |
| 6 | =A3.avg(interval@y(BIRTHDAY,HIREDATE)) |
上表中的A2计算序列中成员的平方和,即循环累加每个成员值的平方,结果如下:
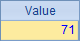
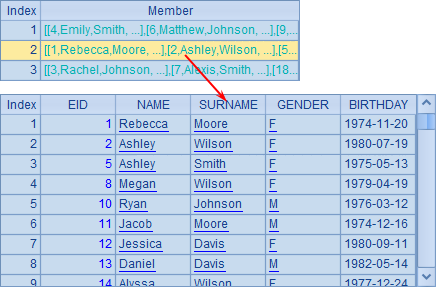
而A4、A5和A6则对A3生成的集合中的每个成员的属性值进行循环计算。A3对员工信息序表进行查询后生成集合,其中每个成员是一个员工的信息。A4中计算员工最早的生日,即成员生日的最小值,结果如下:

A4表达式中的~.可以省略,写成A5的样子,因此计算结果与A4相同。
A6中计算所有员工平均入职年龄,即每个成员入职时间和生日时间的年份差的平均值,结果如下:

执行带有参数的聚合函数可以被理解为如下两步:
1) 先根据参数表达式对集合中的每个成员进行计算,结果称为计算列
2) 再对计算列做聚合计算。
形式上可以表示为:A.f(x)=A.(x).f(),如A1.sum(~*~) 相当于A1.(~*~).sum(),其中A1.(~*~) 为计算列函数,即计算出A1中每个成员的平方,并返回为序列。
上面例子中A5、A6省略了符号~,这是因为只使用了一层循环函数,省略~不会引起歧义。如果嵌套使用循环函数,~将被解释为内层序列的成员,这时如果想引用外层序列成员,就必须在~前加上外层序列名。
| A | |
|---|---|
| 1 | [A,B,C] |
| 2 | [a,b,c] |
| 3 | =A1.(A2.(~/~)) |
| 4 | =A1.(A2.(A1.~/~)) |
| 5 | =A1.(A1.(A1.~/~)) |
| 6 | =A1.((arg=~,A1.(arg/~))) |
这个例子中用到了字符串拼接运算/。A3中,在循环中用/拼接两个字母,但只用~就只能取到内层序列A2的成员,所以得到的字串只是两个重复的小写字母。而A4在循环时指明前一个~所对应的是外层序列,因此得到的是A1大写字母在前、A2小写字母在后拼接的结果。A5的表达式中,内层循环即便用了A1.~,但无法识别究竟是哪一层的A1,因此无法引用外层A1成员,所以计算时只能使用内层序列中的成员,因此得到的结果就是重复的大写字母。这种情况下,如果需要引用外层的成员,就需要采用A6的方法,先将外层成员值赋给临时变量,再通过临时变量引用,这样就可以得到大写字母交叉拼接的结果了。A3~A6中的计算结果依次如下:

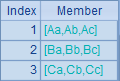
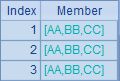

关于~的这个规则同样适用于序表或排列的循环计算,省略~的字段引用写法,字段将被优先解释为内层排列的字段,如果在内层排列找不到指定的属性字段才会再向外层找。
3 循环次序
简单地说,循环函数在计算时将按原序列的次序依次计算,而我们在使用时可以充分利用这一特点。
| A | |
|---|---|
| 1 | [1,3,2,5,4,8,7] |
| 2 | 0 |
| 3 | =A1.(A2=A2+~) |
| 4 | [1,1,0,0,1,0,0,0,1,0,1,0,0,0] |
| 5 | 0 |
| 6 | =A4.max(if(~==0,A5=A5+1,A5=0)) |
A3中,通过循环,计算出A1中成员累积和序列:
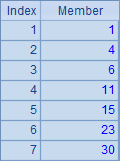
A6中,计算出序列A4中,成员0连续出现的最长个数:
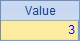
类似的情况很多,我们可以只用一个表达式就写出等同于简单循环代码的效果。
4 计算序列
除了上面这些返回单个聚合值的循环函数(如sum, avg),很多情况我们还需要继续对集合进行计算,除了采用基本的集合并、交、差等运算能够生成一个新集合外,使用计算序列函数A.(x)返回一个集合,也是很常用的方法。
| A | |
|---|---|
| 1 | [1,2,3] |
| 2 | =A1.(~*~) |
| 3 | =A1.(~) |
| 4 | =A1.() |
| 5 | =A1.(1) |
| 6 | =A1.(if(~%2==0,~,0)) |
| 7 | I love you |
| 8 | =len(A7).(mid(A7,~,1)) |
| 9 | =A8.count(~=="o") |
例子中的A2~A6根据序列A1计算,生成不同的新序列:A2计算每个成员的平方;A3与A4都是用原序列的成员生成新序列;A5循环生成和原序列数量相同的序列,但其中的成员都是1;A6略为复杂些,在循环计算对A1中的成员逐个判断,如果为奇数,则得到0,否则获得对应成员的值。A2~A6的计算结果如下:
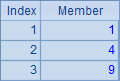
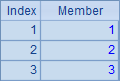
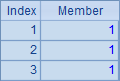
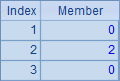
A8的完整写法是=to(len(A7)).(mid(A7,~,1)),其中to(n)函数生成一个从1到n的数字组成的新序列(熟练后和前面的符号 ~ 一样,有些情况可以省略),对这个序列进行循环,逐个取出A7中的字符串,从而展开为单字符构成的序列;A9计算出其中字母o出现的次数。A8与A9中的结果如下:

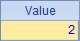
除了返回序列,我们还可以对序列计算后返回序表,这时需要用new函数。
| A | |
|---|---|
| 1 | [1,2,3,4,5] |
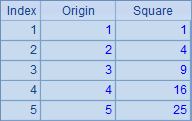
| 2 | =A1.new(~:Origin,~*~:Square) |
| 3 | =demo.query("select * from EMPLOYEE") |
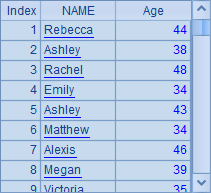
| 4 | =A3.new(NAME,age(BIRTHDAY):Age) |
| 5 | =A3.new(NAME) |
| 6 | =A3.(NAME) |
A2根据A1循环计算返回新的序表,其中包含两个字段,一个是A1中的成员,另一个则是该成员的平方值。表达式中的 ~ 前面已经介绍过了,表示当前循环到的序列成员,结果如下:
A3从数据表EMPLOYEE中取出数据产生一个序表,A4从中获取NAME和BIRTHDAY两个字段,并根据BIRTHDAY计算出该职员的年龄,形成一个新字段Age,最终生成包含了NAME和Age两个字段的新序表。结果如下:
A5和A6看上去类似,但实际上却有区别,A5从A3序表中取出NAME字段,然后直接生成包含了一个NAME字段的新序表;而A6则是根据A3中序表循环计算出由NAME字段构成的序列,两个结果的不同在于,序表有数据结构而序列无数据结构:
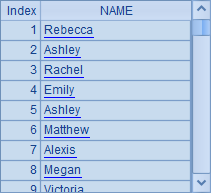
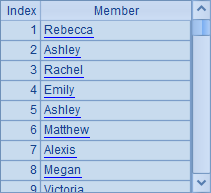
另外,还有一个仅用于计算的run函数,它直接修改原序列本身,而不是对位计算后返回新的结果序列,一般用于针对排列(序表)修改字段值。
| A | |
|---|---|
| 1 | =demo.query("select * from EMPLOYEE") |
| 2 | =A1.new(NAME,age(BIRTHDAY):Age) |
| 3 | =A2.run(Age=Age+1) |
例子中,A2中生成新序表,列出员工的名字并计算出他们的年龄。而在A3中针对新序表A2进行计算,将每位员工的年龄加1。run函数改变的是原序表A2中的数据,因此A2与A3中结果是相同的,将一同返回修改后的结果。使用分步执行可以看到A2中序表的变化:
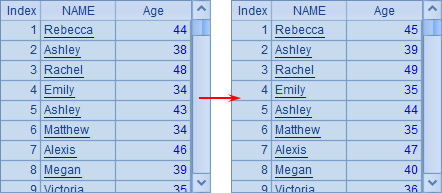
5 不纯的集合
SPL不要求序列成员的数据类型一致,因此完全可以把数值、字串以及复杂的记录作为同一个序列的成员。
| A | |
|---|---|
| 1 | [1,a3,2,5.4,$[4.5],2011-8-8] |
| 2 | =[A1,4] |
A1中包含多种数据类型的成员,而A2中的序列是由序列A1与整数成员构成的,A1与A2中的数据如下:
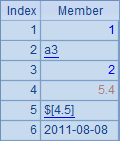
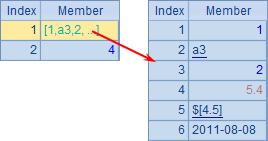
不过,对于一般的序列,在大多数情况下,将不同类型的数据置于同一序列中并没有多少实际的业务意义,因此不必过于关注。
但是,对于排列,即以记录构成的序列,允许由来自不同序表的记录构成,这一点会有实实在在的方便性。
| A | |
|---|---|
| 1 | =demo.query("select * from EMPLOYEE") |
| 2 | =demo.query("select * from FAMILY") |
| 3 | =A1|A2 |
| 4 | =A3.count(left(GENDER,1)=="F") |
A4计算员工和家属中,女性一共有多少人。即使员工表和家属表结构不同,但只要其中都包含GENDER字段,就可以正常计算。
从这个例子可以看出,SPL并不关心排列中的记录是否来自同一序表,只要它们有名称相同的字段就可以对其执行一致的操作,而不必象SQL那样必须将两个不同结构的表先用UNION语句联合成一个新表才能操作。这样不仅思路清楚、书写简单,而且不会占用多余的内存,同时运算效率更高。
6 集合的集合
特别地,集合成员的任意性还允许集合本身作为成员。同时,当A是集合的集合时,还可以进一步使用A.conj(),A.union(),A.diff(),A.isect()这些函数,计算A中各个集合的和列、并列、差列和交列。
| A | |
|---|---|
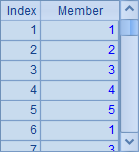
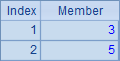
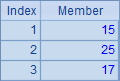
| 1 | [[1,2,3,4,5],[1,3,5,7,9],[2,3,5,7]] |
| 2 | =A1.conj() |
| 3 | =A1.isect() |
| 4 | =A1.(~.sum()) |
| 5 | =A1.(~.(~*~)) |
A1中是一个序列构成的序列。A2,A3,A4和A5分别计算A1中序列成员的和序列、交集序列、各个序列求和的结果以及各个系列每个成员的平方构成的序列。计算后,A2~A5中的结果如下:

类似的,排列也可以作为序列的成员。
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, SURNAME, GENDER, STATE from EMPLOYEE") |
| 2 | =A1.select(STATE=="California") |
| 3 | =A1.select(STATE=="Indiana") |
| 4 | =A1.select(STATE=="Florida") |
| 5 | =[A2,A3,A4] |
| 6 | =A5.(~.count()) |
| 7 | =A5.(~(1).STATE) |
| 8 | =A5.(STATE) |
| 9 | =A5.new(STATE,~.count():Count) |
A2,A3与A4中分别取出California,Indiana和Florida这3个州的员工数据。A5中获得的就是由A2~A4这3个排列构成的序列,是个集合的集合:
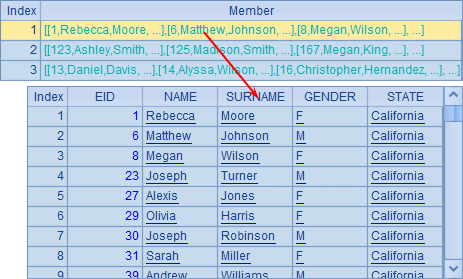
A6分别计算各州员工数,结果如下:
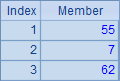
A7中取出各个州的名称,表达式中的~(1)是可以省略的,也就是说A8与A7是等价的,结果也一样:
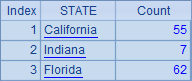
A9效果看上去和A6一样,也是统计3个州的员工数,但通过new生成了一个新的序表,看上去更加清晰,也方便以后根据州名检索使用::
7 理解分组
分组是SQL中很常用的运算,但未必所有人都能深刻理解它。
从集合的角度看,分组运算的实质是将一个集合按某种规则拆分成若干子集,也就是说,其返回值应当是若干个集合构成的集合。只不过人们经常不需要直接察看集合中的这些子集,而是对子集的某些汇总值更感兴趣,因此,分组常常伴随着对子集的进一步汇总计算。
SQL正是这样处理的,它的GROUP BY语句总是配合相应的汇总计算。当然,这也是因为SQL自身没有显式的集合数据类型,所以无法直接返回“集合的集合”这类数据,只能把汇总计算强加到分组计算之后。
久而久之,人们习惯了分组总是需要配合后续的汇总计算,而忘记了分组和汇总其实是两个独立的步骤。
但是无论如何,我们仍然会有对这些分组子集感兴趣的时候。而且退一步讲,即使只对汇总值有兴趣,保持住这些子集也有价值,因为如果可以重复利用,不必每次都重新生成,那么无论在代码的简洁还是性能的提升方面都会有很大的帮助。
而对于SPL来说,因为它充分实现了集合思维,所以就能够做到还原分组运算的本意。事实上,SPL中的基本分组函数就是只做纯粹的分组,而把汇总计算剥离出去了。
| A | B | |
|---|---|---|
| 1 | =demo.query("select * from EMPLOYEE") | |
| 2 | =A1.group(month(BIRTHDAY),day(BIRTHDAY)) | /将员工按生日(月、日)分组 |
| 3 | =A2.select(~.len()>1) | /有其他人生日与之相同的员工 |
| 4 | =A3.conj() | |
| 5 | =A1.group(STATE) | /将员工按所在州分组 |
| 6 | =A5.new(~(1).STATE:State,~.count():Count) | /用分组结果计算序表,各州员工数 |
| 7 | =A5.new(STATE,~.avg(age(BIRTHDAY)):Age) | /计算序表,各州员工平均年龄 |
分组的结果本身是一个集合的集合,因此当然还可以继续分组。而分组结果集合中的各个成员也是集合,各自也能够再继续分组。这是两种不同的操作,但都会形成多层集合。
| A | B | |
|---|---|---|
| 1 | =demo.query("select * from EMPLOYEE") | |
| 2 | =A1.group(year(BIRTHDAY)) | /按员工出生年份分组 |
| 3 | =A2.group(int(year(~(1).BIRTHDAY)%100/10)) | |
| 4 | =A2.group(int(year(BIRTHDAY)%100/10)) | |
| 5 | =A2.(~.group(month(BIRTHDAY))) | /把分组后的结果再次分组,A3、A4、A5都将返回排列的序列 |
如果集合运算结果的层次太深,那么现实的业务含义可能不是很大,但可以用来体会集合的思维方式及运算的实质。
在分组的同时,group函数会同时将各个组按照分组表达式的结果排序,如:
| A | B | |
|---|---|---|
| 1 | $ select EID,NAME+' '+SURNAME FULLNAME, DEPT from EMPLOYEE | |
| 2 | =A1.group(DEPT) | =A2.new(~.DEPT:DEPT,~.count():Count) |
| 3 | =A2.sort(~.DEPT:-1) | =A3.new(~.DEPT:DEPT,~.count():Count) |
| 4 | =A1.group@u(DEPT) | =A4.new(~.DEPT:DEPT,~.count():Count) |
| 5 | =A1.group@o(DEPT) | =A5.new(~.DEPT:DEPT,~.count():Count) |
A1中得到的序表如下:
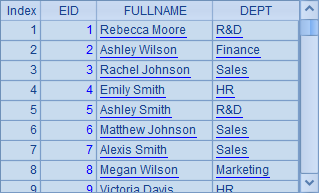
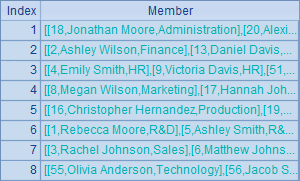
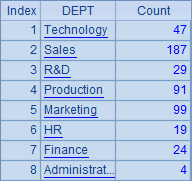
A2中按部门名称将员工数据分组,默认情况下,A2中的分组结果就会按照部门名称升序排序。在B列中统计了各种分组情况下各部门的人数,以便通过DEPT列直接查看排序情况。A2和B2中结果如下:
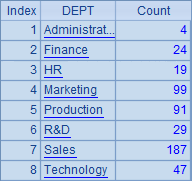
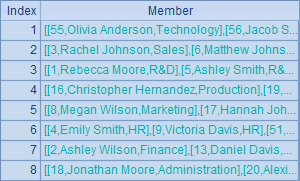
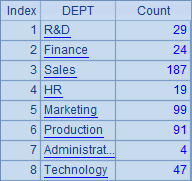
A3将A2中的分组结果改为按照部门降序排序,效果可以在B3中看到,结果如下:
除了将分组结果重新排序,还可以在执行group时添加选项来调整分组顺序。
A4中添加通过@u选项在分组时保持各部门在员工表中出现的原始顺序。
A5中添加的@o选项指定分组时不对记录做整体排序,而只会将分组表达式相等的相邻记录分为一组,因此更像是“相邻合并”。显然,这种情况可能会出现的“重复”分组。B4和B5显示了这两种情况的效果:
8 非等值分组
除了常规的group函数,SPL还提供了处理对齐分组的A.align@a()函数和处理枚举分组的A.enum()函数。
我们称通过group函数完成的分组为等值分组,它具有这样的特点:
1) 原集合中任何成员都必须在且只能在某一个子集中,也就是分组后的子集成员完全覆盖原集合,并且子集之间没有重叠;
2) 没有空子集
而对齐分组和枚举分组则不一定满足这两点。
对齐分组是指,用集合中成员计算分组表达式,根据计算结果与事先指定的一个序列中的值一一对应,完成分组。对齐分组需要如下几步:
1) 事先指定一组值
2) 将待分组集合中某个表达式计算结果和指定值相同的成员划分到同一个子集
3) 结果的每个子集将和事先指定的值一一对应。
在这种分组规则下,可能有某个成员不在任何一个子集中,也可能出现空集,或者某成员在两个子集中都存在。
如下面的例子,将员工按指定的州序列分组:
| A | |
|---|---|
| 1 | =demo.query("select * from EMPLOYEE") |
| 2 | [California,Florida,Chicago] |
| 3 | =A1.align@a(A2,STATE) |
在A3中,将集合A1根据A2对齐分组,将A1成员的州名称与A2的成员做对应。在这样的分组过程中,有可能有些员工不在任何一个分组中(其他州的员工),也有可能出现没有任何成员的空组(Chicago不是州名称,根本没有对应的员工)。例如,在某种数据情况下,A3结果:

枚举分组是指,事先指定一组条件,将待分组集合中成员作为参数计算该条件,条件成立者将被划分到对应的子集。这时也可能有某个成员不在任何一个子集中,以及出现空集,还可能有成员同时在两个子集中。
如下面的例子,将员工按照指定的年龄段分组:
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, SURNAME, GENDER, BIRTHDAY from EMPLOYEE") |
| 2 | [?<=35,? <=45,?>45] |
| 3 | =A1.enum(A2,age(BIRTHDAY)) |
| 4 | [?<=35,?>20 && ?<=45,?>45] |
| 5 | =A1.enum@r(A4,age(BIRTHDAY)) |
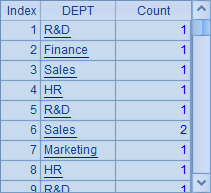
A3中,根据A2中的年龄条件序列进行枚举分组。enum()函数不指定选项时,不允许分组结果出现重复,也就是说A1中某个员工的记录可以不在任何分组中(不过例子中的条件是全覆盖的),但是不会同时出现在两个分组中(也就是不会重叠)。A3结果如下:
此时,某个年轻的(35岁以下)员工会被分配到第1个分组中。而由于不允许重叠,因此即便他也满足第二个条件,45岁以下,仍不会再被重复分配到第2组中。
A5也是根据A4中的条件序列进行枚举分组,不过这里使用enum函数时添加了@r选项,表示分组时可重复。此时,某个员工的记录有可能同时出现在多个分组中了。例如:
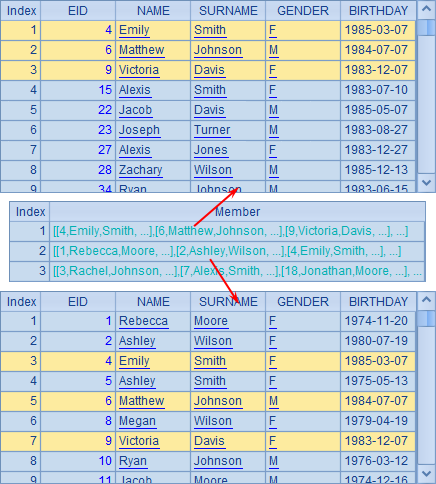
可以看到,某些员工记录会同时存在于前两个分组中。
align@a函数和enum函数虽然看起来和group函数相差很大,不过在理解了分组运算的本质后,就能明白它们其实都是在做同一件事:即把一个集合拆分成若干个子集,所不同的只是拆分的具体条件和规则不同罢了。


英文版