


esProc vs python 5
1. 列出分期贷款明细
题目介绍:loan 表存储着贷款信息,包括贷款 ID,贷款总额、按月分期数、年利率。数据如下:
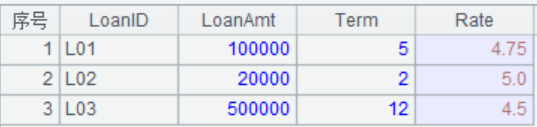
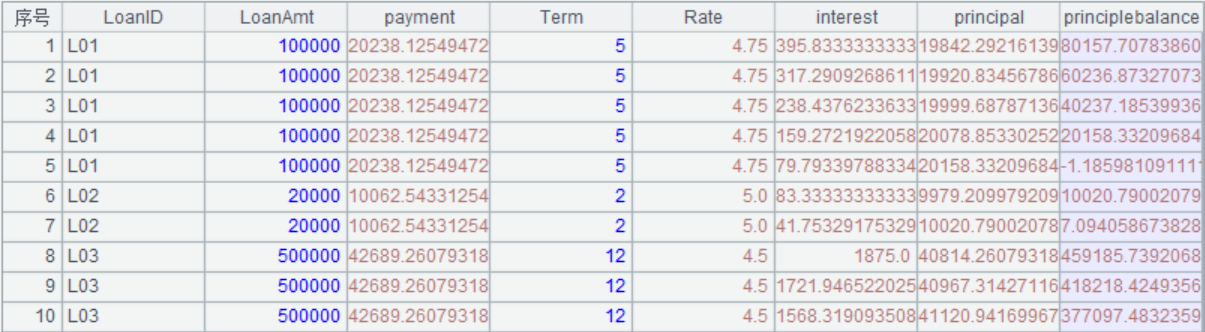
我们的目的是列出各期明细,包括:当期还款额、当期利息、当期本金、剩余本金。
esProc
A |
|
1 |
=now() |
2 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\loan.csv").import@t() |
3 |
=A2.derive(Rate/100/12:mRate,LoanAmt*mRate*power((1+mRate),Term)/(power((1+mRate),Term)-1):mPayment) |
4 |
=A3.news((t=LoanAmt,Term);LoanID, LoanAmt, mPayment:payment, Term, Rate, t* mRate:interest, payment-interest:principal, t=t-principal:principlebalance) |
5 |
=interval@ms(A1,now()) |
A3:T.derive()新增两列月利率mRate=年利率/12,每期还款数mPayment=总利息/((1+月利率)的期数次幂)-1
A4:A.news(X;xi:Fi,…),根据序表/排列A,计算排列X后把计算后的字段合并到一个新的序表/排列,Fi为新字段名,xi为计算结果,Fi省略自动识别。当参数xi使用#i时,表示第i列,此时使用原列名。这里解释一下,将t的初始值设置为A3中的LoanAmt的值作为初始的本金,然后建立新表,其中利息interest=本金*月利率mRate,当期偿还的本金principal等于每期还款数payment-利息,剩余的本金=本金t-当期偿还的本金,然后把剩余的本金更新到t作为下一期的本金。
python:
import time
import numpy as np
import pandas as pd
s = time.time()
loan_data = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\loan.csv',sep='\t')
loan_data['mrate'] = loan_data['Rate']/(100*12)
loan_data['mpayment'] = loan_data['LoanAmt']*loan_data['mrate']*np.power(1+loan_data['mrate'],loan_data['Term']) \
/(np.power(1+loan_data['mrate'],loan_data['Term'])-1)
loan_term_list = []
for i in range(len(loan_data)):
loanid = np.tile(loan_data.loc[i]['LoanID'],loan_data.loc[i]['Term'])
loanid = np.tile(loan_data.loc[i]['LoanID'],loan_data.loc[i]['Term'])
loanamt = np.tile(loan_data.loc[i]['LoanAmt'],loan_data.loc[i]['Term'])
term = np.tile(loan_data.loc[i]['Term'],loan_data.loc[i]['Term'])
rate = np.tile(loan_data.loc[i]['Rate'],loan_data.loc[i]['Term'])
payment = np.tile(np.array(loan_data.loc[i]['mpayment']),loan_data.loc[i]['Term'])
interest = np.zeros(len(loanamt))
principal = np.zeros(len(loanamt))
principalbalance = np.zeros(len(loanamt))
loan_amt = loanamt[0]
for j in range(len(loanamt)):
interest[j] = loan_amt*loan_data.loc[i]['mrate']
principal[j] = payment[j] - interest[j]
principalbalance[j] = loan_amt - principal[j]
loan_amt = principalbalance[j]
loan_data_df = pd.DataFrame(np.transpose(np.array([loanid,loanamt,term,rate,payment,interest,principal,principalbalance])),
columns = ['loanid','loanamt','term','rate','payment','interest','principal','principalbalance'])
loan_term_list.append(loan_data_df)
loan_term_pay = pd.concat(loan_term_list,ignore_index=True)
print(loan_term_pay)
e = time.time()
print(e-s)
新增两列mrate和mpayment,mpayment的计算方法和esProc的一样,大家可以参考。
初始化一个空列表用于存放每一个贷款客户的数据。
循环数据
Df.loc[i][x]取索引为i字段名为x的数据,tile(a,x),x是控制a重复几次的,结果是一个一维数组。
同样的方法获得贷款的'loanid','loanamt','term','rate','payment'的字段值,
初始化一个本金为loanamt的第一个元素。
for循环就是计算['interest','principal','principalbalance']这三个字段值的方法,思路和esProc的思路一样,只不过esProc支持动态计算而python只能通过构造这个for循环来完成。
Np.array()将list格式的列表转换成数组。由于这里的行表示的是每一个字段的值,np.transpose(a)是将数组a转置。pd.DataFrame()转成dataframe结构。
pd.concat()将每个贷款的分期信息合并成一个dataframe。
结果:
esProc
python

耗时 |
|
esProc |
0.005 |
python |
0.034 |
2.不规则月份统计
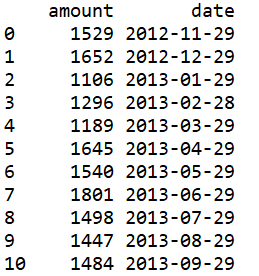
题目介绍:如果起始时间是 2014-01-10,则将 2014-01-10 到 2014-02-09 作为一组,将 2014-02-10 到 2014-03-9 作为一组。如果起始时间是 2014-01-31,则将 2014-02-27 作为一组,将 2014-02-28 到 2014-03-30 作为一组。数据如下:

我们的目的是统计出不规则月份的销售额AMOUNT。
esProc
A |
|
1 |
=now() |
2 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\order_date.csv").import@t() |
3 |
=A2.select(date(date)>=startDate&&date(date)<=endDate) |
4 |
=interval@m(startDate,endDate) |
5 |
=startDate|A4.(after@m(startDate,~)) |
6 |
=A3.group(A5.pseg(date):ID;~.sum(AMOUNT):amount,A5(#):date) |
7 |
=interval@ms(A1,now()) |
我们首先需要设置网格参数startDate,endDate(程序——网格参数)
A3:筛选出指定时间的时间段
A4:按月计算开始时间和起始时间的间隔
A5:after(start,n)计算从开始时间以后的n天,@m选项表示按月计算,即开始时间以后的n个月。根据起始时间和日期间隔算出不规则月份的开始日期,并将起始时间插入第1位。
A6: A.pseg(x),返回x在A中的哪一段,缺省序列成员组成左闭右开的区间,A必须为有序序列。 x非A成员时,如果序列升序时x小于序列成员最小值(或序列降序时x大于序列成员最大值)则返回0;如果序列升序时x大于等于序列成员最大值(或序列降序时x小于等于序列成员最小值)则返回序列长度。将日期所在分组作为ID,销售额之和作为amount字段,当前日期作为date字段,形成序表。
python:
import time
import pandas as pd
import numpy as np
import datetime
s = time.time()
starttime_s = '2012-11-29'
endtime_s = '2013-11-11'
starttime = datetime.datetime.strptime(starttime_s, '%Y-%m-%d')
endtime = datetime.datetime.strptime(endtime_s, '%Y-%m-%d')
orders = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\order_date.csv',sep='\t')
orders['date'] = pd.to_datetime(orders['date'])
orders=orders[orders['date']>=starttime]
orders=orders[orders['date']<=endtime]
date_index = pd.date_range(start = starttime,end=endtime,freq='M')
interv = date_index.day
date_list = []
date_amount = []
for i in range(len(interv)):
if starttime>=date_index[i]:
date_list.append(date_index[i])
else:
date_list.append(starttime)
starttime = starttime + datetime.timedelta(days=int(interv[i]))
if len(date_list)>1:
by = orders['date'].apply(lambda x:date_list[i]>x>=date_list[i-1])
date_amount.append([orders[by]['AMOUNT'].sum(),date_list[i-1]])
by = orders['date'].apply(lambda x:x>=date_list[i])
date_amount.append([orders[by]['AMOUNT'].sum(),date_list[i]])
date_amount_df = pd.DataFrame(date_amount,columns=['amount','date'])
print(date_amount_df)
date_df = pd.Series(date_list)
e = time.time()
print(e-s)
小编没有找到pandas中自动生成不规则月份的方法,所以是自己写的,如果各位谁知道这种方法,还请不吝赐教。
指定起始时间和终止时间
datetime.datetime.strptime(str, '%Y-%m-%d')将字符串的日期格式转换为日期格式
pd.to_datetime()将date列转换成日期格式
筛选出指定时间段的数据
pd.date_range(start,end,freq)从开始时间到结束时间以freq的间隔生成时间序列,这里是按月生成。(这里作出说明,生成的序列成员是每个月的最后一天的日期)
date_index.day生成了这个序列中所有月份的天数
初始化两个list,date_list用来存放不规则日期的起始时间,date_amount用来存放各个时间段内的销售额和时间
循环月份总成的天数,如果起始时间晚于这个月的最后一天,则把这个月的最后一天放入date_list,否则把起始时间放入,然后更新起始时间为起始时间推迟该月的天数后的日期。
如果date_list中的日期数量大于1了,生成一个数组(判断数据中每个日期是否在该段时间段内,在为True,否则为False)。
筛选出在该时间段内数据中的销售额AMOUNT字段,求其和,并将其和日期放入初始化的date_amount列表中。
pd.DataFrame()生成结果
结果:
esProc

python
耗时 |
|
esProc |
0.003 |
python |
0.039 |
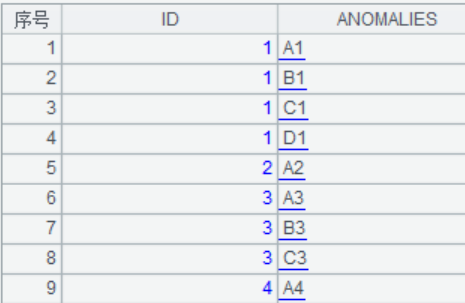
3.字段分段
题目介绍:库表data有两个字段,ID和ANOMOALIES,数据如下:
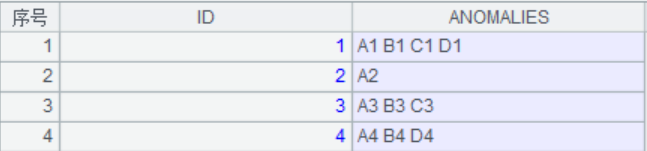
我们的目的是将ANOMOALIES字段按空格拆分为多个字符串,每个字符串和原ID字段形成新的记录。
esProc
A |
|
1 |
=now() |
2 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\split_field.csv").import@t() |
3 |
=A2.news(ANOMALIES.split(" ");ID,~:ANOMALIES) |
4 |
=interval@ms(A1,now()) |
A4:news函数的用法在第一例中已经解释过,这里不再赘述。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
split_field = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\split_field.csv',sep='\t')
split_dict = split_field.set_index('ID').T.to_dict('list')
split_list = []
for key,value in split_dict.items():
anomalies = value[0].split(' ')
key_array = np.tile(key,len(anomalies))
split_df = pd.DataFrame(np.array([key_array,anomalies]).T,columns=['ID','ANOMALIES'])
#split_df = pd.DataFrame(np.transpose(np.array([key_array,anomalies])),columns=['ID','ANOMALIES'])
split_list.append(split_df)
split_field = pd.concat(split_list,ignore_index=True)
print(split_field)
e = time.time()
print(e-s)
df.set_index(F)设置索引为F,df.T,将df的行列转置,df.to_dict(‘list’)将dataframe转换成字典,字段的key为df的字段名,value为df的字段值形成的list。
初始化一个空list,用于存放每个ANOMALIES字段拆分以后的dataframe
循环字典
将value的第一个元素按照空格切分,形成一个列表anomalies
根据这个列表长度复制key的值,形成数组key_array
将np.array([key_array,anomalies])将他们转换成数组,array.T,将数组转置(转置也可以用注释掉的那行代码np.traspose()函数),然后由pd.DataFrame()转成dataframe。
最后连接dataframe,得到结果。
结果:
esProc
python

耗时 |
|
esProc |
0.002 |
python |
0.013 |
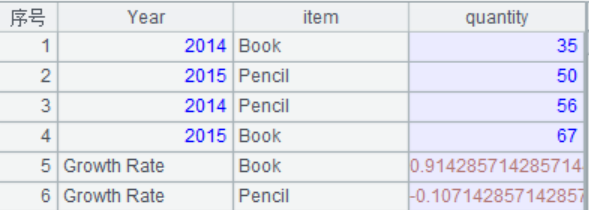
4.增加增长率记录
esProc
A |
|
1 |
=now() |
2 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\store_quantity.csv").import@t() |
3 |
=A2.sort(Year).group(item).run(A2.record(["Growth Rate",item,~(2).quantity/~(1).quantity-1])) |
4 |
=interval@ms(A1,now()) |
A4:T.sort(x),按照x表达式排序,T.group(x)按照x表达式分组。A.run(x),针对序列/排列A中每个成员计算表达式x。T.record(A,k) 从T中指定位置k的记录开始,用A的成员依次修改T序表中记录的每个字段值,k省略时从最后一条开始增加记录。~表示当前分组,~(2)表示第二条记录即2015年的记录,~(1)表示2014年的记录。这里的过程是先按照Year字段排序,然后按照item分组,然后新增两条记录,分别是各种物品的增长率。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
store_q = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\store_quantity.csv',sep='\t')
store_q.sort_values(by='Year',inplace = True)
store_q_g = store_q.groupby(by='item',as_index=False)
growth_rate_list=[]
for index,group in store_q_g:
growth_rate = group['quantity']/group['quantity'].shift(1)-1
growth_rate_list.append(['growth_rate',index,growth_rate.values[1]])
store_rate = pd.concat([store_q,pd.DataFrame(growth_rate_list,columns=['Year','item','quantity'])])
print(store_rate)
e = time.time()
print(e-s)
df.sort_values(by,inplace),按照Year字段排序,更新到元数据中
df.groupby(by, as_index),按照item分组,不把item作为索引
初始化一个list用来存放各组的结果
循环分组,df.shift(1)是将df下移一行,(当前行/上一行)-1得到增长率。
由于只有两年的记录所以增长率的第二个元素即为需要的增长率。将growth_rate,index,增长率放入初始化的list中
pd.Dataframe()和pd.concat()大家应该很熟了,这里不再赘述了。
结果:
esProc
python
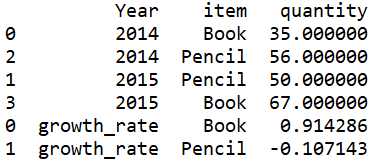
耗时 |
|
esProc |
0.001 |
python |
0.014 |
5.合并重复记录
题目介绍:该数据没有字段,第一行就是数据,数据如下:

我们的目的是过滤掉重复的记录,取出前6列,并重整第7,8两列,具体要求是:将wrok phone作为新文件第7列,将work email作为新文件第8列,如果有多个work phone或work email,则只取第一个。
esProc
A |
|
1 |
=now() |
2 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\merge_duplicate.csv").import@c() |
3 |
=A2.group(_1,_2:,_3,_4,_5,_6;~.select@1(_7=="work phone")._8:work_phone,~.select@1(_7=="work email")._8:work_email) |
4 |
=interval@ms(A1,now()) |
A2:这里解释下f.import(),导入数据,@t是要把第一列作为字段名,@c是按照逗号分隔。
A3:按照_1,_2,_3,_4,_5,_6分组,每组选择一条记录select@1()是取序列中第一条符合条件的成员,如果第7个字段是work phone则取第八个字段的值作为work_phone字段,如果分组中第7个字段是work email则取第八个字段作为work_email字段。
python:
import time
import pandas as pd
import numpy as np
s = time.time()
merge_dup = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\music_project_data\\merge_duplicate.csv',header=None)
merge_dup_g = merge_dup.groupby(by=[0,1,2,3,4,5],as_index=False)
work_arr = np.zeros(len(merge_dup.columns))
work_list = []
for index,group in merge_dup_g:
work_arr = group.iloc[0].values
work_arr[6] = work_arr[7]
work_arr[7] = group[group[6]=='work email'].iloc[0].values[7]
work_list.append(work_arr)
merge_dup = pd.DataFrame(work_list,columns=merge_dup.columns)
merge_dup.rename(columns={6:'work_phone',7:'work_email'},inplace=True)
print(merge_dup)
e = time.time()
print(e-s)
按照前6个字段进行分组
因为题目要求我们把work phone 和work email拿出来作为字段,所以源数据的字段数没变,df.columns得到df的字段名,np.zeros()初始化一个数组。
循环分组
取分组中第6个字段等于work phone的第一行的值,赋值给初始化的数组
修改数组第7个元素(索引是6)为数组的第8个元素(索引是7)
取分组中第6个字段等于work email的第一行的值的第8个元素(索引是7),赋值给数组的第8个元素(索引是7)。
将结果放入初始化的list中
转换成dataframe。
df.rename(columns,inplace)修改字段名,更新到源数据上。
结果:
esProc

python

耗时 |
|
esProc |
0.002 |
python |
0.022 |
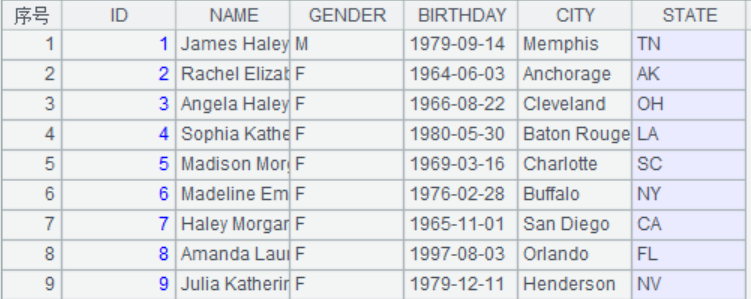
6. 准备测试数据
esProc
A |
|
1 |
=now() |
2 |
1000 |
3 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\M_name.txt").import@t() |
4 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\F_name.txt").import@t() |
5 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\S_name.txt").import@t() |
6 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\cities.txt").import@t() |
7 |
=file("C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\states.txt").import@t() |
8 |
=A3.derive("M":GENDER) |
9 |
=A4.derive("F":GENDER) |
10 |
=A8|A9 |
11 |
=A6.derive(A7.select@1(STATEID==A6.STATEID).ABBR:ABBR) |
12 |
=A10.((A5.new(A10.NAME+" "+S_name:NAME,A10.GENDER:GENDER))).conj().sort(rand()) |
13 |
=A2.new(#:ID,A12(#).NAME:NAME,A12(#).GENDER:GENDER,elapse((birthday=date(year(now())-(18+rand(38)),1,1)),rand(days@y(birthday))):BIRTHDAY,(city=A11(rand(A11.len())+1)).NAME:CITY,city.ABBR:STATE) |
14 |
=interval@ms(A1,now()) |
A2: 定义一个数字,用来确定创建多少员工信息,这里准备的数据比较少,感兴趣的同学可以多准备些,这里是男员工名字45,女员工名字47,姓47,所以最多可以创建(45+47)*47=4324条员工信息,因此这个数字不能大于4324。
A8:男员工名字新增一个字段GENDER,赋值M
A10:合并男女员工的姓名
A11:根据STATEID为city表增加state表中的ABBR字段并设置成city表的ABBR字段
A12:按照A10表合并姓名和姓。A.conj()将序列和列。得到(45+47)*47个姓名和GENDER,sort(rand())将表随机排列,这是相对于news()的另一种写法,感兴趣的同学可以尝试改写成news()的写法。
A13:新建表,定义两个变量,birthday:18+rand(18),表示年龄在18至35周岁,用今年的年份减去年龄,得到出生的年份的一月一日。city:从city表中随机选取一条记录。定义变量是可以在计算的时候定义的,计算完成后赋值给变量,后续的计算可以直接使用这个变量,这使表达式显得简洁。最终的BIRTHDAY字段为从那年的1月1日,随机推迟那年的天数的时间,得到生日。city去city表的NAME字段,STATE去city表的ABBR字段。
python:
import time
import pandas as pd
import numpy as np
import datetime
import random
s = time.time()
data_quantity = 1000
m_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\M_name.txt',sep='\t')
f_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\F_name.txt',sep='\t')
s_name = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\S_name.txt',sep='\t')
cities = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\cities.txt',sep='\t')
states = pd.read_csv('C:\\Users\\Sean\\Desktop\\kaggle_data\\prepare_data\\states.txt',sep='\t')
m_name['GENDER'] = 'M'
f_name['GENDER'] = 'F'
name = pd.concat([m_name,f_name])
name['FULL_NAME']=1
s_name['FULL_NAME']=1
name = pd.merge(name,s_name,on='FULL_NAME')
name['FULL_NAME']=name['NAME']+' '+name['S_name']
city_state = pd.merge(cities[['NAME','STATEID']],states[['ABBR','STATEID']],on='STATEID')
birth_list = []
city_list = []
state_list = []
for i in range(data_quantity):
age = random.randint(18,35)
birth_y = datetime.datetime.today().year-age
birthday = datetime.datetime(birth_y,1,1).date()
year_days = int(datetime.date(birth_y,12,31).strftime('%j'))
birthday = birthday + datetime.timedelta(days=random.randint(0,year_days))
birth_list.append(birthday)
rand_index = random.randint(0,len(city_state)-1)
city_list.append(city_state['NAME'].loc[rand_index])
state_list.append(city_state['ABBR'].loc[rand_index])
rand_arr = np.random.randint(0,len(name),data_quantity)
person = name[['FULL_NAME','GENDER']].loc[rand_arr]
person['ID']=np.arange(data_quantity)
person['BIRTHDAY'] = birth_list
person['CITY'] = city_list
person['STATE'] = state_list
person = person.rename(columns={'FULL_NAME':'NAME'}).reset_index(drop=True)
print(person[['ID','NAME','GENDER','BIRTHDAY','CITY','STATE']])
e = time.time()
print(e-s)
新增字段,纵向和横向合并dataframe,我们在前边的例子已经多次用到了,这里不再赘述
简单解释一下姓名合并的问题,由于两个dataframe没有共同的字段作为key,所以我们造了一个字段FULL_NAME,赋值为1,只为进行merge。
定义三个list,分别用来生成BIRTHDAY,CITY,STATE列
把年龄定义在18-35之间,由年龄生成随机的生日,然后放入定义好的list中
CITY和STATE字段的值是利用loc[]函数,随机取,并放入定义好的list中
定义一个数组,随机生成name数据的索引
通过loc[rand_arr]函数,取随机的1000个,生成FULL_NAME和GENDER字段。
np.arange(n)生成n个元素的一维数组,作为ID字段。
然后把刚才的三个list赋值给BIRTHDAY,CITY,STATE。
rename()将FULL_NAME字段名改为NAME,重新设置索引并将原来的索引丢弃。
生成最终结果。
结果:
esProc
python

耗时 |
|
esProc |
0.018 |
python |
0.184 |
小结:本节我们继续计算一些网上常见的题目,由于pandas依赖于另一个第三方库numpy,而numpy的数组元素只能通过循环一步一步进行更新,esProc的循环函数如new()、select()等都可以动态更新字段值,使得代码简单。在第二例中,日期处理时,esProc可以很轻松的划分出不规则的月份,并根据不规则月份进行计算。而python划分不规则月份时需要额外依赖datetime库,还要自行根据月份天数划分,实在是有些麻烦。


👍