


中国报表漫谈
按:在敏捷 BI 横行的年代,报表这个概念也有了更大的外延,很多用户甚至技术人员都会将由复杂格式报表与 BI 系统中拖拽出来的报表混为一谈。这是一篇 2004 年底写的老文,现在重读,对于理解复杂报表仍有意义,不过对于相关工具的评说确实有些过时了,但也不做修改了,简单修订一下重发

这两年来雨后春笋般地冒出二三十家做报表工具的公司,统统号称能处理中国式报表,大概是这中国报表复杂得都世界闻名了,但凡能搞得定中国的报表,那也就没什么搞不定的报表了。弄到后来有好些所谓的报表只要能在格子里摆条斜线就敢说能对付中国报表(这也太小瞧祖国文化了),而且老外也开始扬言适合于中国报表了,这时髦,不赶怕是不行了。
可话说回来,这中国的报表确实够复杂、巨费劲。用户拿出一撂纸往咱面前一堆:“就照这个做吧”,立马头就晕了,随便选一张搞个两三天是家常便饭,运气坏了折腾一礼拜也不是多罕见的事,手里握着世界排名前三的高档武器(这里不方便点名批评,大家心领神会吧)依然搞得人垂头丧气,末了还是得拿出看家工夫——写代码!谁让咱是程序员呢,就这命呗。
那到底啥才算是中国式报表?中国的报表到底复杂在哪里?号称能对付中国报表的工具到底灵不灵?中国人是不是吃错了什么药非要把报表搞这么费劲?
我们就来胡乱聊聊中国报表的这些闲事。
我们先来研究一下中国报表的特点和当前报表工具的问题。
先从样子上看,中国人的报表好象很少有没有格线的,不仅有格线,还恨不得搞它三五层,大格套小格,更不要说大伙津津乐道的斜线了。可人家老外的报表真地很少有线哟,就那么几个数对得倒也整齐。不过,老外的表层数不多,不容易看花眼,中国的表头比较乱,没有格线容易看走眼的,所以格线确实是非常必要的。
格线既然是为了令数据对齐的,那线本身更是应当横平竖直、一贯到底,小学生画表都是拿尺子比着,一气画老长一条。可老外的武器中却没顺便带上尺子,只是把一些数连同其框框摆来摆去,美其名曰拖拽,号称只要用鼠标简单拖拽就可画出报表。
这么一来,一条长线就要靠十几个甚至几十个小框框拼出来了,一个挨一个。哎,本来一笔就画得出来的线,要堆上几十段,你说烦不烦?单层的还可说,偏偏我国人民喜欢一层套一层,这样就得上下左右全面对齐,这么多小框框指不定哪个不太老实偏出去一点点,直线就变阶梯,中国报表还经常特宽,搞得顾了左顾不了右,哪天用户心血来潮要加减几个框框,那可累死人了(用户反正不干活,眼不见心不烦),而且这种纯粹的机械劳动叫我等来搞,真有愧于国家多年的栽培,此时那三字经是不由得要脱口而出的。这还没算完,辛辛苦苦画整齐的表,怎么打印到纸上又不齐了,敢情这东西还和分辨率相关,哎,这打印机何苦要比屏幕分辨率高这许多。
这种所谓先进的“拖拽式”其实可以用来画任何东西,是一个一般性的图元编辑器模型,半点也没有体现出表格的规律性,什么都能画,可什么画起来都不大方便。
老外的不行,国人造的如何?可惜,绝大多数国货都在抄老外,谁叫人家发达呢,咱也分不清好不好,都给抄来了。
难道就没什么可使的兵器了?有!当然有,光是摆样子又没多难,人家老外也有这种兵器,而且好使得很。
那就是大名鼎鼎的 EXCEL 了。EXCEL 采用网格线把格子围出来的画法,配合以合并格和边框,好比给大家配上了尺子,这下爽了,一个看似复杂的表格三下五除二就搞定了。EXCEL 的画法充分体现了表格的规律性,所以特别方便,方便得连用户自己都会搞了。
这下又坏事了,用户太喜欢 EXCEL 了,于是要求所有报表都要能生成 EXCEL 的格式,更有甚者,以后不再给咱一撂纸了,给咱一批 EXCEL 文件,扬言要咱直接读进去,省得再画。
这可更苦了用老外工具(或抄老外的国货)的人,拖拽式和 EXCEL 的搞法完全不同,定要生成 EXCEL 文件的话,大都会丧失格式(国货大抵如此),个别使了大劲的可以搞得很象(老外的一般有这个本事),又还是依赖于您的对齐工夫,稍有不慎,嘿嘿,一行变 N 行。至于读入 EXCEL 文件,那更是想都别想,还不如打到纸上再对着描着舒坦呢。
那咱干脆直接就用 EXCEL 好了,不用这些罗里巴索的工具了。哎,这还是有点不大行,EXCEL 的格式上是顶呱呱没得说,可没什么数据汇总方案,基本上没法从数据库中读出数据自动产生报表,这毕竟是咱用报表工具的主要目的,否则又得编程序往格子里填数据。
刚才说了,绝大多数国货在抄那种“拖拽式”的老外,那剩下的小部分就在抄 EXCEL 了,同样抄得倍儿象,没什么数据汇总功能,只能画画样子,也还是没法用。
不过,也真有被这可恶的“拖拽式”折磨过头的,自已编程去准备数填入 EXCEL(或类似产品)。这现象其实也还得怪这些报表工具不争气,不仅画起来费劲,统计汇总的本事也就比 EXCEL 强一点点,离中国报表的要求差得远。这就是我们要谈的第二个方面,也是中国报表真正最复杂的地方。堆框框虽费劲,可有道是只要功夫深,铁杵磨成针,但统计汇总本事不行的话那就没治了,无论功夫有多深,木杵总也磨不成针。
数据统计方面的问题要比报表样式的问题多得多,也严重得多,要分几个方面来研讨。这些研讨主要且只能针对拖拽式的报表工具进行,毕竟这些东西还算有点自动化本事。
中国报表统计方面第一个重要特征是多数据源。
所谓多数据源是指同一张报表的数据会来自多个不同的数据表或视图,甚至来自多个不同的异构数据库!这东西空口说有点费劲,咱上俩例子。
1)人员信息表
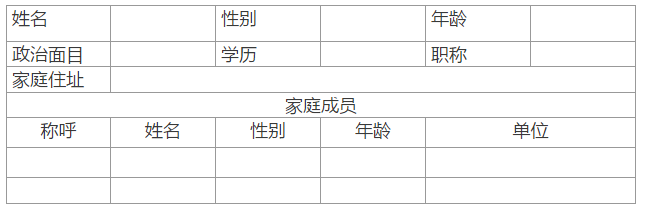
没有特殊情况下,智商正常或以上的人都会在数据库中设计两张数据表来保存这个表格中的数据,那么这张表格的数据就会同时来自这两个表。
2) 成本销售表
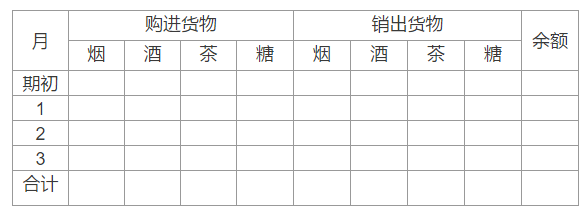
一般为了业务系统处理方便,购进和销出信息在数据库中也会是两个数据表,这张报表中不仅有两组来源不同的数据,而且之间还要运算(余额)。
可惜,不知怎么搞的,这些老外和抄老外的武器全都是单数据源的。不论你的数据来源(SQL 语句或存储过程)搞得多复杂,到了报表这一端都必须变成单个的二维表了。
那这些工具是咋对付多源问题的?
对于第一张表,上下部分格式完全不同,只能采用子报表的法子了, 也就是把下半部分造成一个子表贴进去。这样倒是解决了多源问题,可新问题又来了,首先让原本就极难对齐的格线变得更难对齐,目前这个还算简单,如果搞上三五个子表横七竖八的排起来,每个子表都不知会变得有多大(表会根据数据库中数据扩展),那就要充分考验您当初平面几何念得如何了;其次主子表之间除了简单的参数传递外,互相没法沟通,要想把几个子表中的数加一加,对不起,您得自个儿呆一边重算去。所以,子报表是能不用就甭用的。
而第二张表,样子看起来倒不复杂,用不着搞子表。不就俩数据表吗,咱会叉乘呀,写个麻烦一点的 SQL 不就得了吗。那是,俩表时这么搞一下还行,可指不定会有几个源呢,中国报表中有七八个数据源的并不罕见,甚至十几个的也不过份,您总不能把这一大堆表都让可怜的数据库去叉乘吧,如果真这么搞,稍有不慎把语句写的不合适(比如偷懒先 JOIN 后 GROUP),算一个表您就可以沏杯茶歇一下了,茶喝完了还不定能算完;而且,这 SQL 越写越复杂,和写代码好象也没什么差别了,那天书般的 SQL 语句要是出点错谁来查(笔者就见过长达三页纸的 SQL,那确是天人所书,真亏数据库居然算得出来)。这还不算,如果这几个源来自多个不同的数据库那可就彻底完了,想喝茶都没戏了。
怎么办?只好祭出最后的法宝——写代码!咱毕竟是程序员嘛,还会写存储过程准备中间数据表,无论多少源、来自多少库,只要肯写代码,统统搞得定。哎,可这么搞,还要这些报表工具干吗呢?
怎么样,折腾得够呛吧,不过,您可别松气,麻烦人的还在后面呢。
中国报表的第二个重要特征是分片,与多源相关,但又不完全一样。多源一般都会是分片的,但分片却不一定是多源的。
还是上面这两个例子,两个报表都很明显地分成了两片,每片都有自己独立的规则,很难统一成一种规则处理。而我们手中的报表工具,如果不考虑采用子报表的话(其危害在上面已经说过了),都要求报表有统一的规则,整个报表只有一片可以重复的条子(细节区和相邻的分组区),因为是单源的,想当然地以为只要一片重复区就够了,理论上就不可能做到分片规则了。
但中国报表中分片现象太常见了,同一批数据也可能按不同的主题统计汇总,比如人事表中并列着按民族划分再按学历划分。事实的情况还远不止分作两片,常常是竖着五六片,横着也是五六片,整个报表乘起来就有二十五六片。而且片与片之间又不是完全独立,横向的分片在纵向规则却又是一致的,反之也是如此,这样既算想搞成子表,嘿嘿,怕是也不大容易,每个分片的表头都要重复编排,对齐则更是要命。
如果运气好,虽然分片了,但整个表的样式看起来还是一致的(比如上面的第二个表),那还可以使出咱最后的杀手锏——写代码!咱写程序把分片的数据搞成一片不就完了,那还是那个话,咱花钱买这这报表工具干吗来了?
运气不会时时都好,如果碰到那种上下(或左右)几个分片中分组层数都不一样的表,那就连最后的法宝都不管用了,就算代码能把数给算好,可格子却拼不出那种上下不同的样子,这会儿您就会特别想念 EXCEL 了,至少样式是可以很随意的,写代码也就可以搞定了。哎,直接做是做不出来了,用子报表也太恐怖了,想法和用户商量吧,搞表格简化一点吧,别老搞这么怪的样子,我做得烦,您看着也晕吧,咱改简单点吧。
够烦心了吧,嘿嘿,您可甭急,分片问题这才说了一半。
具体到每个分片也不是省油的灯,不象老外弄得那么简单,一下把所有的数都列出来,或者把所有的分组一个不落一个不重的列出来,这种搞法我们叫做“完全划分”。对应的就还有“不完全划分”,也就是分组中并不是把所有出现的情况都列出来(这种很常见),而且还可能重复列出(这个相对少见些)。比如我们按民族划分人员时,不大可能把五十六个民族全来一遍,一般也就是列几个大的民族再加个其它。比较典型的不完全划分现象就是固定行列,无论数据库中有多少记录多少分组,咱就只关心这几种情况,表格永远只有这几行(列)。
这可奇了,会变多的行列得能做出来,固定的还搞不定吗?嘿,还真是这么回事,老外这些东西天生就是和数据库绑定的,固定行的倒不是搞不出来,可又要写代码或者复杂的 SQL 去准备数据了,象著名的资产负债表,用这些报表工具去搞简直就是有点摧残生命了。
而且就算是会变动的,这些工具也还有个行列不对称的问题,由于和数据库贴得太紧,大家只见过记录数会变的数据表,都没怎么见过字段数也会变的数据表,于是这堆工具也就专心处理行方面的变化了,拒绝去处理列数会变的表,后来总算有了一些打补丁的交叉表模板,能对付点事了,但总是用起来不那么得心应手。可咱中国报表才不管这些,想往下长就往下长,想往右长就往右长,咱没觉得行和列有那么大的差别,至多列数可以少一点,总不能不让咱动呀。这么一搞,只要碰到变列的交叉表,除非特别规整的,这些大牌武器就又要虾米了。
中国报表统计方面的第三个复杂点是格间运算,特别是跨行组的运算。
要统计就要有运算,所有的报表工具都提供了计算汇总的功能,运算只有两种,一种是行内各列之间的运算,另一种是针对某组(或全体)所有数据进行的汇总(可能带条件),两种运算可以组合。但是,在中国的报表中只有要时间序列的,多半就要涉及到比上期、比去年同期之类的运算,这种运算跨行甚至跨组了,这个本事,咱手上这些报表工具又没有了。这是有原因的,大体这类工具都和数据库的概念匹配得很好,而数据库的行是没有次序的,搞不清谁是谁的上一行,比上期就没法定义了,比去年同期这种跨组运算更是想不明白了。为了解决这些问题,有些工具添加了一些引用上行或累积值的特殊函数,但跨组运算依然没法处理,您只好再一次使出编程序的法宝,自己写代码把数据准备好吧。
这种比较有规律的东西倒还不算太难办,编程序准备数据或是写个复杂些的 SQL 都还是可以搞定的。但中国报表中常常还会有些独独的格子,其运算方法和谁都不搭界,或是胡乱从表格中东西南北挑几个格子加减乘除一番,或是干脆自个儿到数据库中再搞一句 SELECT 算一把,完全与其它格子之间无规律可循,整一个十三不靠。这下可就费大劲了,这不是在后台写点程序准备好数据库就完了的,要生成完表格再编程序计算出这些数填进去,这种搞法一般就得采用报表的脚本或者宿主开发语言来写代码了,弄得代码满天飞,维护时找不到北。
这三个较大的数据统计问题已经把大伙折磨得差不多吧,其它相关的还有一些次要问题,比如参数和宏的引入、交叉表的表头向右对齐问题等等,咱就不细说了。
不过,事还没算完。中国报表还有填报的要求。
所谓填报,顾名思义,就是填了再报,那报表不是统计汇总完了就完了的,还要能填能改,改完的结果还可以再存起来,咱从小不就常常填表吗?可老外哪里想过这种问题,造出来的工具统统没有这个本事,人家觉得报表是报表,就是不可改的,填的表是另一种东西,根本不能叫报表。但咱中国人天生就认为表都是可以填的,这世上哪有不能填的表,那还叫表格吗?
说得也是,人家 EXCEL 就可以填,而且填着还方便得很,搞得按照 EXCEL 抄的国货也统统有填的本事。不过,话说回来,这些工具还是有上面说的问题,没有数据模型,填完的数不知怎么写进数据库,于是常常只能放进文件中(就象 EXCEL 文件本身),等着您再编程序处理吧。
填报功能说起来其实也挺复杂的,首先要允许表格和数据库字段的随意对应,我可能整表一条记录,也可能一行一条记录,甚至可能一格一条记录(交叉表填写),这几种情况还可能是组合出来的,同一张表一下子写进好几个数据表。填的过程中还应当有自动计算能力(比如 EXCEL 就很强了),提交时应当有合法性的检查功能,看看您填的数是否合理;更有甚者,中国要填的表经常是一套一套的,十几张之多,那不是一时半会儿填得完的,咱得下载下来回家慢慢填,这又需要多页填报或离线填报的功能。这每条功能搞起来都没那么容易,够狠吧!
除此之外,中国报表还有不少折磨人的小地方,特别是在打印输出方面,比如一张纸上打印几个小票据,横向分栏,横向分页时左表头的重复,末页补足空行,票据套打等等,这些比较头痛但还不算什么根本的问题,这里就不仔细评说了。
还有一个和中国报表特征没啥关系但是程序员常常碰到的头痛问题,就是产品的集成性。
在国内做应用开发,报表只是应用的一个部分而非全部,报表总是要被集成到应用系统中去,如果某个报表工具能力超强,但却不可被集成,那也是没啥意义的。
考虑到当前国内应用开发的现状,我们只研讨基于 J2EE 机制下的 B/S 应用的报表集成。
现在流行的报表工具几乎都是独立服务器形式。咱可能资质愚钝,想了许久,楞没想出独立服务器的半点好处来,倒是想出一大堆坏处,下面就来批判批判:
报表服务器与应用程序不在同一个进程空间内,数据沟通都需要通过网络协议进行,即算是同一台机器上,也要把数据传来传去,无端浪费时间降低性能;这种独立的服务器常常还自己搞一套用户权限管理机制,设计得还很复杂,咱的程序必须向这个规矩上靠,可这套规矩从来也不会够用,应用系统的用户管理啥时候也没那么规整过,就乖乖地按它家设计的样子来,比如您何曾见过这样的系统,把应用系统中的柜员、科长、局长这种业务角色建立在 ORACLE 的用户上?这种费了劲又严重影响集成度的东西其实不搞也罢,常常因此浪费巨多的时间还是和应用接上不口。
然后还有问题,独立服务器又没法充分应用服务器的本事,比如数据库连接就不能和应用系统的其它模块共享,非要独独地自己搞一摊,更过分的是集群能力,也还得听命于这个报表服务器。靠,我就不信,Weblogic 的平衡负载能力会比你的报表服务器要差劲?人家专吃这碗饭的会搞不过你?可没办法,也只好由着它折腾了。还有部署方案,本来所有的程序数据打个 WAR 包很方便就上去了,可它偏要与众不同,要独自战斗,还是搞得咱没脾气。
想来想去,估计美国人可能不大需要被集成的报表工具,所以老外的产品也不是为了被集成而设计,这也就情有可愿了。可叹的是,国人抄老外时也没怎么想想,大多一古脑地把体系结构也抄了过来,特别是海归派的新兴企业,抄得有鼻子有眼的,费了老劲还没落到好;有系统集成经验的国产报表厂商就还稍好一点,没去费那没用的劲。
牢骚差不多发完了,这下您该知道中国报表到底是怎么个麻烦法,为啥我们有了国际水平的先进武器依然过得很衰。这些流行的工具名头虽响,确实是极其不适合中国报表的,号称能适应中国报表的大都是胡说八道,赶赶时髦而已。
是不是中国人真地吃错了什么药非要把报表搞这么复杂,以后有没可能简单起来?
报表工具厂商中有一个较普遍的说法是中国现在的应用水平太差,用户都不懂信息化,所以造成了报表复杂,一句话,就是咱的需求错了,咱不够高档,人家高档的美国用户就不用这么复杂的表格。
听起来有点道理,其实是胡扯!明明是自己做不出来,偏偏要说用户的需求不合理,象是《笑林》的那个笑话,和尚念错了经却指责人家死错了人,真是岂有此理!
说老实话,由于没有信息化经验而设计出不合理的报表当然也是存在的,但大部分情况下即使信息化程度已很高,那报表还是复杂得很,而且信息化程度越高,EXCEL 使得越熟,那报表就越复杂。比如银行,在中国算是信息化进行最早的行业了,您去瞧瞧银行的报表,嘿嘿,晕死人不赔命的;再如日本人,信息业够发达了吧,那报表还是那样复杂得没商量。至于说美国人的表为啥不太复杂,咱没在美国生活过,还真一下子搞不清。不过,中国的报表复杂是很有道理的,各项信息在表上一目了然,就是省事。所以笔者认为,大概是东方文化传统的因素让中国报表复杂下去,如果真是这种原因,中国的报表还将一如既往的复杂下去,怕是没什么简化的指望了。
所以呢,不要寄希望于报表会变简单,那会被你的竞争者置于死地的,还是努力想法怎么解决这些问题吧。

