"各位老师帮忙看一下 这个场景怎么优化 谢谢 场景描述 [链接] 各个数据表的数据量信息 [图片] 现在脚本 [链接]"
各位老师帮忙看一下 这个场景怎么优化 谢谢
场景描述docx
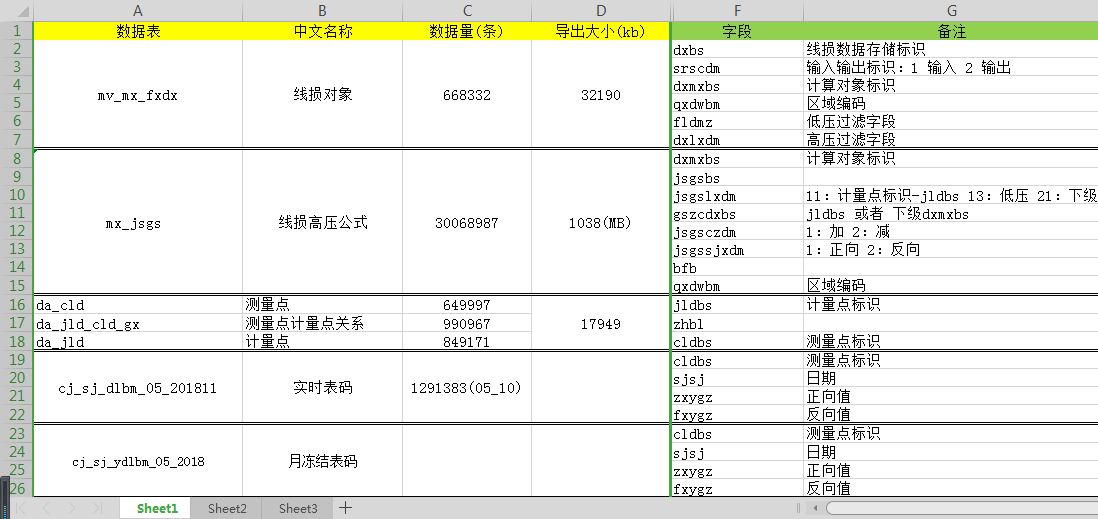
各个数据表的数据量信息
现在脚本zip
大概看了一下,一些问题:C18 的 pos,要先排序再用 pos@b;C17 也不要这么一点点计算出结果集这一段改成这么写:【写错了,C18/D18 中的 A17 应当是 C17】下一个循环中,B22 要用 find,其实 B21 直接用 switch 去指向那个维表,就不需要 B22 格。B23 格在循环里面读文件,这个是很忌讳的,想办法放到外面去,是否可以一次性把所有需要的文件都读进来,看不了那些 xls 有多大。一步步地优化,先把第一个循环跑出来看效果
当 C17 中的分组没有 JSGSLXDM==11 时,下面的索引会超界。所以还要判断分组情况只有 11,没有 11,还是都有,会不会更麻烦?
….align@a([false,true],….==11)
这是目前执行的是时间一条大概在 40 秒,B9 格大表取数 480 秒。现在查询的是汕头这个地市的数据大概 3 万 5 千条,客户用的 C 语言执行 10 多分钟就可以计算完了。
这个是现在的脚本1zip
您看现在还可以怎么修改吗。
这个是现在的脚本
1zip
B23 读了几万次文件,这一句要移到循环外面去。C 语言如果写成这样的算法逻辑也不可能快。把涉及的文件一把都读进来放着,更好的是把那些文件都先拼成一个大文件。其它还有不少代码写法问题,但应当都不是大头,先把这个逻辑改出来再优化其它地方,这一句应当占了 90% 以上的执行时间。
这个是把那个 B23 的文件改到外面的结果
这个是改后的脚本1_1203rar
把执行时间长的语句标出来
现在的脚本
_1206rar
现在的结果 循环到第五次的时候执行了 10 多分钟也没有输出 分步执行到 C21 时不能继续
这个就看不出来了,要 D20 及相关变量的长度打出来看看另外,你可以比一下这种计算方式和原来的计算方式(都比算这一步)的时间差距,感觉一下能提速的倍数。





大概看了一下,一些问题:
![imagepng]()
C18 的 pos,要先排序再用 pos@b;C17 也不要这么一点点计算出结果集
这一段改成这么写:
【写错了,C18/D18 中的 A17 应当是 C17】
下一个循环中,B22 要用 find,其实 B21 直接用 switch 去指向那个维表,就不需要 B22 格。B23 格在循环里面读文件,这个是很忌讳的,想办法放到外面去,是否可以一次性把所有需要的文件都读进来,看不了那些 xls 有多大。
一步步地优化,先把第一个循环跑出来看效果
当 C17 中的分组没有 JSGSLXDM==11 时,下面的索引会超界。所以还要判断分组情况只有 11,没有 11,还是都有,会不会更麻烦?
….align@a([false,true],….==11)
这是目前执行的是时间一条大概在 40 秒,B9 格大表取数 480 秒。现在查询的是汕头这个地市的数据大概 3 万 5 千条,客户用的 C 语言执行 10 多分钟就可以计算完了。
![png]()
这个是现在的脚本
1zip
您看现在还可以怎么修改吗。
这是目前执行的是时间一条大概在 40 秒,B9 格大表取数 480 秒。现在查询的是汕头这个地市的数据大概 3 万 5 千条,客户用的 C 语言执行 10 多分钟就可以计算完了。
这个是现在的脚本
1zip
您看现在还可以怎么修改吗。
B23 读了几万次文件,这一句要移到循环外面去。C 语言如果写成这样的算法逻辑也不可能快。
把涉及的文件一把都读进来放着,更好的是把那些文件都先拼成一个大文件。
其它还有不少代码写法问题,但应当都不是大头,先把这个逻辑改出来再优化其它地方,这一句应当占了 90% 以上的执行时间。
这个是把那个 B23 的文件改到外面的结果
这个是改后的脚本
1_1203rar
把执行时间长的语句标出来
现在的脚本
_1206rar
现在的结果 循环到第五次的时候执行了 10 多分钟也没有输出 分步执行到 C21 时不能继续
![_20181206202836jpg]()
这个就看不出来了,要 D20 及相关变量的长度打出来看看
另外,你可以比一下这种计算方式和原来的计算方式(都比算这一步)的时间差距,感觉一下能提速的倍数。