


集算器跨库计算能力解决报表内计算慢的问题
多年前开发了一套报表,当时的多数据集(涉及一报表从多库关联取数) 在报表内计算是通过 select 函数加条件的方式实现 关联取数。
如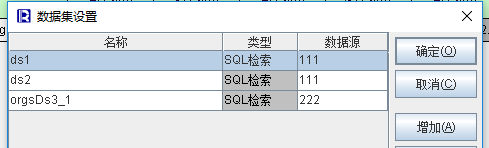 多数据集(两个数据源)
多数据集(两个数据源)
报表内关联取数
类似 D2 的单元格涉及 50 几列
在报表内如上遍历式方式取数,复杂度可以说是平方级的,速度极慢。
但,目前采用集算器进行优化,利用集算器的跨库关联计算能力,能将多数据集轻松合并为一个数据集, 那么消除了在报表内遍历过滤取数的方式,报表的计算速度将极大提高。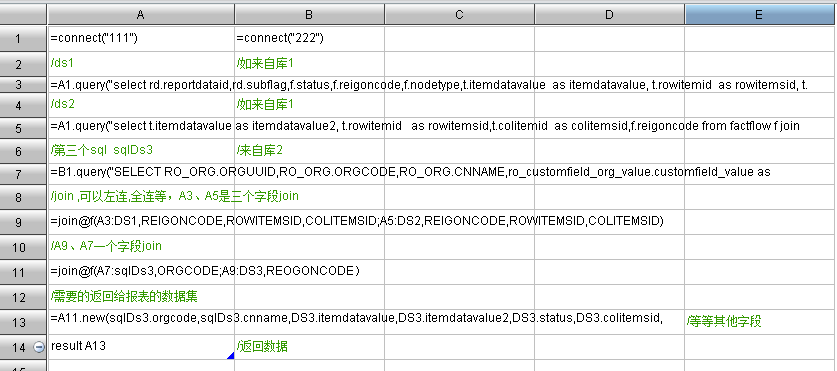
报表仅一个数据集,报表内就不用多数据集间关联遍历取数了
从实际的环境测试,原报表从取数到计算结束呈现需 2 分半钟(150 秒左右), 用集算器处理数据集后 时间为 10 秒左右。
总结:集算器对多数据集关联处理,优于报表中的遍历方式,复杂度由平方级降为线性级。

