


早下班系列 | 比 python 更称手的兵器
【摘要】
作为近些年最出风头的编程界的宠儿,Python 的人气火爆自不必多言。然而,若说 Python 想就此一手遮天,恐怕也不是那么容易。集算器专用编程语言 SPL 的横空出世,让我们看到了一种从不甘居于人后的王者风范:早下班系列 | 比 python 更称手的兵器!

有人觉得这标题有点儿像王婆卖瓜?其实要说我一开始也不是很自信。毕竟看了这篇文章里写的信誓旦旦的:《为什么你经常加班,却干不过那些准点开溜的同事?》,再加之久仰 Python 的鼎鼎大名,且看过的 Python 的教材的前言中提到许许多多强调 Python 的优点:语法简单、容易上手、世间最后的正义等等(对比的当然是著名的 C++ 和 JAVA),我也不禁怀疑了:要做得比 Python 还爽,需要做到什么地步?
先看看环境实现、代码编写的效率
鉴于我是一个爱折腾的码农,又自负有那么点 Python 的基础,借着害死猫的好奇心驱使,便打算试试手:看看这 Python 到底有多简便。
要搞 Python,第一步当然是安装 Python 解释器,那么问题来了:选 Python2 还是 Python3?虽然看起来只是版本升级,但其实却是连语法都换代(不是升级的意思,Python3 不能完全兼容 Python2 语法)。虽然有 Python 牛人说“语言不是问题,重点在于思想巴拉巴拉……”,但对于瑟瑟发抖的新人们来说,我想大多还是不希望看到:因为缺个括号,就连 print 都出不来 Hello World 了……这样的闹心事吧?对比了种种网上意见,最后还是决定支持先进:选 Python3。这样就算过几年再出个语法换代的 Python4、Python5 啥的,至少我的 Python3 能比别人的 Python2 多活个几年。
安装完解释器,再选一个写代码的编辑器。因为最近习惯用 eclipse——开源、跨平台、免安装,且支持多种插件——所以我决定在 eclipse 上安装个 pydev 来实现支持 python 编程的功能。百度上找了一个最简便的方法:网上在线安装。结果安好之后发现找不着 pydev?再百度找问题,发现竟是 pydev 的版本太新了。只好先卸了再对照 eclipse 和 jdk 版本找了一个恰到好处的,一边百度一边实验,一个小时总算搞定。速度很慢?要知道网上可是有人自述弄了整整一个下午。所以对这一点我还是蛮佩服自己的。
安完编程环境后,总该爽一下了吧?先 print 个 Hello World?完美!再找之前的文章 copy 一下代码……嗯?第一行 import pandas 报错?缺少 pandas 的库?这么重要的科学计算常用库为啥这 python 安装时就不自带一下啊?还是自己安吧……
上网继续百度……发现有说安一个 anaconda……但那样我之前安的 python 和 pydev 不是都白费了?且 anaconda 自带的编辑器 spyder 编写复杂工程不够强大又容易崩溃,还有有很多 anaconda 没有的库你自己再添加又不知有没有什么兼容之类巴拉巴拉的问题……否决。直接安装个 pandas 库呢?也不行,还有一大堆 pandas 需要的乱七八糟的其他库等着你呢(linux 一族的通病)。用 pip 工具安装?没有外网不行,不过还好我有。但前提是得先安 pip 工具本身。怎么安装?源码编译……万幸!大学英语没忘光,摸着英文线索一路搞到了 pip 的源码文件,瑟瑟发抖的编译通过后(此处需要使用之前的 python 环境),再从百度上找一个用 pip 安装 pandas 库的详细教程,附带 pip pandas 所有必须支持库的网址,一顿 pip 下来后(此处需要命令行),再回 eclipse 中继续试验 import pandas……居然还不行!!!什么情况?抱着死马当活马医的心理,打开了 python 的命令行工具:python shell,试试在 python shell 中 import pandas 行不行?竟然又行了!再回 eclipse 里继续测试,也正常了!各种原因太过玄幻,还是找一位 python 界的大神来解释吧……
到这一步,总算可以开始最早提到的那篇文章中的 python 编程了。回到之前提到的《为什么你经常加班,却干不过那些准点开溜的同事?》这篇文章,原文中竟然是用程序代码中的字符串做表数据源……将数据写到程序里感觉也太山寨了点,这样改数据难道还得改程序不成?而且如果数据过大,导致内存装不下怎么办?又或者数据想跨程序使用又该怎么办?所以咱至少写个文本文件之类的外存文件做数据源。
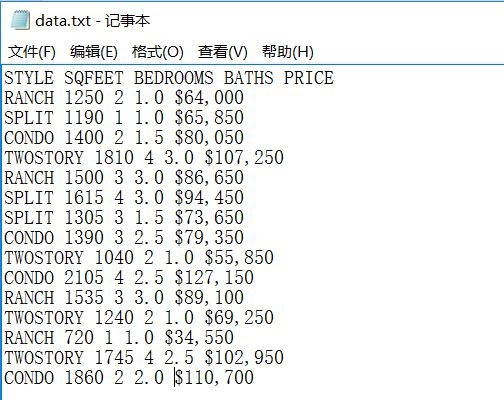
接下来就是编程了,除了加了第一步的读文件操作之外,其他都跟原文一样
import pandas
f = open(‘D:/data.txt’,‘r‘)
try:
a = f.read( )
finally:
f.close( )
b = []
for i in a.split(“\n”):
b.append(i.split(” “))for i in range(1, len(b)):
b[i][4] = b[i][4].replace(“$”,‘ ‘)
b[i][4] = b[i][4].replace(“,”,‘ ‘)for i in range(1, len(b)):
for j in [1, 2, 3, 4]:
b[i][j] = eval(b[i][j])data = pandas.DataFrame(b[1:],columns=b[0])
out = data.groupby([‘STYLE’,‘BEDROOMS’]).mean()print(out)
运算结果也一致
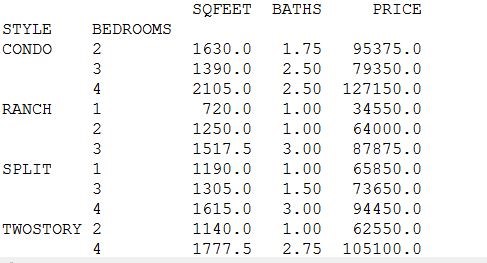
简单吗?照比 C++,那是简单得很,但如果对比集算器呢?
集算器的安装咱就不说了,非得要问?那你一定是在逗我……
先上集算器的程序:真不是欺负你,就三行代码,而且连一个循环都用不着写!实际上,如果不是最后一列字段的数据有点特殊需要处理一下,两行就可以搞定
| A | |
|---|---|
| 1 | =file(“D:/data.txt”).cursor@t(#1,#2:int,#3:int,#4:float,#5;,” “) |
| 2 | =A2.run(int(replace(replace(#5,”$”,””),”,”,””)):PRICE) |
| 3 | =A3.groups(STYLE,BEDROOMS;avg(SQFEET):SQFEET,avg(BATHS):BATHS,avg(PRICE):PRICE) |
再看看计算的结果:与 python 完全一致
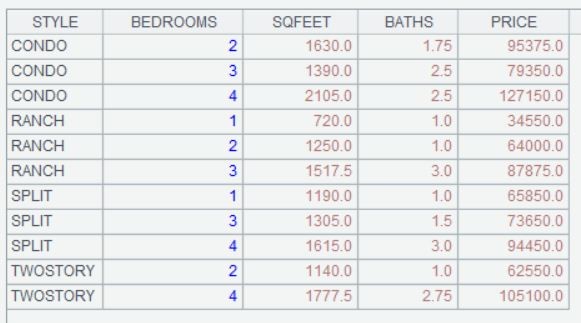
如果你还是有些犹豫的话,那么不妨再透露一个重要的内幕:集算器的这种使用处理方法(游标),是可以支持大数据处理的,而且只要再加个选项还可以支持多线程并行计算。而上面的 python 算法要支持大量数据,那改起来可就不是一句两句能完事的了,再上个多线程并行计算?我感觉您可能需要的是一位有多年 python 编程经验的老鸟……
再看看代码运算的效率
最后,不妨加入计时代码,看看运行程序消耗的时间。
先加 python 的计时代码(友情提示:计时单位是秒)
import pandas
import time
start = time.clock()
f = open(‘D:/data2.txt‘,‘r’)
try:
a = f.read( )
finally:
f.close( )
b = []
for i in a.split(“\n”):
b.append(i.split(” “))
for i in range(1, len(b)):
b[i][4] = b[i][4].replace(“$”,‘ ‘)
b[i][4] = b[i][4].replace(“,”,‘ ‘)
for i in range(1, len(b)):
for j in [1, 2, 3, 4]:
b[i][j] = eval(b[i][j])
data = pandas.DataFrame(b[1:],columns=b[0])
out = data.groupby([‘STYLE’,‘BEDROOMS’]).mean()
elapsed = (time.clock() – start)
print(elapsed)
鉴于原有数据文件太小,体验不出什么差距,不如干脆做大一些,能更有对比价值。就做个 22.3M 的文本文件(就是把原有数据不断复制粘贴来把文件撑大一点)
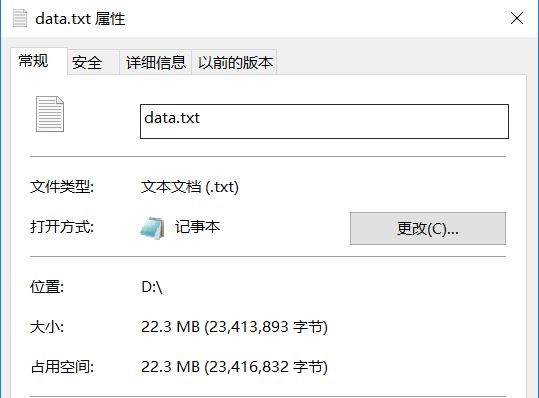
先测试 Python:
为了不让 eclipse 影响运行速度,这里干脆拿到命令行里执行(elicpse:俺不背锅!)
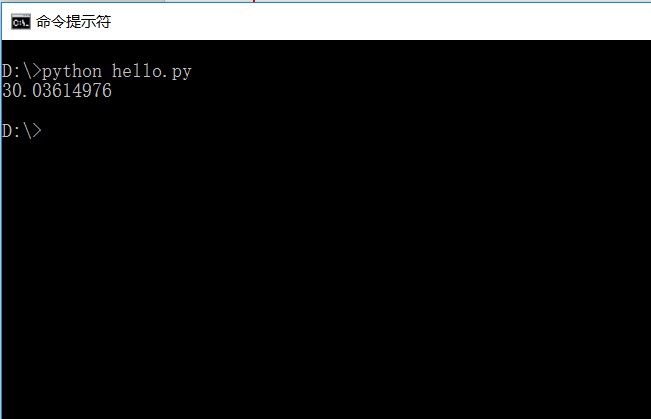
再次友情提示:python 这里计时使用的单位是秒……嗯,处理 22.3M 的数据 30 多秒……还好我一直坚持等下去,没误以为已经卡死,给他来个 Ctrl+C……
然后再看看集算器,也加入计时代码(友情提示:使用 @ms 选项后计时单位是毫秒)
| A | |
|---|---|
| 1 | =now() |
| 2 | =file(“D:/data.txt”).cursor@t(#1,#2:int,#3:int,#4:float,#5;,” “) |
| 3 | =A2.run(int(replace(replace(#5,”$”,””),”,”,””)):PRICE) |
| 4 | =A3.groups(STYLE,BEDROOMS;avg(SQFEET):SQFEET,avg(BATHS):BATHS,avg(PRICE):PRICE) |
| 5 | =interval@ms(A1,now()) |
然后再看看耗时(点击 A5 格就会在右侧显示计算出来的计时数值)
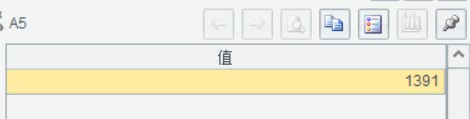
1391 毫秒约等于1.4 秒(请注意此处有个小数点……)
看到这样的对比结果,我觉得啥也不用说了,请大家自己用心去体会(我也就不得寸进尺地说:其实集算器好多加速方法还没用上呢……毕竟太欺负人了不好……)

