


早下班系列:轻松玩转 Excel 行列转换

下面这种交叉式的 Excel 表是很常见的格式,用来填写和查看都比较方便:
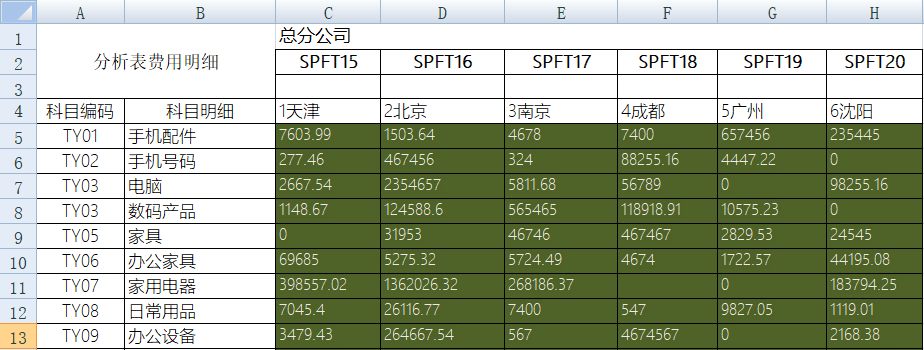
但是,如果想做进一步的统计分析,这种格式就不方便了,需要行列转换,变成如下格式的明细表:
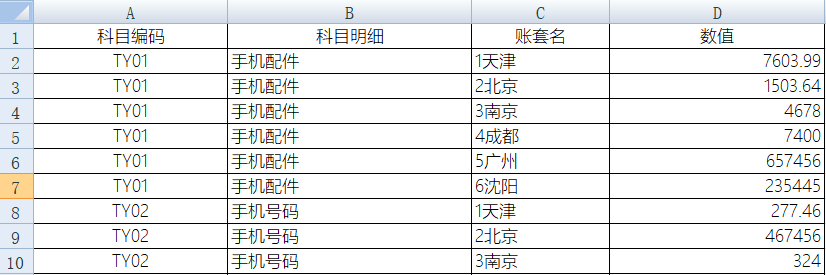
显然,手工操作会非常麻烦,若数据量小还可以,数据量大了会耗费大量时间,简直就是灾难。
Excel 也可以通过数据透视表支持行列转换功能,效果如下图:
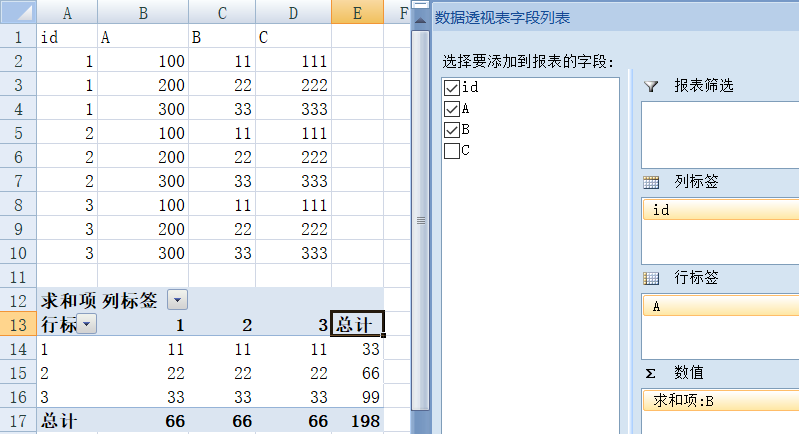
但这并不是我们想要的格式。
看来只能写个程序来解决了,思路也很简单:
- 加载 excel 文件,装载需要的 sheet 工作表。
- 读取账套名所在的行,将其转换成字符串数组。
- 读取科目编码所在列,将其转换成字符串数组。
- 按科目编码分组,与账套名数组构造一张表。
- 根据账套名对应的数据,遍历所有的明细值填充到相应的表中。
- 这样就构造出对应的明细表来。
如果用 Java 来实现,初步估计代码量也不会少于 200 行,若需要结果输出成 excel 文件则开发工作量会更多。Excel 自己虽然提供了 VBA,但那个麻烦度谁用谁知道,不提也罢。其它的语言呢?传说 python 有处理行列转换的功能(pandas 包里有 pivot 功能),代码量相对于 java 会少很多, 我们来试一下:
import pandas as pd
import numpy as npdf = pd.read_excel(“D:\\excel\\pandas.xlsx”, 0, 3)
cols = df.columns.values.tolist() #获取数据头信息
#移去前两列,只保留需要行列转换的列
cols.remove(‘科目编码’)
cols.remove(‘科目明细’)
#构造一个 list.
frames=[]
for col in cols:
df1 = df.pivot_table(index = [‘科目编码’,’科目明细’], values = [col])
df1.rename(columns={col: ‘数值’}, inplace=True)
df1[3]=col
#转换后的数据追加到 frames 中.
frames.append(df1)
# concat 将相同字段的表首尾相接
result=pd.concat(frames)
result.rename(columns={3: ‘帐套名’}, inplace=True)
result.to_excel(‘D:\\excel\\pandas_n.xlsx’, sheet_name=’科目明细’)
嗯,还不错,果然比较简洁!这是 Python 生成的 excel 文件:
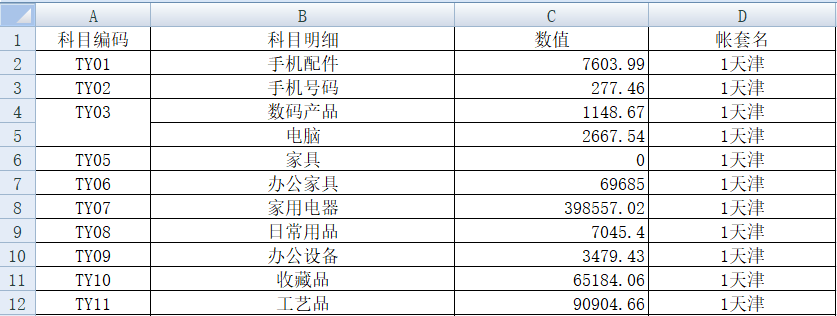
python 确实名不虚传,虽然使用了循环,但整个代码也就只有 10 来行的样子。
还能更简单吗?
嘿嘿,能!
我们来看集算器的代码:
| A | B | |
|---|---|---|
| 1 | =file(“D:/excel/ 明细.xlsx”).xlsimport@t(;1,4:40) | // 读入 excel 文件 |
| 2 | =A1.pivot@r(科目编码, 科目明细; 账套名, 数值) | // 用 pivot 函数进行行列转换 |
| 3 | =file(“D:/excel/ 明细 2.xlsx”).exportxls@t(A2;“科目明细”) | // 将整理好的数据另存储为 xlsx 文件 |
代码很简单,我们把每一步的中间结果列出来看看:
A1:加载 excel 文件工作表 1,提取指定范围的数据 (从 4 行到 40 行),其中选项 @ t 表示首行为标题,载入数据, 生成表格如下:
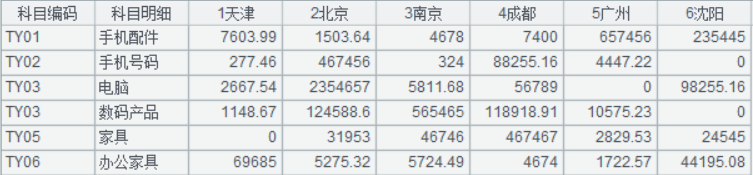
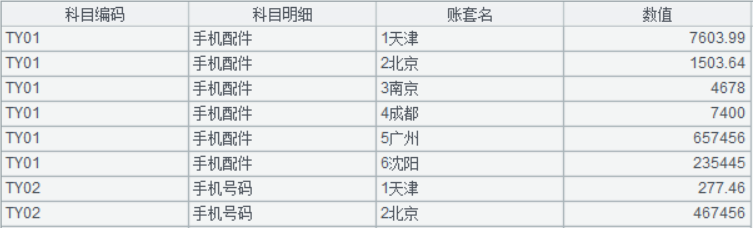
A2:pivot 函数将行列数据进行转换,除字段“科目编码, 科目明细”外的字段对应的列数据置放到“数值”列
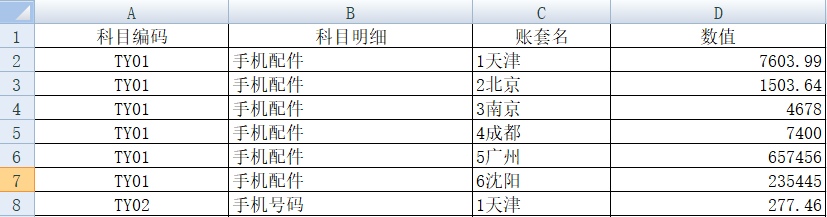
A3:将整理好的数据另存储为 xls 文件
集算器脚本只 3 行,而且木有啥循环、判断之类的玩意儿,也不像 Python 那样要先手工倒腾一下,就把这看似有点“乱”的数据表格处理好了。相比之下,Python 采用列优先转换多次循环 “N”字方式,集算器则用行优先一次性处理,在处理数据上,集算器对细节处理及使用习惯更专业。而且集算器的开发环境也容易调试,可以看到每一步运算的中间结果,方便挑出错误,开发更为便捷。在这种常规数据处理的任务中,集算器要比 Python 更为优越。

