


SPL 实践:结构化文本上的计算
结构化文本计算需求
结构化文本文件是常见的数据存储方式,比如这个score.txt,记录了所有班级学生的成绩,第一行是列名,之后每一行是一个学生的数据,行内用制表符分隔。
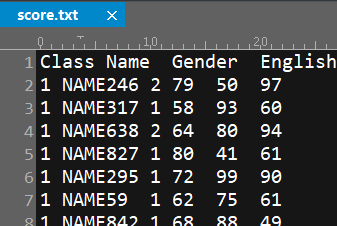
这种结构化文本也会有各种计算和处理的需求,比如选出英语90分以上的女生、计算出每个学生的总分并由高到低排序、计算出各班语文平均分等。
导入数据库用SQL计算当然没问题,但过程比较麻烦,而且也不一定总有数据库可用。写Java代码也非常繁琐,用SPL就非常简单了。
读入结构化文本文件
先看如何加载文件。A1的import()函数能直接把结构化文本文件读成内存数据表,其中的@t选项表示第一行为字段名。对于逗号分隔的csv文件,可以使用选项@c读入,@tc表示读取第一行为列名的csv文本。
A1/A2分别读入score.txt和score.csv。A3/A4用T()函数也可以同样能读入score.txt、score.csv,它会根据文件扩展名自动加载。
读取文本数据还有其它情况,比如没有标题行、只读入部分列、自定义分隔符以及文本中带有引号回车符等等,这些功能细节可以参考官方文档。
A |
|
1 |
=file("score.txt").import@t() |
2 |
=file("score.csv").import@tc() |
3 |
=T("score.txt") |
4 |
=T("score.csv") |
尝试过滤
来尝试一下过滤运算,比如要选出英语90分以上的女生。A1用T()函数把文本数据加载成内存数据表,A2用select()函数过滤数据,能看到结果中只剩下90分以上的女生了。A3中的点运算符可以把加载数据、过滤运算合成一句,计算结果相同。
如果把这个文件看成一个表,对应运算的SQL语句是这样的:
SELECT * FROM score
WHERE English>=90 AND Gender=2
有时候希望动态传入过滤条件的值,可以预定义默认值为80分和男生的两个参数,运行时还可以再修改,A4中的select函数使用这两个参数变量即可。
A5中把A2的结果序表用export()函数回写成文本文件filter.txt。与import()函数同理,@t选项表示第一行将写成标题。
A |
|
1 |
=T("score.txt") |
2 |
=A1.select(English>=90 && Gender==2) |
3 |
=T("score.txt").select(English>=90 && Gender==2) |
4 |
=T("score.txt").select(English>=argEng && Gender==argGen) |
5 |
=file("filter.txt").export@t(A2) |
再试聚合
再尝试一些聚合运算,分别算出女生、男生的最高分,平均分,与SQL的聚合函数基本一致。
A |
|
1 |
=T("score.txt") |
2 |
=A1.select(English>=90 && Gender==2) |
3 |
=T("score.txt").select(English>=90 && Gender==2) |
4 |
=T("score.txt").select(English>=argEng && Gender==argGen) |
5 |
=file("filter.txt").export@t(A2) |
SQL:
SELECT max(Math), avg(Math)
FROM score WHERE English>=90 AND Gender=2
SELECT max(Math), avg(Math)
FROM score WHERE English>=90 AND Gender=1
集成Java应用
初步计算尝试过后,我们再来看如何把这些代码集成进Java应用中。SPL提供了标准JDBC,可以像执行SQL或调用存储过程一样给Java应用提供数据查询、计算能力。
[JDBCConection].prepareStatement(SPL语句)
[JDBCConection].prepareCall(SPL脚本)
将[安装目录]\esProc\lib下的jar引入到应用中:
esproc-bin-xxxx.jar
icu4j-60.3.jar
然后将SPL配置文件[安装目录]\esProc\config\raqsoftConfig.xml复制到应用类路径下即可。raqsoftConfig.xml是SPL的核心配置文件,名称不可更改。
JDBC执行SPL代码
驱动类是InternalDriver,连接URL是jdbc:esproc:local。
创建的JDBC连接能像执行SQL查询一样执行SPL代码。这里加载score.txt,过滤出英语高分学生,用JDBC参数动态设置底限分,这里设置了90。运行这段Java程序,和其它普通JDBC用法一样,结果序表以ResultSet对象返回。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection con= DriverManager.getConnection("jdbc:esproc:local://");
PreparedStatement ps = con.prepareStatement("=T(\"score.txt\").select(English >= ? )");
ps.setInt(1, 90);
ResultSet rs = ps.executeQuery();
JDBC调用SPL脚本
把SPL程序保存为.splx脚本文件,这里保存为scoreCalc.splx:
A |
|
1 |
=T("score.txt").select(English>=90) |
2 |
return A1 |
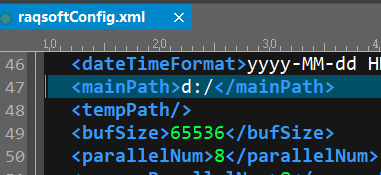
然后把这个脚本文件放入集算器主目录,raqsoftConfig.xml里配置为D盘根目录:
然后就能用JDBC调用存储过程的方式调用这些脚本了:
PreparedStatement ps = con.prepareCall("call scoreCalc()");
ps.execute();
ResultSet rs = ps.getResultSet();
执行call scoreCalc()就调用执行了scoreCalc.splx。结果集返回到ResultSet中。
JDBC执行SPL返回单值、多值
除了返回多行多列的序表给JDBC ResultSet对象,还可以返回一行一列的单个值,或多行一列的多个值组成的序列。
A |
|
1 |
=T("score.txt").sum(Math) |
2 |
return A1 |
1行1列的单值,列名固定为“Field”,如A2返回数学总成绩,70360分。

A |
|
1 |
=T("score.txt").sum(Math) |
2 |
=T("score.txt").count(Math) |
3 |
=T("score.txt").avg(Math) |
4 |
=T("score.txt").min(Math) |
5 |
return [A1, A2, A3, A4] |
多行1列的多个值,列名仍然为“Field”,如A5返回数学总分、个数、平均分、最低分。

使用变量
继续看更多计算任务,把常见的SQL运算都用SPL实现一下。
为方便讨论,我们假定所有代码的A1格都是加载文件,然后将序表赋值给score变量,之后就不必再写A1了,只针对score做计算。另外,为简单起见,SPL代码中不再使用参数了,大家可以自己改造成有参数的情况。
A |
|
1 |
>score=T("score.txt") |
2 |
=score.select(English>=90 && Gender==2) |
3 |
…… |
计算列
用同行的多个字段值计算出新字段,例如计算出每个同学三科成绩的总分和平均分。
SPL用new()函数定义计算列,计算列中的表达式可以使用前面已有的计算列,如先算出total,再用total算出avg。
A |
|
2 |
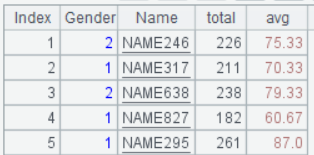
=score .new( Gender, Name ,(English+Chinese+Math):total ,round(total/3, 2):avg ) |
new()函数中也可以选出一些原始的列,混同新的计算列同时调整列的次序,这里将Gender调整到Name之前。
SQL:
SELECT
Gender, Name
,(English+Chinese+Math) as total
,(English+Chinese+Math)/3 as avg
FROM score
增加计算列
如果想在原有的序表上直接增加新的计算列,可以用derive()函数,这里把三科总分和平均分追加上。
A |
|
2 |
=score .derive( (English+Chinese+Math):total ,round(total/3, 2):avg ) |
SQL:
SELECT
*
,(English+Chinese+Math) as total
,(English+Chinese+Math)/3 as avg
FROM score
排序
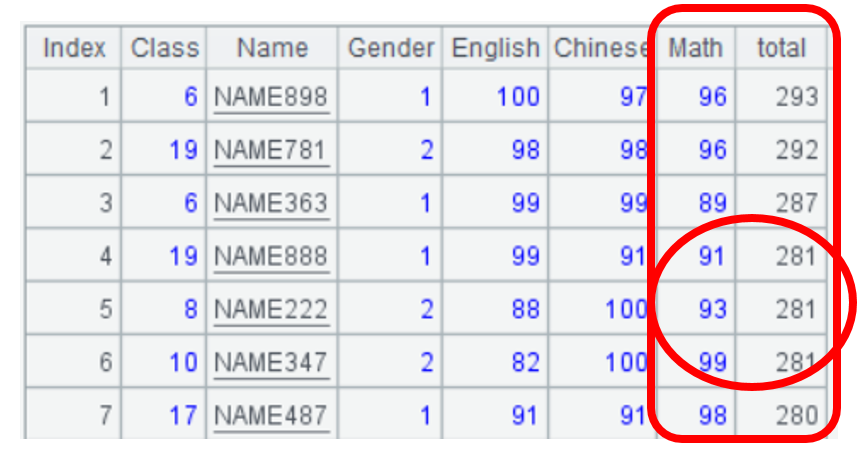
将全年级学生按照总分由高到低排序,总分相等的按照数学成绩由低到高排序。SPL用sort()函数实现排序,排序字段total前面是负号表示降序,Math升序。
A |
|
2 |
=score.derive( (English+Chinese+Math):total ).sort(-total, Math) |
结果中看到总分281存在多个学生,其中数学分低的学生排的更靠前。
字符串、日期类型的字段也支持排序。如按Name倒序排序,从第一个字符逐个往后对比大小。
SQL:
SELECT
(English+Chinese+Math) as total
,*
FROM score
ORDER BY
(English+Chinese+Math) DESC
,Math DESC
分组汇总
要按班级、性别分组,统计人数和英语平均分,SPL中用groups()函数实现分组汇总。参数里分号前面定义分组字段Class、Gender,多个分组字段时,用逗号分割;分号后面定义汇总表达式,支持sum、count、avg,min,max等汇总方式。
A |
|
2 |
=score.groups( Class , Gender ; count(Name):cnt , round(avg(English),2):engAvg ) |
SQL:
SELECT
Class,Gender
, COUNT (Name) AS cnt
, ROUND(AVG (English),2) AS engAvg
FROM score
GROUP BY Class,Gender
分组汇总后再过滤
分组前先用select()函数过滤出数学60分以上的学生;
分组汇总后仍然用select()函数再过滤出英语平均分超过70的分组,SPL是分步定义计算的,中间步骤可以随时过滤,不用WHERE/HAVING区分是否发生在分组后。
A |
|
2 |
=score.select(Math>60) .groups( Class,Gender ;count(Name):cnt, round(avg(English),2):engAvg ).select(engAvg > 70) |
SQL:
SELECT
Class, Gender, COUNT (Name) AS cnt
, ROUND(AVG (English),2) AS engAvg
FROM score
WHERE Math>60
GROUP BY Class,Gender
HAVING ROUND(AVG (English),2) > 70
去掉重复值
SPL中用id()函数可以去掉重复值,一千个学生,去掉重复姓名后,有598个姓名。
A |
|
2 |
=score.id(Name) |
SQL:
SELECT DISTINCT Name FROM score
也可以多列组合起来去重,就是认为多列的值都相同时,才算作重复,如一千个学生组合Name和Math去重,剩余992个。
A |
|
2 |
=score.id([Name,Math] ) |
SQL:
SELECT DISTINCT Name,Math FROM score
去重计数
SPL中用icount()函数实现去重计数,1000个学生中去重后有598个名字。
A |
|
2 |
=score.icount(Name) |
SQL:
SELECT COUNT(DISTINCT Name) Name FROM score
icount也支持多列去重计数,名字和数学成绩都相同的去重后,剩余992个。
A |
|
2 |
=score.icount([Name,Math] ) |
SQL:
SELECT
COUNT(*)
FROM (
SELECT DISTINCT Name, Math FROM score
)
分组后组内去重计数
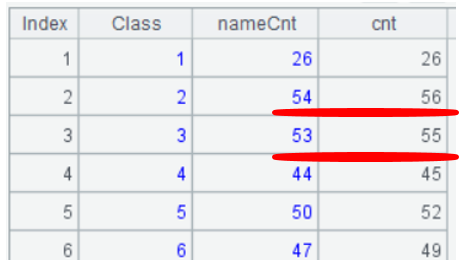
icount()函数还可以用在分组函数groups内,这样组内也能实现去重计数,看到2班56个人有54个姓名,3班55个人有53个姓名。
A |
|
2 |
=score.groups( Class ; icount(Name):nameCnt , count(Name):cnt ) |
SQL:
SELECT
Class
, COUNT(distinct Name) AS nameCnt
, COUNT(Name) AS cnt
FROM score
GROUP BY Class
TOP-N
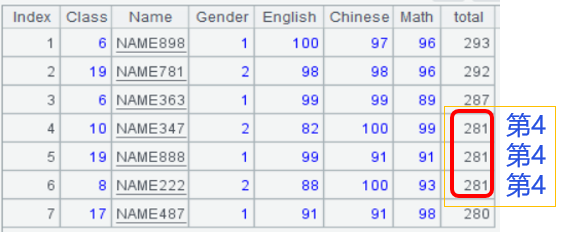
取前几名的计算也比较常见,top()函数取前N条记录,第一个参数是负数,表示倒序,-5会取total最大的5条记录,如果是正数5,会取total最小的5条记录。找前N名时,重复值默认会占用名次,如第4、5名都是281分。
A |
|
2 |
=score.derive((English+Chinese+Math):total) .top(-5;total) |
SQL:
SELECT
TOP 5
*, (English+Chinese+Math) as total
FROM score
ORDER BY (English+Chinese+Math) DESC
如果想让重复值不占名次,可以用@i选项,前5名中,第4名有重复值,共三个人,那前5名一共查出7人。
***.top@i(-5;total)
找最大、最小的记录,还可以用maxp,minp函数,它们分别等价于top 1,top -1。
最大 ***.maxp(total) = top(1,total) :

最小 ***.minp(total) = top(-1,total)

组内TOP-N
要查出各班的前5名,可以在group()函数内使用top函数,
A |
|
2 |
=score.derive( (English+Chinese+Math):total ).group(Class;~.top(-5;total)) |
如图得到的各班前5名是一个个子集合,点开3班,能看到3班的前5名。
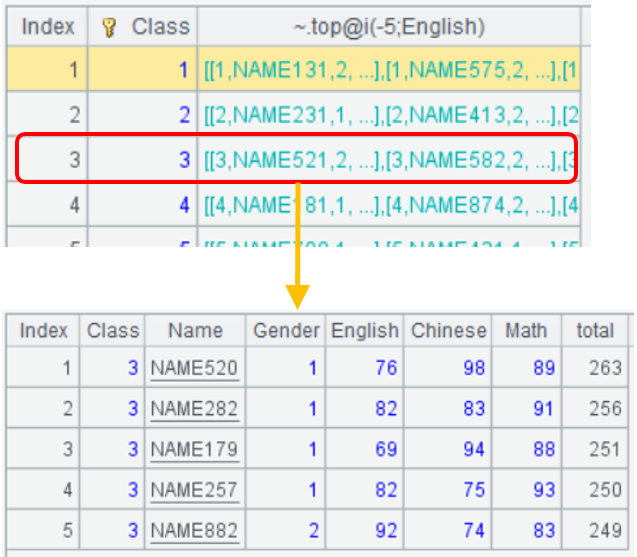
groups()和group()函数都是做分组的,简单说,前者是分组后直接计算出一些汇总值,后者做分组后得到各个分组子集合,子集合可以再灵活定义更多计算,不一定总是做聚合。
SQL:
SELECT
* , (English+Chinese+Math) AS total ,
RANK OVER(
PARTITION BY Class ORDER BY
English+Chinese+Math DESC
) AS rank
FROM score WHERE rank <= 5
更多函数-日期计算
对不同类型数据SPL提供了很多相关的计算函数。基于 send 和 receive 两个日期字段列举了一些计算。能获得年、月、日、星期几,能计算两个日期相差多少天、相差多少周,能计算出一个日期后第多少天的新日期。
基于计算send (发送时间) :2023-12-03 15:12:23,receive(接收时间):2024-03-15 11:12:30:
year(send) = 2023
month(send) = 12
day(send) = 3
day@w(send) = 1 , 星期日
interval(send, receive) = 103,相差103天
interval@w(send, receive) = 14,相差14周
elapse(send,50) = 2024-01-22 15:12:23,50天后
……
更多函数-字符串计算
字符串类型数据也有很多计算函数,多个字符串可以用concat拼接在一起、判断是否所有字符都是小写字母、转换成小写、截取左右或中间的子串、用通配符匹配字符串、替换字符串、用某些字符随机生成特定长度的新字符串。
基于first(名字):John,last(姓氏):Smith计算:
concat(first,last) = JohnSmith
concat(first, " ", last) = John Smith
islower(last) = false
lower(last) = smith
left(last,3) = Smi
mid(last,2,4) = mith
like(last, "*th") = true
replace(last, "th", "??") = Smi??
rands(“abcdefg12345“,5) = 4d32d
……
更多函数-转换成日期类型
SPL提供了日期时间、各种数值、字符串类型之间转换函数,目标类型作为函数名,函数会自动判断原始数据类型,正确的转成目标类型。比如日期函数date(),传入整数的年月日、字符串日期都可以,还可以指定字符串日期的解析格式,最终都能得到一个日期。
date(1982 , 8 , 9) = 1982-08-09
date("1982-08-09") = 1982-08-09
date("1982-08-09 12:15:30") = 1982-08-09
date("08/09/1982" , "MM/dd/yyyy") = 1982-08-09
date("9, Aug 1982" , "d MMM yyyy" : "en") = 1982-08-09
datetime("1982-08-09 13:15:30") = 1982-08-09 13:15:30
datetime("9 Aug 1982 1:15 PM" ,
"d MMM yyyy h:mm a" : "en") = 1982-08-09 13:15:00
time("13:15:30") = 13:15:30
time("13/15/30” ,"HH/mm/ss") = 13:15:30
time("1:15 PM", "h:mm a" : "en") = 13:15:00
……
更多函数-转换成数值类型
数值类型比较多,包括整数int、长整数long、双精度浮点数float、实数number、大浮点数decimal,除了各种数值类型之间互相转换,还可以把字符串、日期类型转换成数值。
int("68") = 68
int("68.73") = 68
int(68.73) = 68
int(3.1*3.2) = 9
float("68.73") = 68.73
float(68) = 68.0
number("68f") = 68.0
number("$1,100.05", "$#,###.##") = 1100.05
long("68.73") = 68
long(now()) = 1727677043202
decimal(1232456523427854423905234234)
……
更多函数-转成字符串类型
把日期时间、数值转换成字符串时,也可以指定格式。
string(123) = "123"
string(now(), "MMM dd, yyyy") = "Sep 30, 2024"
string(1100.05 , "$#,##0.00") = "$1,100.05"
string(datetime("1982-08-09 13:15:30"), "d MMM yyyy h:mm a" : "en") = "9 Aug 1982 1:15 PM“
…….
更多函数去查官方文档https://doc.raqsoft.com.cn
关联的分类
我们再来看涉及多个文件关联的运算。
SPL看待关联和SQL不太一样,它把关联区分为外键关联和主键关联两类。
比如,学生表的City外键到城市表主键CityID,这种是外键关联,学生表的普通字段Class、School分别外键到班级表的主键ClassID、SchoolID,这种两字段、以及多字段关联,也是外键关联。
学生表用主键关联到学生健康表的主键StudentID,这种称为主键关联,这两表是一对一的关系,也称为同维表。
学生表用主键关联到学生缴费表的部分主键StudentID,这也属于主键关联,这两表是一对多的关系,也称为主子表。
基于不同关联特点,SPL用不同的函数区别实现关联。
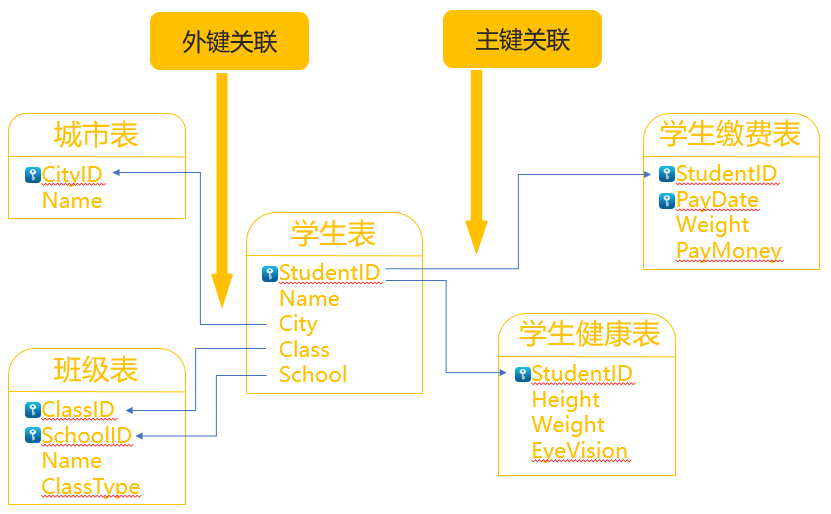
关联运算涉及多个文件,类似的,我们在A1中可多个文本都加载成SPL序表变量,方便后续计算。
A |
|
1 |
>student=T("student.txt"), city=T("city.txt"), class=T("class.txt"), stu_pay=T("stu_pay.txt"), stu_health=T("stu_health.txt") |
外键关联计算
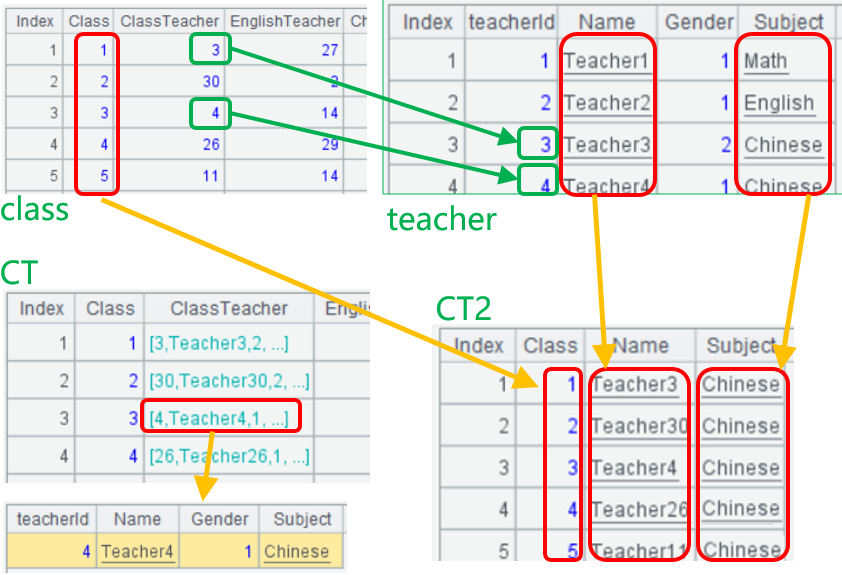
class.txt里记录班级班主任老师ID,英语老师ID等信息,teacher.txt记录老师姓名、性别、所教科目。
想要查出班主任是语文老师的班级,就需要用class.txt的ClassTeacher关联teacher.txt的teacherId。
SPL用switch()方法实现两表连接,A2计算过程中,涉及四个序表,class.txt加载为序表class,teacher.txt加载为序表teacher,然后用switch()函数把teacher的相关记录替换为class的ClassTeacher字段值,算出CT序表,SPL序表的字段值允许是记录、甚至子序表这样复杂的数据类型,CT就是这种多级嵌套序表。
从嵌套的子记录中获得数据也不难,如由CT new()出简单结构的CT2时,ClassTeacher.Subject就得到班主任老师所教科目,最后用select()函数查出语文科目。
A |
|
2 |
>CT=class.switch( ClassTeacher ,teacher:teacherId ) ,CT2=CT.new( Class , ClassTeacher.Name , ClassTeacher.Subject ).select(Subject=="Chinese") |
SQL:
SELECT
C.Class ,T.Name ,T.Subject
FROM
class C JOIN teacher T
ON C.ClassTeacher=T.treachId
WHERE T.Subject="Chinese"
多级外键关联
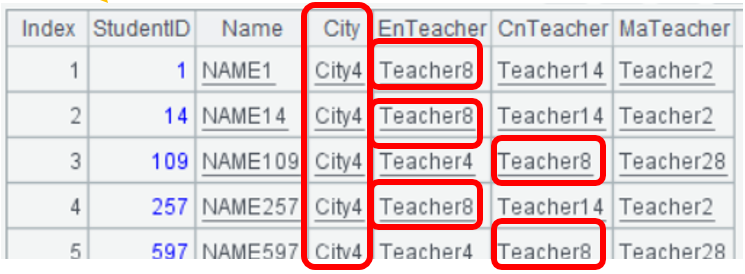
student表的FromCity字段外键到city表,ClassID字段外键到class表,class表中英语、语文、数学三科老师字段都外键到teacher表。
student表有两个外键字段,class表有三个。同时还存在student表关联class表、class表又关联teacher表这样的多级关联。
要查来自City4并且老师是Teacher8的学生,需要四表关联在一起查询,switch()函数支持同时关联多个外键表,如A2中先把class表关联好三科老师,A3中再关联city表及A2的class表,A3关联后的结果是一个结构更复杂的多级序表,能比较形象的展现关联结果。
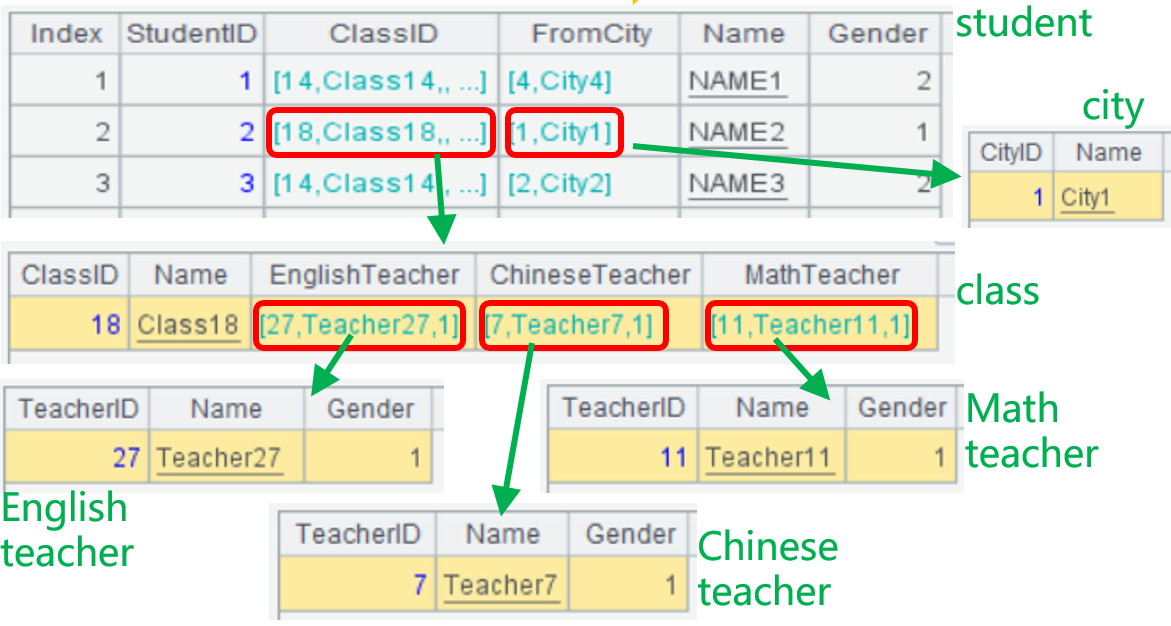
最后A4中用new()函数从各级序表中取出需要的信息,过滤出来自City4且老师为Teacher8的学生。
A |
|
2 |
=class.switch( EnglishTeacher, teacher:TeacherID ; ChineseTeacher, teacher:TeacherID ; MathTeacher, teacher:TeacherID ) |
3 |
=student.switch( ClassID, A2 : ClassID ; FromCity, city : CityID ) |
4 |
=B2.new(StudentID, Name ,FromCity.Name : City ,ClassID.EnglishTeacher.Name : EnTeacher ,ClassID.ChineseTeacher.Name : CnTeacher,ClassID.MathTeacher.Name : MaTeacher ).select(City=="City4" && (EnTeacher=="Teacher8" || CnTeacher=="Teacher8" || MaTeacher=="Teacher8")) |
SQL:
SELECT
s.StudentID, s.Name, c.Name AS city, en.Name AS EnTeacher,
cn.Name AS CnTeacher, ma.Name AS MaTeacher
FROM
student s JOIN city c JOIN class cl
JOIN teacher en JOIN teacher cn JOIN ma
ON
s.FromCity=c.CityID AND s.ClassID=cl.ClassID AND cl.EnglishTeacher=en.TeacherID
AND cl.ChineseTeacher=cn.TeacherID AND cl.MathTeacher=ma.TeacherID
WHERE
City="City4" AND
(EnTeacher="Teacher8" OR CnTeacher=“Teacher8” OR MaTeacher=“Teacher8”)
多字段外键关联
switch()函数适合单字段外键关联,多字段关联时,用join()函数。
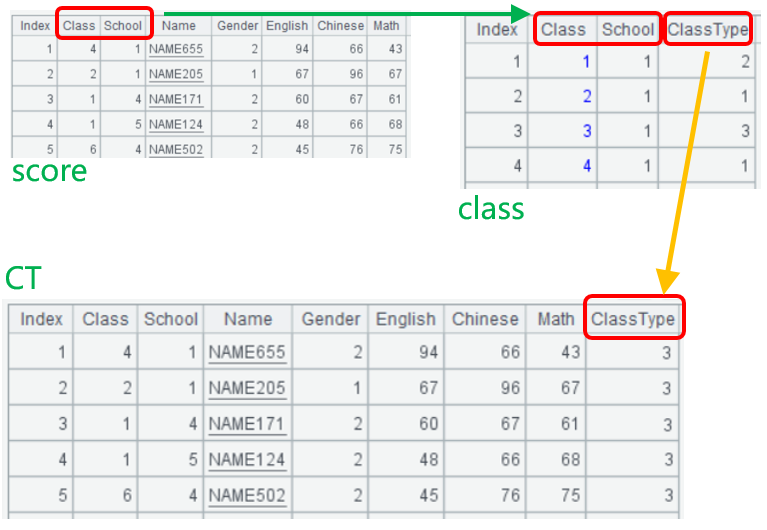
score表中增加School列,记录5个学校30个班的成绩,每个学校有6个班。class表记录这30个班,主键是Class、School两个字段,班级分类管理,分为1类班、2类班、3类班。
现在要查出所有3类班的学生成绩,join()函数的参数中,第一个逗号前是多个外键字段,Class和School,第二个逗号前是被关联表class,及其多个主键字段Class和School,再之后是从被关联表选出的目标字段,可以是多个,我们这里只选出了一个ClassType字段。
switch()函数是单字段关联,支持多表,结果是嵌套的多级序表。
join()函数能支持多字段关联,但不支持多表,结果是把两表字段直接连接起来,形成一个单层结构序表。
A |
|
2 |
>class=class.select(ClassType==3) |
3 |
>CT=score.join( Class:School ,class:Class:School ,ClassType ) |
SQL:
SELECT
s.*, c.ClassType
FROM
score s JOIN class c
ON s.Class=c.Class
AND s.School=c.School
WHERE c.ClassType=3
同维表-主键关联
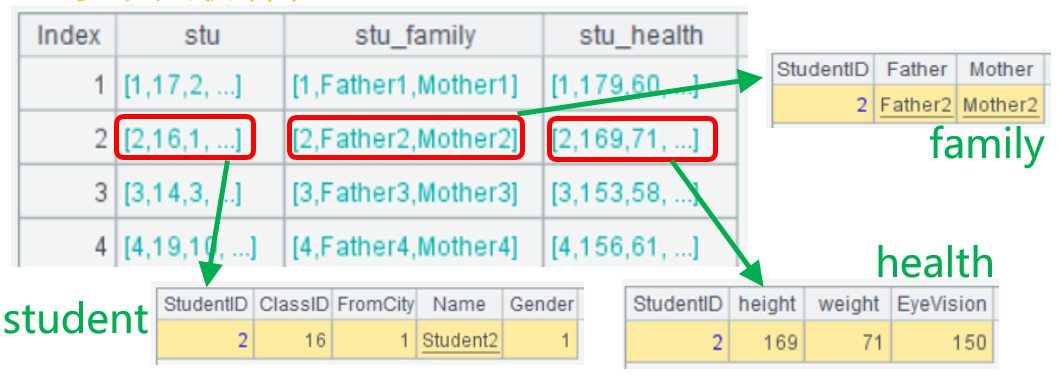
student表、family表、health表主键都是StudentID,三表是一对一的同维表关系,后面两表是学生不同方面的补充信息。
主键关联要用新的关联函数,形如join(A, B, C),参数中定义多个被关联表的信息:被关联表(student)、关联后序表中的字段名(stu)、关联主键(StudentID)。
观察A2关联后的结果,StudentID为2的三表记录关联到一起了。
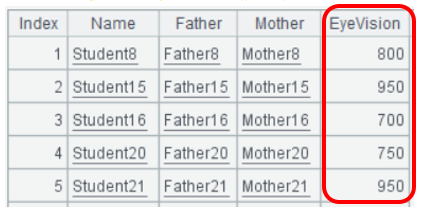
A2关联后,A3过滤出眼睛近视度数超过500度的学生及家长。
A |
|
2 |
=join( student : stu , StudentID; family : stu_family , StudentID; health : stu_health , StudentID ) |
3 |
=A2.new(stu.Name, stu_family.Father , stu_family.Mother, stu_health.EyeVision) .select(EyeVision>500) |
SQL:
SELECT
stu.Name, stu_family.Father
, stu_family.Mother, stu_health.EyeVision
FROM
student stu
JOIN family stu_family
JOIN health stu_health
ON stu.StudentID=stu_family.StudentID
AND stu.StudentID=stu_family.StudentID
WHERE sty_health.EyeVision>500
主子表-主键关联
另外一种主键关联是主子表,学生缴费表pay是子表,它是StudentID和PayDate双字段组合主键,用其中StudentID外键到主表student主键。
主子表也用join()函数关联,一个学生有5条缴费记录,每条缴费记录都和主表的学生记录关联了起来。
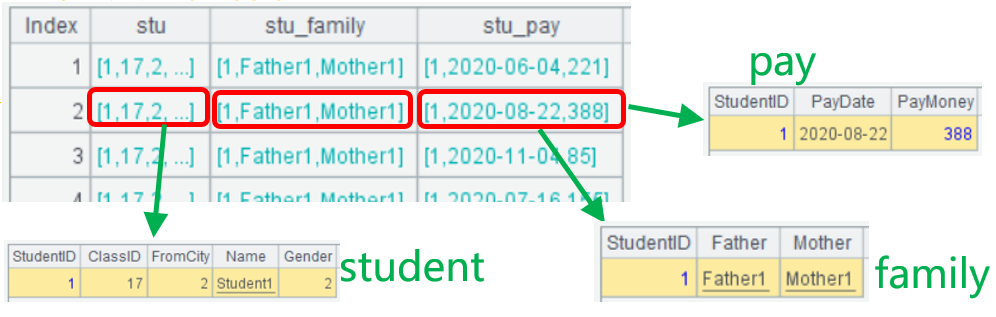
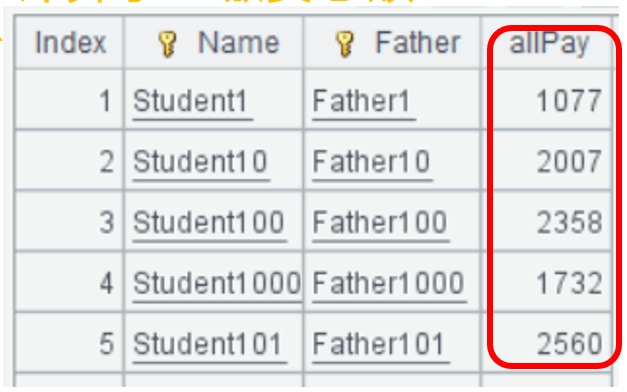
A2关联后,A3用groups()函数计算出每个学生的缴费总额。
A |
|
2 |
=join( student : stu,StudentID; family : stu_family,StudentID; pay : stu_pay,StudentID ) |
3 |
=A2.groups( stu.Name, stu_family.Father; sum(stu_pay.PayMoney):allPay ) |
SQL:
SELECT
stu.Name, stu_family.Father,
sum(stu_pay.PayMoney):allPay
FROM
student stu
JOIN family stu_family
JOIN pay stu_pay
ON stu.StudentID=stu_family.StudentID
AND stu.StudentID=stu_pay.StudentID
GROUP BY stu.Name, stu_family.Father
还有更多
以上就是SPL做结构化文本计算的内容,对于这类数据库外的数据,也有了简便、强大的计算方案。
这里涉及的例子都是能读入内存的小数据,可以下载测试文本尝试。对于大于内存的文件,SPL也提供了游标方案来计算,感兴趣的小伙伴可以参考SPL的官方文档。
当然,SPL的能力还远不止于此,SPL还支持JSON、XML等多种文本格式、跨多种数据库查询、支持数据库与其他非数据库混合计算,针对大数据或复杂计算,可以借助SPL的计算能力对SQL进行性能优化,这些内容我们会在后面的专题逐渐介绍。
SPL是开源软件,可以从https://github.com/SPLWare/esProc获取源码。


英文版