


新手如何理解 SPL 运算
作为结构化计算引擎,SPL 带来了很多全新的概念,其内容远远超出以关系代数为基础的传统体系。熟悉 SQL 或者 Java 的同学,初次接触 SPL 时对此比较陌生,参考本文可以准确理解这些新概念,快速掌握 SPL 的关键概念。
离散性及普遍集合
在 SPL 中,记录是一种基本数据类型,数据表是记录构成的集合。构成数据表的记录可以游离于数据表之外独立、反复使用,我们称为游离记录。
比如要计算员工表中的 Jack 和 Rose 的年龄差和工资差,SPL 的代码大致是这样的:
A |
B |
|
1 |
=file("employee.btx").import@b(name,age,salary) |
|
2 |
=A1.select@1(name=="Jack") |
=A1.select@1(name=="Rose") |
3 |
=A2.age-B2.age |
=A2.salary-B2.salary |
A2 和 B2 分别按照条件过滤出需要的记录,这两条记录游离于员工表之外,可以独立使用。在 A3、B3 中,就是使用这两条游离记录完成了多次计算。
需要注意的是,游离记录 A2、B2 并不是将原记录另外复制一份,而是直接引用了原记录。这样做可以避免复制过程消耗额外的时间,而且可以减少空间占用。
SPL 的游离记录还可以通过计算构成新集合,也就是新数据表。比如常见的交集、并集、差集等集合运算。仍以员工表为例,下面的SPL 代码可以计算出多种集合运算结果:
A |
B |
|
1 |
=file("employee.btx").import@b(name,dept,gender,salary) |
|
2 |
=A1.select(gender=="F") |
=A1.select(salary>=4000) |
3 |
=A2^B2 |
=A2\B2 |
4 |
=A2&B2 |
|
A2 和 B2 分别过滤取出了女员工和薪酬在 4000 及以上的员工,构成了两个新的集合。
A3 对两个集合求交集,结果是薪酬在 4000 及以上的女员工。B3 对两个集合求差集,结果是薪酬在 4000 以下的女员工。A4 对两个集合求并集,结果是全部女员工和薪酬在 4000 及以上的男员工。这些集合运算都有实际的业务意义。
而且,参加这些集合运算的都是 A1 序表的游离记录,没有发生记录的复制。
实际上,上面这种游离记录的观念在 Java 和 C++ 等高级语言中很常见,但 SQL 却没有。
SQL 的理论基础关系代数定义了丰富的集合运算,但是离散性非常差,没有游离记录。Java 等高级语言没有离散性的问题,但是对集合运算的支持却很差。SPL 集中了 SQL 和 Java 两者的优势,将离散性和集合化结合起来,既有集合数据类型及相关的运算,也有集合成员游离在集合之外单独运算或再组成其它集合。
离散性和集合化非常重要,这也是 SPL 的理论基础被命名为“离散数据集”的原因,初学 SPL 的同学要重点理解这两个概念。SPL 在离散性的支持下,提倡普遍集合,并应用于分组、聚合、有序和关联等多种运算场景,下面我们将在相关内容中分别介绍。
Lambda 语法
和 SQL 类似,SPL 也提供了 Lambda 语法,并且进行了扩展,掌握 SPL 的 Lambda 语法对于熟悉使用它非常重要。
如果普通函数 f(x) 的参数是表达式,那么执行的时候会先将表达式计算好,然后再计算函数 f。比如 max(3+5,2+1),要先计算好 3+5 和 2+1 再计算 max(8,3)。如果参数中含有变量,类似 max(x+5,y+1) 这样的表达式,在 x 和 y 没有被赋值时是无法计算的,而 x 和 y 被赋值后也会把 x+5 和 y+1 先计算出来再传入给 max 函数去计算。
但是,有些函数的参数表达式无法提前计算出来。比如前面用 A1.select(gender=="F") 函数来过滤性别为女的员工,gender=="F" 在执行 select 函数之前是无法计算的。这是因为 gender 在对 A1 这个集合的成员做循环计算的时候才能确定,然后才能计算这个表达式。
这时,我们是将整个表达式作为参数传递给 select 函数去执行的,也就是定义了一个临时函数作为 select 函数的参数,这种写代码的方法称为Lambda 语法。类似 select 这样的函数,SPL 称为循环函数。循环函数的本质特征是以函数为参数。
SQL 在针对数据表运算时可以将表达式作为语句的参数,实现了基本的 Lambda 语法。比如:
select * from employee where gender='F'
WHERE 条件中的表达式 gender='F',也不是在执行这个语句之前先计算好的,而是在遍历时针对每条记录计算的,对于 WHERE 运算而言,相当于把一个用表达式定义的函数作为了 WHERE 的参数。
SPL 进一步丰富了 Lambda 语法,可以针对任何集合使用,而且,还提供了符号用于引用当前成员及其序号以及相邻成员,这样可以进一步简化代码的书写。
比如集合中存储了某公司 1 到 12 月的销售额,我们可以做下面这样的计算:
A |
|
1 |
=[820,459,636,639,873,839,139,334,242,145,603,932] |
2 |
=A1.select(#%2==0) |
3 |
=A1.(if(#>1,~-~[-1],0)) |
A2 过滤出偶数月份的销售额,A3 则计算每月销售额的增长值。
其中的 #表示循环计算时当前成员的序号。~ 表示当前成员,~[-1] 表示当前成员的上一个成员。一般的,[-i] 表示当前成员向前 i 个成员,[i] 则表示向后 i 个成员。
数据表也是集合,同样可以使用 ~、# 和 [] 符号直接引用集合中的成员。比如某公司月销售表,除了 12 个月销售额之外,还有每个月的综合成本,我们可以做下面这些计算:
A |
|
1 |
=file("sales.btx").import@b(month,sales,costs) |
2 |
=A1.(~.sales-~.costs).min() |
3 |
=A1.(if(#>1,~.sales-~[-1].sales,0)).max() |
A2 计算销售额和成本之差的最小值。A3 计算销售额每月增长的最大值。
对于数据表来说,集合的成员就是记录,所以当前记录的字段要写成 ~.sales。很多情况下 ~ 可以省略,比如 ~.sales-~[-1].sales 可以写成 sales-sales[-1]。
关于 ~、#、[] 等符号的深入思考,可以参考 【程序设计】5.7 [一把抓] Lambda 语法。
JAVA 语言中出现的 Stream 和 Kotlin 也开始支持 Lambda 语法,但没有针对结构化数据做特殊设计,只能把当前记录作为参数传入用 Lambda 语法定义的函数,引用当前成员的字段时,总要带上这个记录。比如用销售额和成本计算利润时,如果用于表示当前成员的参数名为 x,则需要写成 “x.sales - x.costs”,不能直接写字段名。JAVA 也没有 SPL 的 ~,#,[] 符号。
有序性和位置利用
SPL 数据表是个有序集合,其中的记录按顺序从 1 开始编序号,记录的序号表示该记录在有序集合中的位置,这就是有序性。
利用有序性,我们可以用序号来访问某个位置上的记录,还可以对相邻的记录做计算。比如预先将某只股票的股价数据按照交易日期有序存储,利用位置计算的 SPL 代码就是下面这样:
A |
B |
|
1 |
=file("stock.btx").import@b(sdate,price) |
|
2 |
=A1(1) |
=A1.m(-1) |
3 |
=A1.pselect@1(sdate==date("2022-10-11")) |
|
4 |
=A1.m(A3-1) |
= A1.m(A3).price- A4.price |
5 |
=A1.derive(~.price-~[-1].price) |
|
A2 取得第一条记录,是第一个交易日的数据。B2 取得最后一条记录,是最近一个交易日的数据。m() 函数的参数为负数表示倒数第几个成员。
A3 查找 2022-10-11 的记录序号。A4 按序号取出 A3 的前一条记录,是上一个交易日数据。B4 计算 2022-10-11 价格比上一个交易日涨了多少。
A5 计算每个交易日的价格比上个交易日上涨了多少。
有了有序性和位置利用,再加上 ~、# 和 [] 等符号,这些原本很难描述的计算,也变得非常简单、直观了。
有序性运算是典型的离散性与集合化的结合场景。次序的概念只有在集合中才有意义,单个成员无所谓次序,这体现了集合化;而有序计算又需要针对某个成员及其相邻成员进行计算,需要离散性。
关系代数是基于无序集合设计的,集合成员没有序号的概念,也没有提供定位计算以及相邻引用的机制。SQL 实践时在工程上做了一些局部完善,使得现代 SQL 能进行一部分有序运算。但是,很常见的有序运算却仍然是 SQL 的困难问题,即使在有了窗口函数后还是很繁琐。SPL 则大大改善了这个局面。
SPL 有序性是 SQL 没有的概念,也是初学者要重点学习的。利用有序性可以让复杂的计算变得很简单,也可以让很慢的计算变得飞快,后边的介绍会涉及到一些,更多内容请参考乾学院上的介绍。
分组和聚合理解
有了离散性和彻底的集合化,SPL 支持集合的集合。因此,SPL 可以实现更本质的分组运算,也就是将大集合按照一定规则分拆为若干子集合,分组结果是由这些分组子集组成的一个新集合。
很多情况下,分组后要对子集做聚合计算,比如求和、求平均、求最大值等等。但是,聚合并不是分组的唯一目的。比如我们想找出公司里有哪些员工和其他员工会在同一天过生日,很简单的思路是将员工按生日分组,然后找出成员数大于 1 的分组子集,再合并起来。这时候我们就不是只对聚合值(分组子集的成员数)感兴趣,而是对分组子集本身更感兴趣。在 SPL 中,分组的返回值是分组子集,意味着分组和聚合被拆分成了相互独立的运算,很容易完成这个思路,具体代码大致是这样的:
A |
|
1 |
=file("employee.btx").import@b(name,dept,birthday) |
2 |
=A1.group(month(birthday),day(birthday)) |
3 |
=A2.select(~.len()>1) |
4 |
=A3.conj() |
A2:对员工表这个大集合分组,结果是若干小集合,也就是分组子集。有了离散性的支持,分组子集仍然是原集合(员工表)的成员构成,记录并没有被复制。
由于人们一般认为两个人生日的月、日都相同就是同一天生日,所以这里的分组字段是生日的月、日。
A3:过滤出这些子集中有 1 个以上成员的,也就是有生日相同的员工。
A4:合并过滤的结果。
还有些情况下,要对一种分组方式计算出多种聚合值。由于 SPL 分组计算能得到并保持分组子集,我们可以利用这些分组子集,反复计算出多种聚合值。分组运算的成本不低,这样做可以避免重复计算分组,有利于提升计算性能。比如我们计算每个部门的人数,再计算出 10 人以上部门的人员平均工资。SPL 代码大致是这样的:
A |
|
1 |
=file("employee.btx").import@b(dept,salary) |
2 |
=A1.group(dept) |
3 |
=A2.new(~.dept,~.len()) |
4 |
=A2.select(~.len()>=10).new(~.dept,~.avg(salary)) |
A2:按照部门 dept 分组,结果是多个分组子集,每个分组子集就是一个部门的员工集合。
A3:循环计算出每个分组子集的部门和子集的成员个数。~ 符号代表 A2 分组结果中的当前行,也是就是一个分组子集。
A4:再次利用 A2 的分组结果,过滤出分组子集的成员个数大于等于 10 的,计算每个子集的 dept 和平均薪酬。
SPL 将分组和后续的聚合拆开,还可以应用在其他很多场景中。比如有些聚合需求很难计算,要对分组的结果再写段代码才能算出来;或者数据分组后,还要对分组子集再做分组的情况等等。
与 SPL 相比,SQL 没有显式的集合数据类型,无法返回集合的集合这类数据,不能实现独立的分组,就只能强迫分组和聚合作为一个整体来计算了。
SPL 将任何拆分大集合的方法都看作分组运算。除了常规的等值分组外,还提供了可能得到不完全划分结果的对位分组和枚举分组,请参考乾学院的其他文章进一步学习。
理解了离散性和集合化在分组运算上的应用,我们再来看有序性如何大幅提高分组计算的性能。通常的分组运算是用 HASH 算法实现的,如果我们确定地知道数据对分组字段有序,则可以只做相邻对比,避免计算 HASH 值,也不会有 HASH 冲突的问题,而且非常容易并行。在上一个例子中,如果我们预先将员工表按照部门排序存放,在分组计算时就可以仅比较相邻的记录,部门相同的归并成一组,这种方法称为有序分组。有序分组的复杂度降低了很多,性能提升非常明显。代码只要稍作修改:
A |
|
1 |
=file("employee.btx").import@b(dept,salary) |
2 |
=A1.group@o(dept) |
3 |
=A2.new(~.dept,~.len()) |
4 |
=A2.select(~.len()>=10).new(~.dept,~.avg(salary)) |
A2 group 函数使用 @o 选项,仅合并相邻的部门号做分组。
SPL 对聚合运算也有新的理解,聚合结果除了常见的单值 SUM、COUNT、MAX、MIN等之外,也可以是个集合。比如常常出现的 TOPN 计算,SPL 也看作和 SUM、COUNT 一样的聚合计算,既可以针对全集也可以针对分组子集。比如我们要计算员工表薪酬最低的 TOP10,还要计算每个部门薪酬最高的 TOP3,SPL 代码大致是下面这样:
A |
|
1 |
=file("employee.btx").import@b(name,dept,salary) |
2 |
=A1.top(10;salary) |
3 |
=A1.groups(dept;top(-3;salary):top3) |
4 |
=A3.conj(top3) |
A2 计算员工表的薪酬最低的 TOP10。A3、A4 计算每个部门的薪酬最高的 TOP3。
关系代数无法把 TOPN 运算看成是聚合,针对全集的 TOPN 只能在输出结果集时排序后取前 N 条,而针对分组子集则很难做到 TOPN,需要转变思路拼出序号才能完成。SPL 把 TOPN 理解成聚合运算后,在工程实现时还可以避免全量数据的排序,从而获得高性能。而 SQL 的 TOPN 总是伴随 ORDER BY 动作,理论上需要大排序才能实现,只能寄希望于数据库在工程实现时做优化。
游标
为了处理大数据,SPL 也提供有游标,其基本功能和数据库游标有类似之处,都是按顺序读取数据。不同点是,SPL 是从文件中读取,每次可以读取一批数据。比如要统计订单表的总金额、总笔数和平均金额,SPL 采用循环读取订单表游标的代码大致是这样的:
A |
B |
C |
|
1 |
=0 |
=file("orders.ctx").open().cursor(amount) |
=0 |
2 |
for B1,10000 |
>A1+=A2.len() |
|
3 |
>C1+=A2.sum(amount) |
||
4 |
=C1/A1 |
除了循环读取数据的基本能力之外,SPL 游标提供了比 SQL 游标更强大的功能。比如 SPL 定义了丰富的游标函数,可以在游标上附加各种运算,要计算金额大于 5000 的订单总金额和订单数,SPL 代码可以写成这样:
A |
|
1 |
=file("orders.ctx").open().cursor(amount) |
2 |
=A1.select(amount>5000) |
3 |
=A2.groups(;sum(amount):S,count(amount):C) |
4 |
=A3.S/A3.C |
A2、A3 在游标上附加了两个步骤的计算:先过滤出金额大于 5000 的订单,再求总金额和总数。
虽然游标是外存计算,和内存计算本质上是不同的。但是,从这个例子可以看出,SPL 游标函数设计的尽量和内存函数很像,这样在学习和编程上都会方便很多。
需要初学者重点理解的是,这个例子 A2 中的 select 函数并不会真的将金额大于 5000 的订单先过滤出来,只是在游标上定义了过滤计算。等到下一步 groups 函数遍历数据的时候,SPL 才会执行预先定义好的 select 动作,也就是读入一批数据先做过滤再做汇总,然后再读入下一批数据。
我们称 select 函数返回的这种游标为延迟游标,它只有在真正取数据时才会执行实质性的计算。而 groups 函数则会立即触发游标遍历动作,且返回的也不再是游标,称为立即计算。学习游标函数时,要了解其返回值,知道它是不是延迟游标。
延迟游标的好处是中间结果不用落地。比如这个例子中的过滤计算如果先算出结果,可能内存仍然装不下,只能写硬盘供下一步计算读取。而读写硬盘的时间会很慢,远远不如延迟游标的计算性能。
与数据库游标相比,SPL 还支持多路游标,很容易实现并行计算;支持遍历复用,可以对游标遍历一次时计算出多种结果。还有针对复杂计算的程序游标和支持横向扩展的集群游标等等,在乾学院中都有详细的介绍。
连接理解
SQL 对 JOIN 的定义是两个集合(表)做笛卡尔积后再按某种条件过滤。这种过于简单的定义无法充分体现不同 JOIN 的运算特征,在运算较为复杂时,无论书写还是优化都非常困难。
实际应用中,绝大多数 JOIN 都是等值关联,也就是关联条件为等式的 JOIN。SPL 将等值 JOIN 运算分成外键关联、同维表关联和主子表关联三种情况分别处理,由程序员根据不同的场景来选择使用不同的计算方法。这样做可以体现数据之间的关联特征,并能针对不同的特征采取不同的手段,有效简化语法、提高性能。
外键关联是指用一个表的非主键字段,去关联另一个表的主键,前者称为事实表,后者为维表。比如下图中的订单表是事实表,客户表、产品表、雇员表是维表。
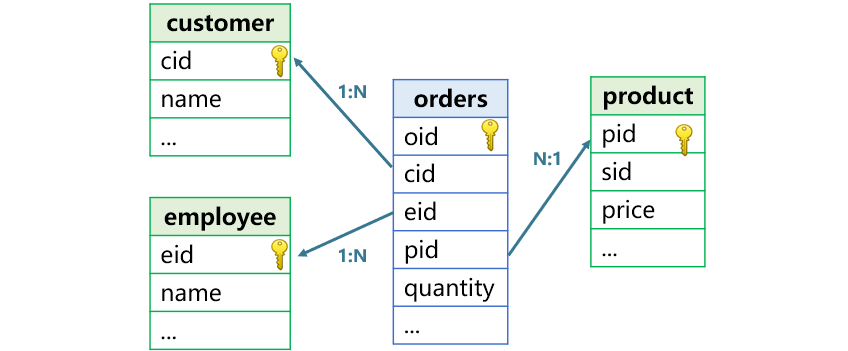
对于外键关联计算,SPL 提供了一个自然直观的办法:外键地址化。将订单表和雇员表关联后,按照雇员姓名和订单日期来过滤订单数据的代码就是下面这个样子:
A |
B |
|
1 |
=file("employee.btx").import@b().keys@i(eid) |
=file("orders.btx").import@b() |
2 |
>B1.switch(eid,A1:eid) |
|
3 |
=B1.select(eid.name=="Tom" && odate=…) |
|
A2中,将订单表中的雇员(eid)字段转换为雇员表的一条记录,也就是完成了外键地址化。A3 计算时就可以用 eid.name 来引用这条记录中的姓名字段,其中的点操作符含义是地址引用。
同维表关联是指两个表通过主键关联。比如下图中员工表和经理表就互为同维表,员工表的主键 eid 和经理表的主键 mid 关联,有部分员工是经理,eid 和 mid 都是员工编号。同维关联是一对一的关联。
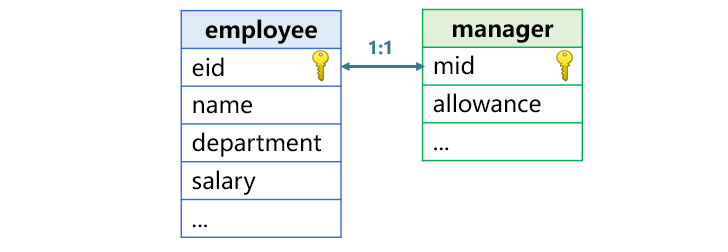
SPL 用 join 函数来实现同维表连接。比如要查询每个员工(包括经理)的编号、姓名和总收入(工资加津贴),代码是这样的:
A |
B |
|
1 |
=file("employee.btx").import@b().keys(eid) |
=file("manager.btx").import@b().keys(mid) |
2 |
=join@1(A1:e,eid;B1:m,mid) |
|
3 |
=A2.new(e.eid:eid,e.name:name,e.salary+m.allowance:income) |
|
主子表关联是一个表的主键去关联另一个表主键的一部分,比如下图中订单表主键是订单号 oid,明细表主键是订单号 oid 和产品号 pid 两个字段。订单表的主键 oid 与明细表的部分主键 oid 关联。订单表是主表,明细表是子表,两者是一对多关系。
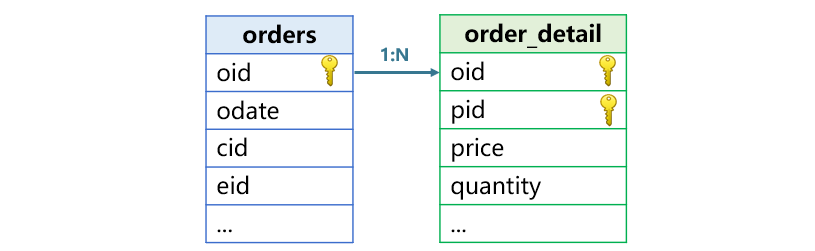
主子关联时 SPL 也使用 join 函数来处理。比如我们想计算每个客户的订单总金额,代码是这样的:
A |
B |
|
1 |
=file("orders.btx").import@b() |
=file("order_detail.btx").import@b() |
2 |
=join(A1:o,oid;B1:od,oid) |
|
3 |
=A2.groups(o.cid:cid;sum(od.price*od.quantity)) |
|
与同维表关联不同的是,oid 只是明细表的部分主键,明细中可能会有 oid 相同的多条记录。这时候 join 函数的结果中订单记录会重复出现,每一条明细记录都会关联一条订单记录,而每一条订单记录则会关联多条明细记录,最后的结果的记录数和明细表相同。
SQL 对多种 JOIN 场景笼统的处理,而 SPL 则要区别对待,对不同的 JOIN 采用不同的函数来计算,大数据场景下做 JOIN 的性能优化时也需要采用不同的手段甚至不同的存储方式。初学 SPL 的同学要重点理解 SPL 对连接运算的新观念,在需要做连接运算时,识别出 JOIN 属于什么类型,再选择相应的方法实现。更详细的内容参见乾学院的相关介绍。


英文版
👍