


SPL 虚表的数据类型优化
物理上存储数据的表(简称物理表)往往会采用一些有利于提升性能、减小空间占用的存储机制。
但是,这些机制往往会降低数据可读性,且增加使用的复杂度。比如用整数代替枚举值,或者用整型字段的二进制位存储布尔值。整数、二进制位没有字符串和布尔型那么容易读懂,而且我们还要为这些物理值编写类型转换、二进制计算等代码。
SPL虚表是定义在物理表上的逻辑表,我们可以在虚表中定义更方便使用的逻辑字段。这样的逻辑字段称为伪字段,而物理表中真实存在的字段称为真字段。
虚表通过伪字段和真字段的映射,将特殊的存储结构封装起来,实现了物理表存储机制的透明化。这样既有利于减小磁盘占用、提高性能;又能方便人们读懂数据,降低使用复杂度。
下面我们详细介绍虚表中不同类型的伪字段用法。
枚举维度
在实际应用中,很多枚举类型字段的取值范围是字符串集合。物理表中一般会用整数来代替字符串。整数比字符串占用空间小、运算速度快,但却无法像字符串那样容易被人读懂和使用。
如果将字符串和数值一起存储下来可以兼顾性能和易用性。但这样做会增加生成数据的时间、占用更多的磁盘空间。有些情况下,还有可能出现字符串和数值不一致的错误。
例如交易明细这个物理表,数据结构大概是下图这样:
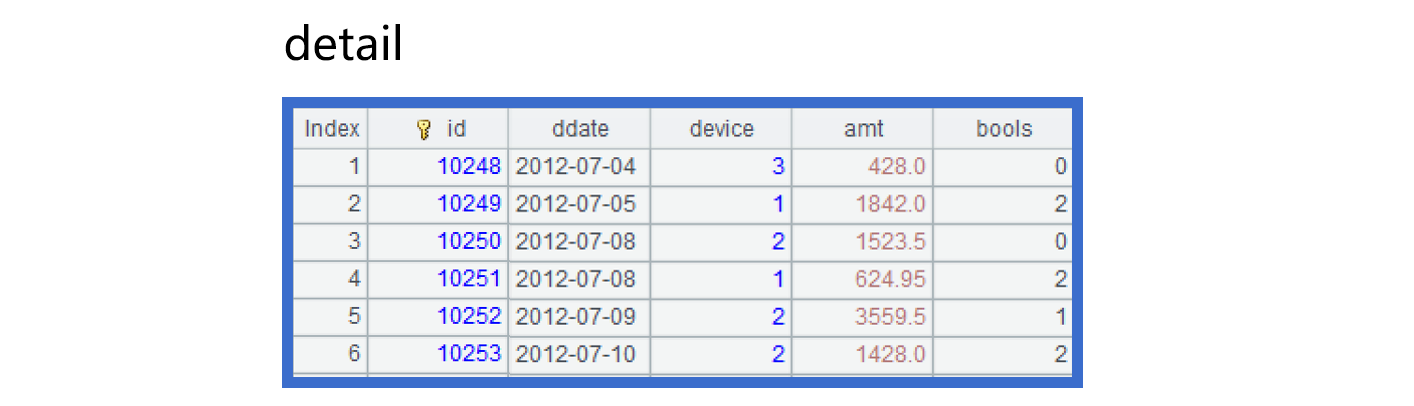
detail 表的枚举字段 device 中存储的是整数 1、2、3,分别对应三个设备类型 computer、smart phone、pad。现在要完成数据过滤计算,条件是本交易所使用的设备类型是智能手机或者平板电脑。再按照交易日期(年月)、设备类型等分组求总金额和笔数。结果集要以方便阅读的字符串方式展现。
这种情况可以使用虚表的枚举维度,用伪字段定义数值和字符串的对应关系。
定义枚举维度后,计算表达式中就能直接使用字符串,计算结果也能得到字符串。而物理表还可以继续存储数值以达到高性能目标。
下图中,虚表 p_detail 就定义了一个伪字段 deviceString 用于枚举维度的透明化:
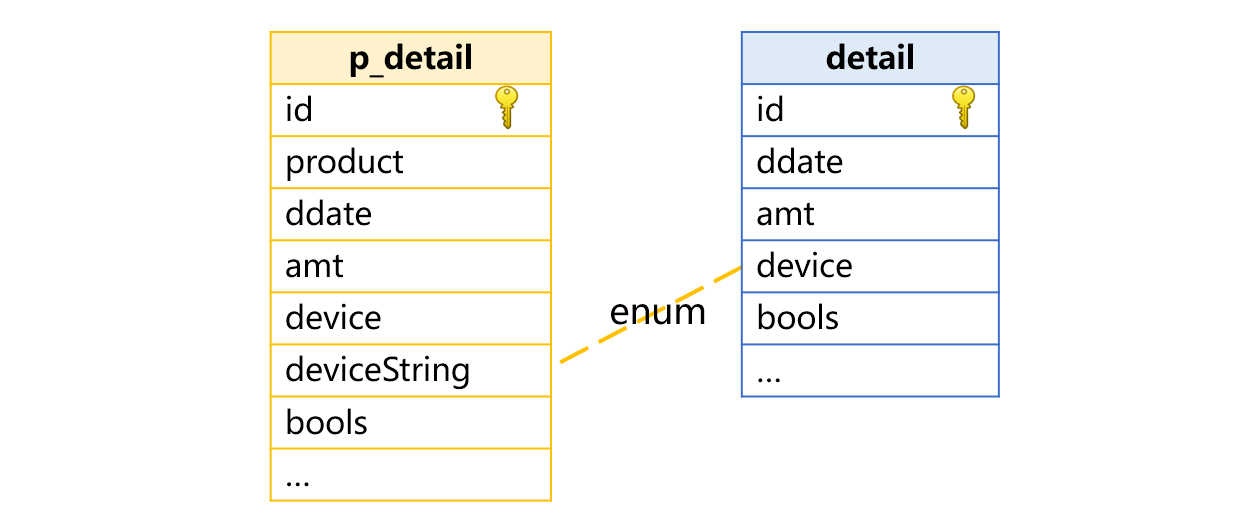
物理表 detail 没有 deviceString 字段,需要依据枚举集合 list 转换得来。本例中 list 为 ["computer","smart phone","pad"],其中的三个枚举值成员依次对应自然数 1、2、3。
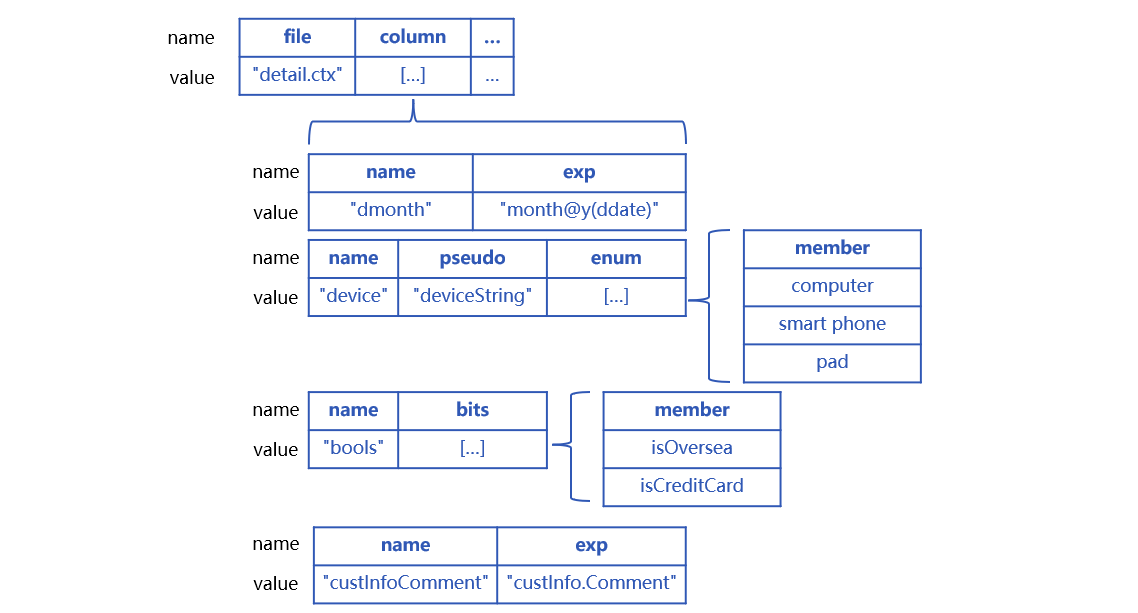
SPL 使用包含多个属性的结构来定义虚表,每个属性都有固定的名称。本例的虚表 p_detail 定义中要包含物理表名称、枚举维度 enum 名称,以及 list 集合,大致是下图这样:
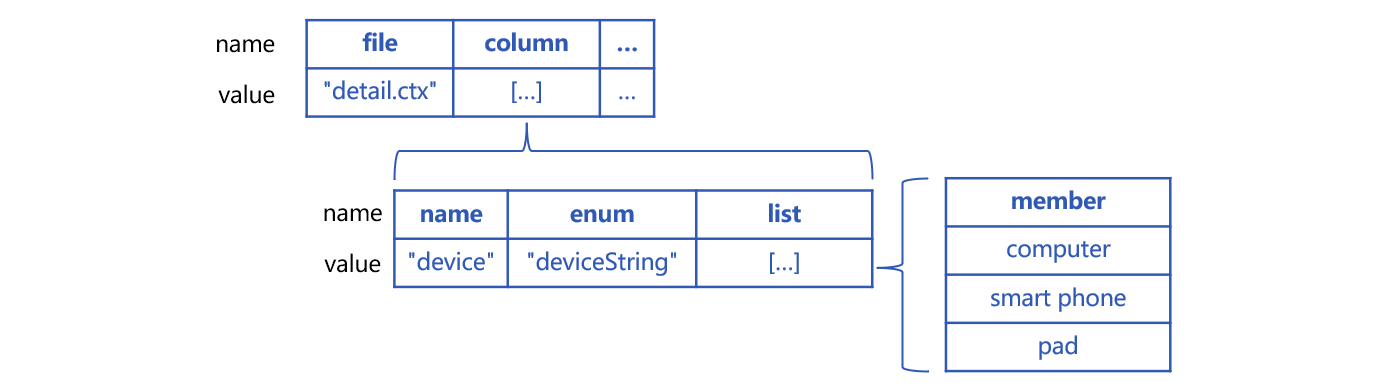
属性 file 是虚表对应物理表的名称,这里是组表 "detail.ctx";column 是特殊字段的集合,其中每个成员对应一个特殊字段。name 是真字段名称 device,enum 是伪字段名称 deviceString,list 枚举值取值集合是 ["computer","smart phone","pad"]。
SPL 定义虚表 p_detail 的代码大致是这样:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]} ] }] |
2 |
>p_detail=pseudo(A1) |
A1 准备一个虚表的结构,包含一个枚举类型的伪字段 deviceString。
A2 生成虚表 p_detail。
生成虚表之后,可以用游标 p_detail.cursor(id,ddate,device,deviceString,amt,bools).fetch(6) 取出虚表部分数据,大致是下图这样:
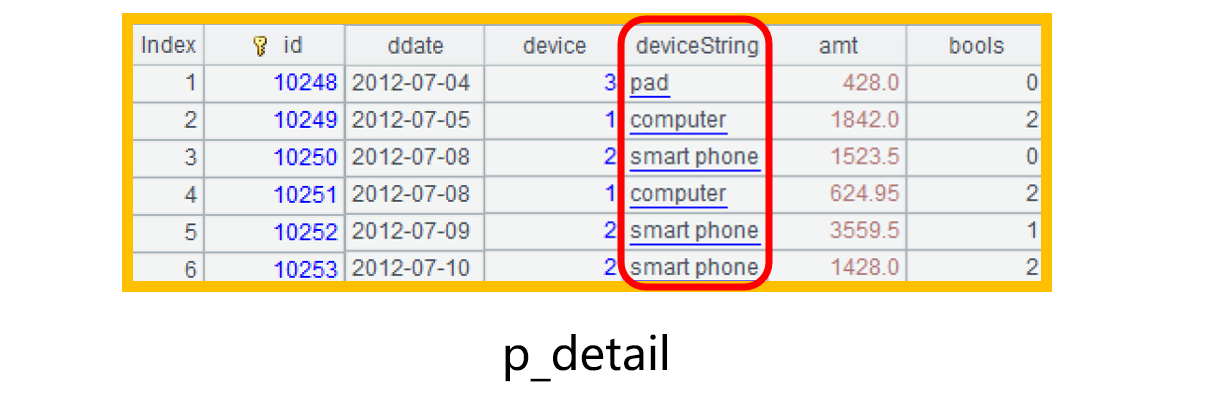
计算时将 p_detail 看作是一个简单的普通表,直接使用 deviceString 字段来做条件过滤和分组,并在结果集中显示字符串:
… |
|
3 |
=p_detail.select(deviceString=="pad" || deviceString=="smart phone") |
4 |
=A3.groups(month@y(ddate):dmonth,deviceString;sum(amt),count(~)) |
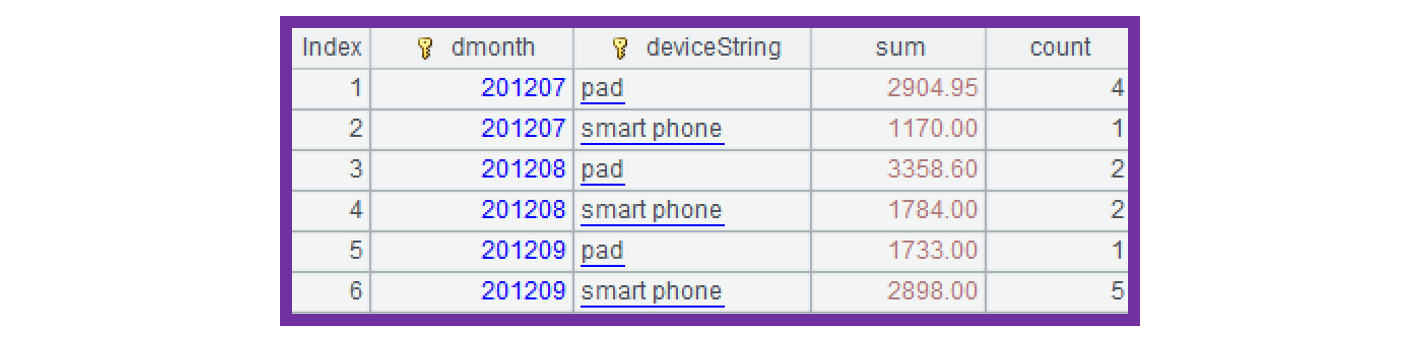
A3:过滤条件中的字符串 smart phone 会被自动转换为 2;pad 会被转换为 3,然后才会用来过滤物理表 detail。
A4 计算结果集中的 device 字段值 2、3 则分别会被转换为 "smart phone","pad",如下图:
虚表可以更新 update 或者追加 append,实际上改变的是对应的物理表。
包括枚举维度的虚表,追加和修改数据时只需要有伪字段值就可以了,SPL 会自动转换为真字段。
例如上面的例子,向 p_detail 中追加数据时,待追加的 new.btx 中只要有 deviceString 就可以了,SPL 会自动转换生成 device 字段。代码大致是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("new.btx").cursor@b(id,ddate,deviceString,amt) |
4 |
=p_edtail.append(A3) |
A3:新数据中只有 deviceString,没有 device。
A4:向虚表对应的组表追加数据,这时不要求字段顺序必须和原组表一致。
假设要按照 modify.btx 中的主键和数据更新 p_detail,且按照 delete.btx 中的主键删除 p_detail,代码是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("modify.btx").import@b(id,deviceString) |
4 |
=file("delete.btx").import@b(id) |
5 |
=p_edtail.update(A3:A4) |
A5:SPL 组表仅支持少量的修改和删除,所以 update 的参数是序表,而不是游标。
位维度
实际业务中还有很多布尔字段,用来描述是或者否。如果我们都存储为独立字段,那么即使用二值字段(取值为 1 或 0)代替布尔字段,也要用很多个整型字段来存储。
在物理表中,我们可以用整型字段的二进制位存储布尔字段,这样,一个 16 位短整型字段就能存储 16 个布尔值,每个二进制位存储一个,可以减少存储空间占用。而且,用二进制与或运算,一次就可以完成最多 16 个布尔值计算,性能会有明显提升。
但是,这样做就要自行实现整型二进制位与布尔值的转换和计算,会增加复杂度。而且,整数二进制位没有布尔字段或者二值字段那么容易读懂。
这种情况可以使用虚表的位维度,用伪字段定义二进制位和布尔值之间的映射关系,让代码变得非常简单。
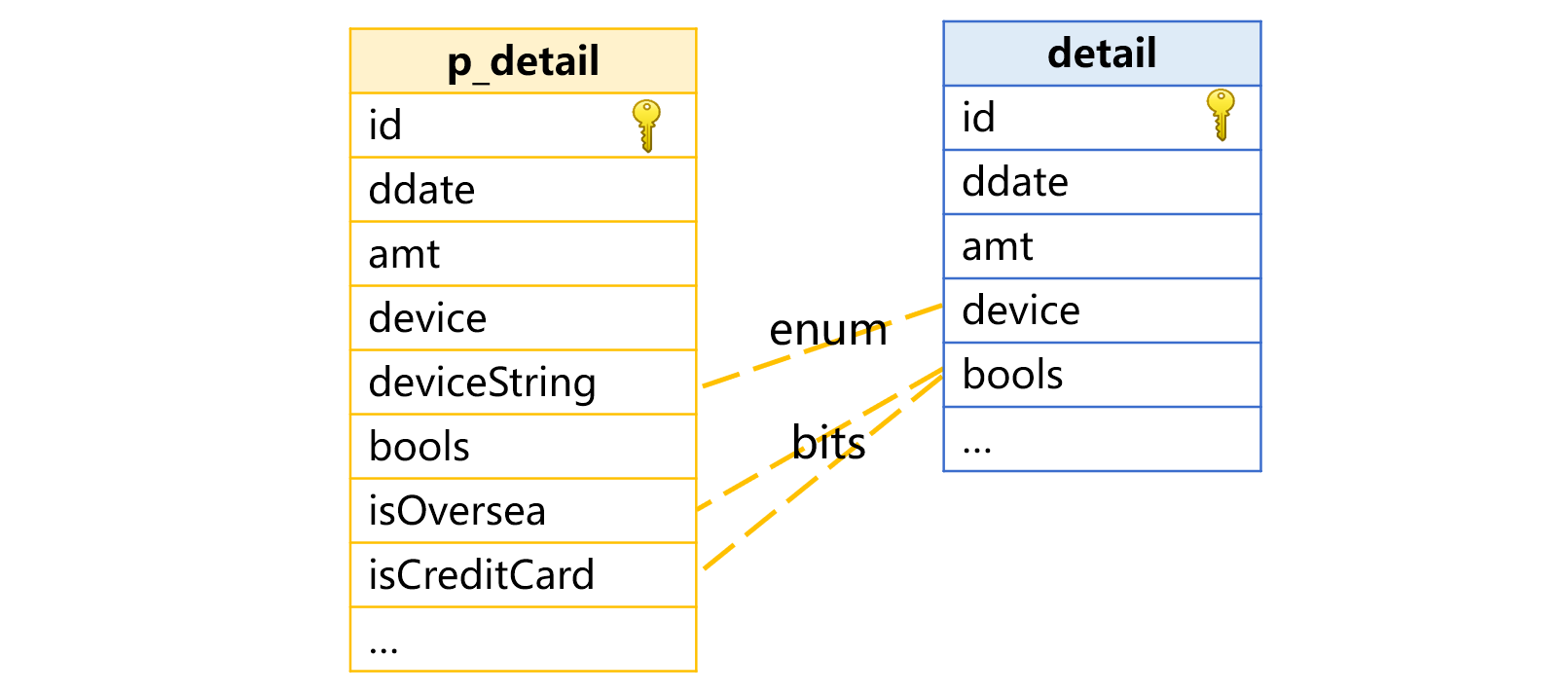
仍以交易明细表 detail 为例,bools 是整型字段,存储了两个布尔值 isOversea(是否海外购)、isCreditCard(是否信用卡支付),每个值占用 bools 字段的一个二进制位。
这时,我们要在虚表中定义伪字段,将 bools 字段和布尔维度之间的转换透明化,如下图:
相应的,虚表定义要修改成下图的样子:
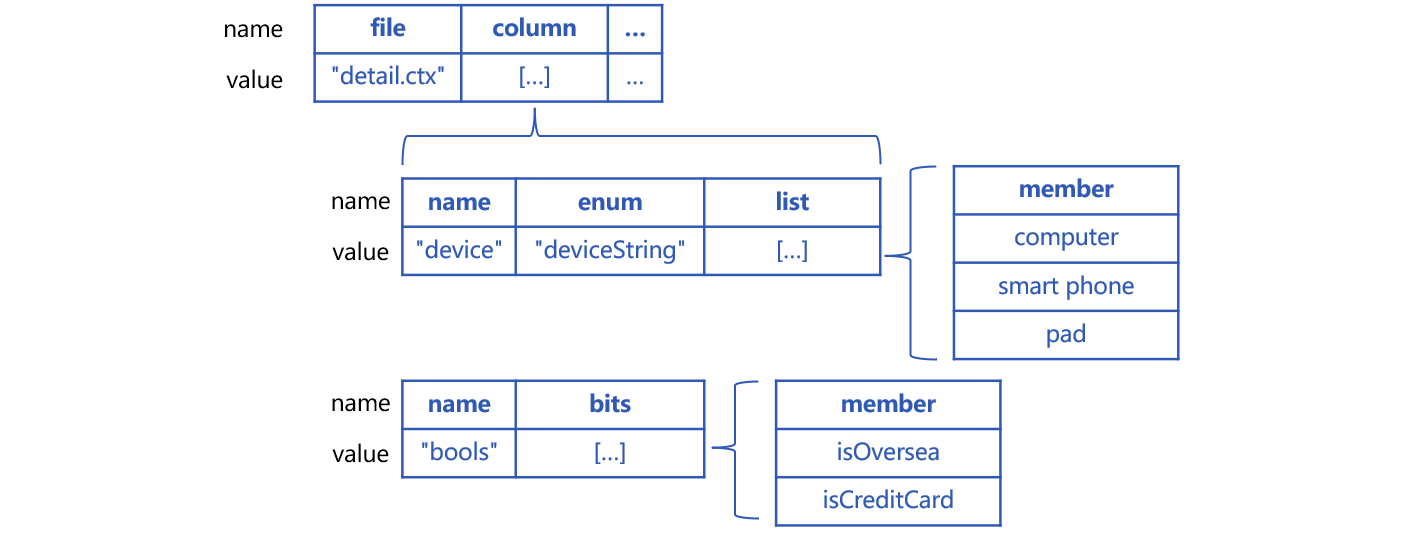
column 中增加了一个特殊字段的定义,name 是物理表真实字段的名称 bools,bits 属性中是伪字段名称集合,最多可以有 16 个布尔字段名称。本例 bits 中是两个字段名,分别对应 bools 字段中的第 1、2 个二进制位。
相应的,定义虚表 p_detail 的代码也要修改:
A |
||
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]} ] }] |
|
2 |
>p_detail=pseudo(A1) |
|
A1 增加了特殊字段 bools,属性 bits 中定义了两个伪字段名称。
此时,取出虚表 p_detail 的部分数据会变成下面这样:
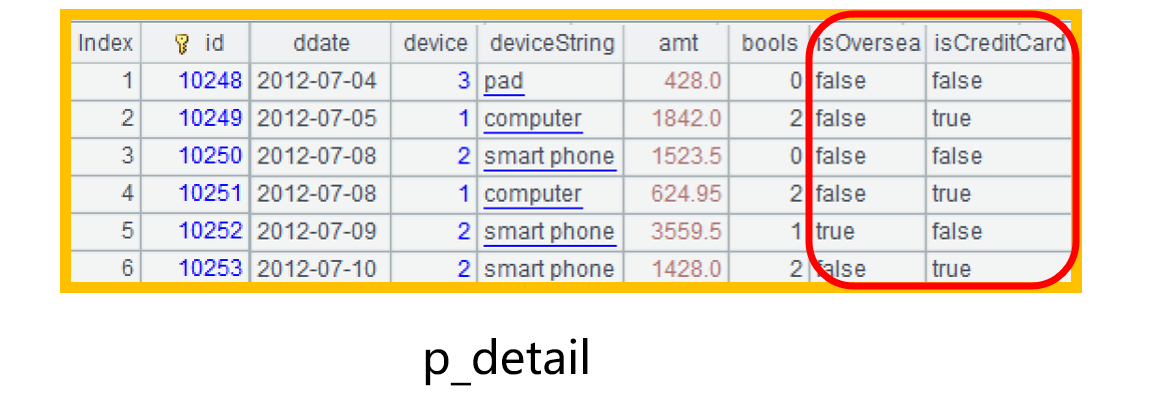
计算时直接使用 isOversea、isCreditCard 字段来做条件过滤和分组,并在结果集中显示布尔值:
… |
|
3 |
=p_detail.select(isOversea && (deviceString=="pad" || deviceString=="smart phone")) |
4 |
=A3.groups(month@y(ddate):dmonth,deviceString,isCreditCard;sum(amt),count(~)) |
A3 中过滤条件中的 isOversea 会被自动转换为 bools 字段的第 1 位,用来过滤物理表 detail。
A4 计算结果集中的 bools 字段第 2 位的值,会被转换为布尔值 isCreditCard:

在对虚表追加、修改数据时,只需要有位维度的伪字段值就可以了,SPL 会自动转换为真字段。
例如向 p_detail 中追加数据时,待追加的 new.btx 中只要有 isOversea,isCreditCard 就可以了,SPL 会自动转换生成真字段 bools。代码大致是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("new.btx").cursor@b(id,ddate,deviceString,amt,isOversea,isCreditCard) |
4 |
=p_edtail.append(A3) |
按照 modify.btx 中的主键和数据更新 p_detail,且按照 delete.btx 中的主键删除 p_detail,代码是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("modify.btx").import@b(id,isOversea,isCreditCard) |
4 |
=file("delete.btx").import@b(id) |
5 |
=p_edtail.update(A3:A4) |
冗余字段
假设物理表 detail 增加一个记录字段 custInfo,存储这个交易的客户信息,其中有个属性字段 comment,如下图:
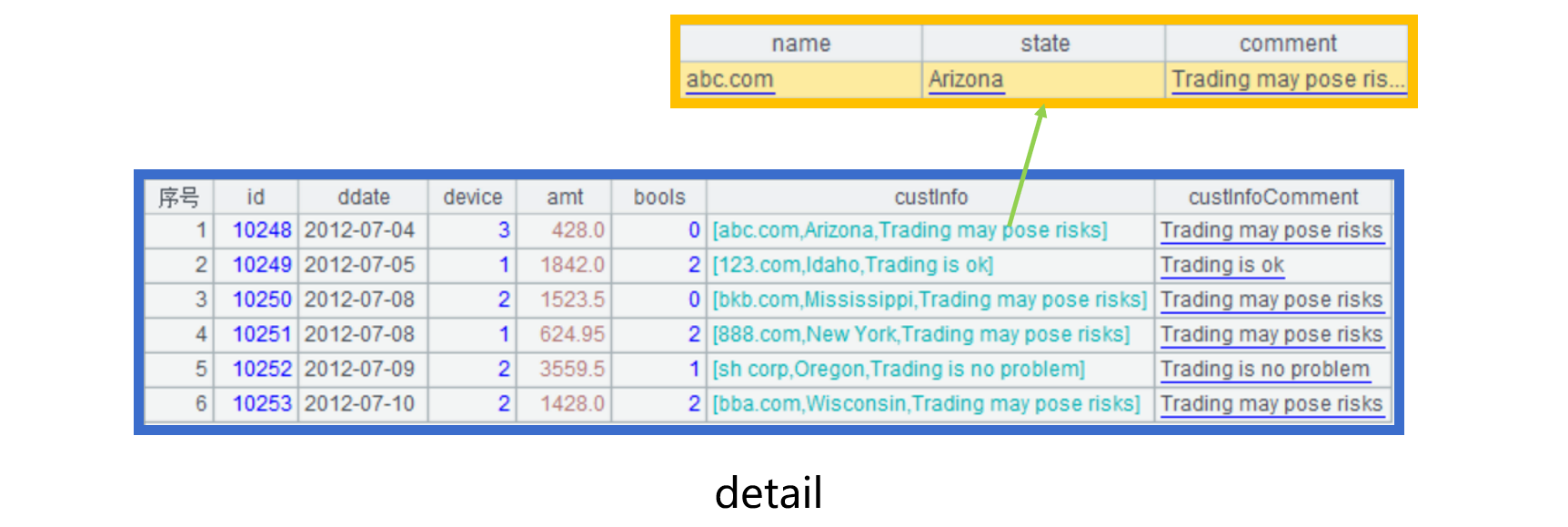
现在需要过滤出 custInfo.comment 字符串包含 "risk" 子串的数据。
如果过滤时直接使用 custInfo.comment,就会把整个 custInfo 都读出。即使 custInfo 的其他字段不参与计算,也要被全部读出、解析并生成记录。
为提高性能,可以在物理表中增加一个冗余字段 custInfoComment,用来存放 custInfo.comment 的值,能减少读入的数据,且可以省去生成记录的过程。
但是,这个冗余字段和记录字段的关系需要特殊说明,使用很不方便。而且,即使有说明,也无法保证应用程序员在合适的场景中都能使用冗余字段。
针对这种情况,虚表提供冗余字段机制,可以定义一个冗余字段对应的计算式exp,如果计算表达式中存在这个 exp,会自动用冗余字段代替。
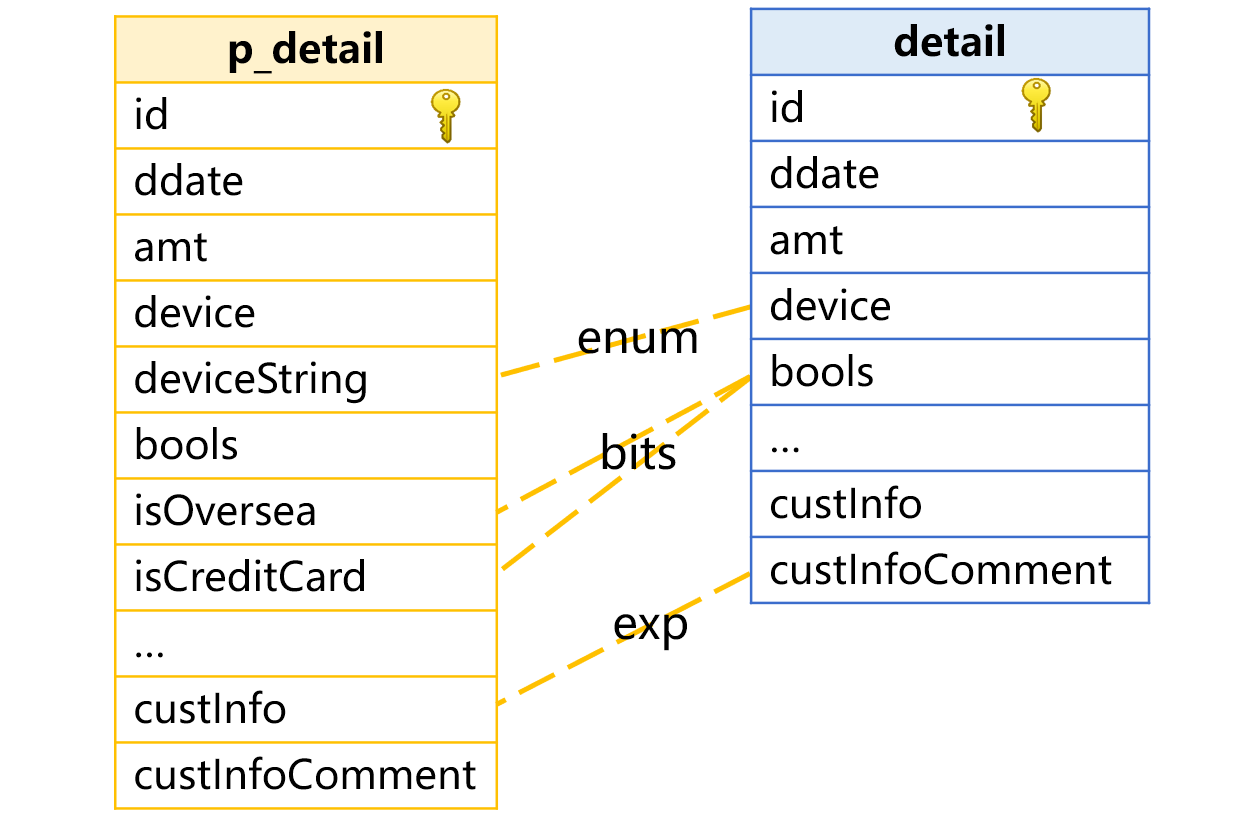
图中我们定义 exp 为 custInfo.comment,SPL 会自动用 custInfoComment 字段代替计算表达式中的 custInfo.comment。
虚表定义是下面这样:
定义和使用冗余字段的代码大致是这样的:
A |
B |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]} {name:"custInfoComment",exp:"custInfo.comment"} ] }] |
|
2 |
>p_detail=pseudo(A1) |
|
3 |
=p_detail.select(pos(custInfo.comment,"risk") && …) |
|
A1:在虚表中定义了一个计算式 exp:"custInfo.comment",和对应的真实字段 custInfoComment。
A3:过滤条件中出现了这个计算式,所以并不会取出 custInfo 的记录再取其中的字段,而是被替换成真实字段 custInfoComment,用这个冗余字段的值完成接下来的计算。
在对虚表追加、修改数据时,只需要有记录字段值就可以了,SPL 会自动转换为冗余字段。
例如向 p_detail 中追加数据时,待追加的 new.btx 中只要有 custInfo 就可以了,SPL 会自动转换生成 custInfoComment。代码大致是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]}, {name:"custInfoComment",exp:"custInfo.comment"} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("new.btx").cursor@b(id,ddate,deviceString,amt,isOversea,isCreditCard,custInfo) |
4 |
=p_edtail.append(A3) |
按照 modify.btx 中的主键和数据更新 p_detail,且按照 delete.btx 中的主键删除 p_detail,代码是这样的:
A |
|
1 |
=[{file:"detail.ctx", column:[ {name:"device",enum:"deviceString",list:["computer","smart phone","pad"]}, {name:"bools",bits:["isOversea","isCreditCard"]}, {name:"custInfoComment",exp:"custInfo.comment"} ] }] |
2 |
>p_detail=pseudo(A1) |
3 |
=file("modify.btx").import@b(id,custInfo) |
4 |
=file("delete.btx").import@b(id) |
5 |
=p_edtail.update(A3:A4) |
字段别名
有些应用中,真字段在不同情况下有不同的含义。这时候可以用虚表的字段别名来表示真字段的业务含义。
以电商系统事件表 events 为例,表中每一行是一个事件。每个事件都要存储事件类型 eventType 以及这类事件对应的属性信息 eventInfo。eventInfo 是一个记录字段,又包含多个字段,用来存储多个属性。
需要注意的是:不同类型的事件有不同的属性,相同类型的事件的属性相同。也就是说,eventType 字段值决定了 eventInfo 这条记录的字段个数、名称、数据类型。
举例说明,eventType 和 eventInfo 中的各属性关系大致是下表中这样:
eventType |
eventInfo |
|
property |
data type |
|
appInstall |
browser |
string |
device |
string |
|
reward |
float |
|
appStart |
page |
string |
title |
string |
|
dt |
datetime |
|
appEnd |
page |
string |
title |
string |
|
amount |
float |
|
dt |
datetime |
|
… |
… |
|
从表中可以看到,事件类型 appInstall 对应三个属性,appEnd 则对应完全不同的四个属性。由于事件类型很多,如果每个属性都存一个字段,就会让物理表有太多的字段。其实每种类型事件的属性个数并不会太多。
实际上,一个事件只能属于一个事件类型。假如一个事件属于 appInstall 类型,有 browser 属性,那么它就不可能有 appStart 类型的 page 属性。同时,这两个属性又都是字符串,我们可以用一个真字段 s1 来存储这两个属性。
以此类推,可以将同样数据类型的属性都合并起来,如下图:
eventType |
eventInfo |
trueField |
|
property |
dataType |
||
appInstall |
browser |
string |
s1 |
device |
string |
s2 |
|
reward |
float |
f1 |
|
appStart |
page |
string |
s1 |
title |
string |
s2 |
|
dt |
datetime |
dt1 |
|
appEnd |
page |
string |
s1 |
title |
string |
s2 |
|
amount |
float |
f1 |
|
dt |
datetime |
dt1 |
|
… |
… |
… |
… |
如图所示,我们用真字段 s1 存储三类事件的三个字符串属性 browser、page 和 page。其他真字段 s2、f1、dt1 和 s1 类似。总体来看只需要 s1、s2、f1、dt1 四个字段就可以存储图上出现的所有属性。
这样,物理表的结构就是下图这样:

虽然这样的物理表字段总数少很多,但是字段名看不出业务含义,不太方便使用。查询起来还要根据 eventType 解释不同字段的业务含义,也增加了复杂度。
这种情况可以利用虚表的字段别名和计算式 exp 配合使用。虚表为每个真字段配置多个有业务含义的别名,就会是下图这样:
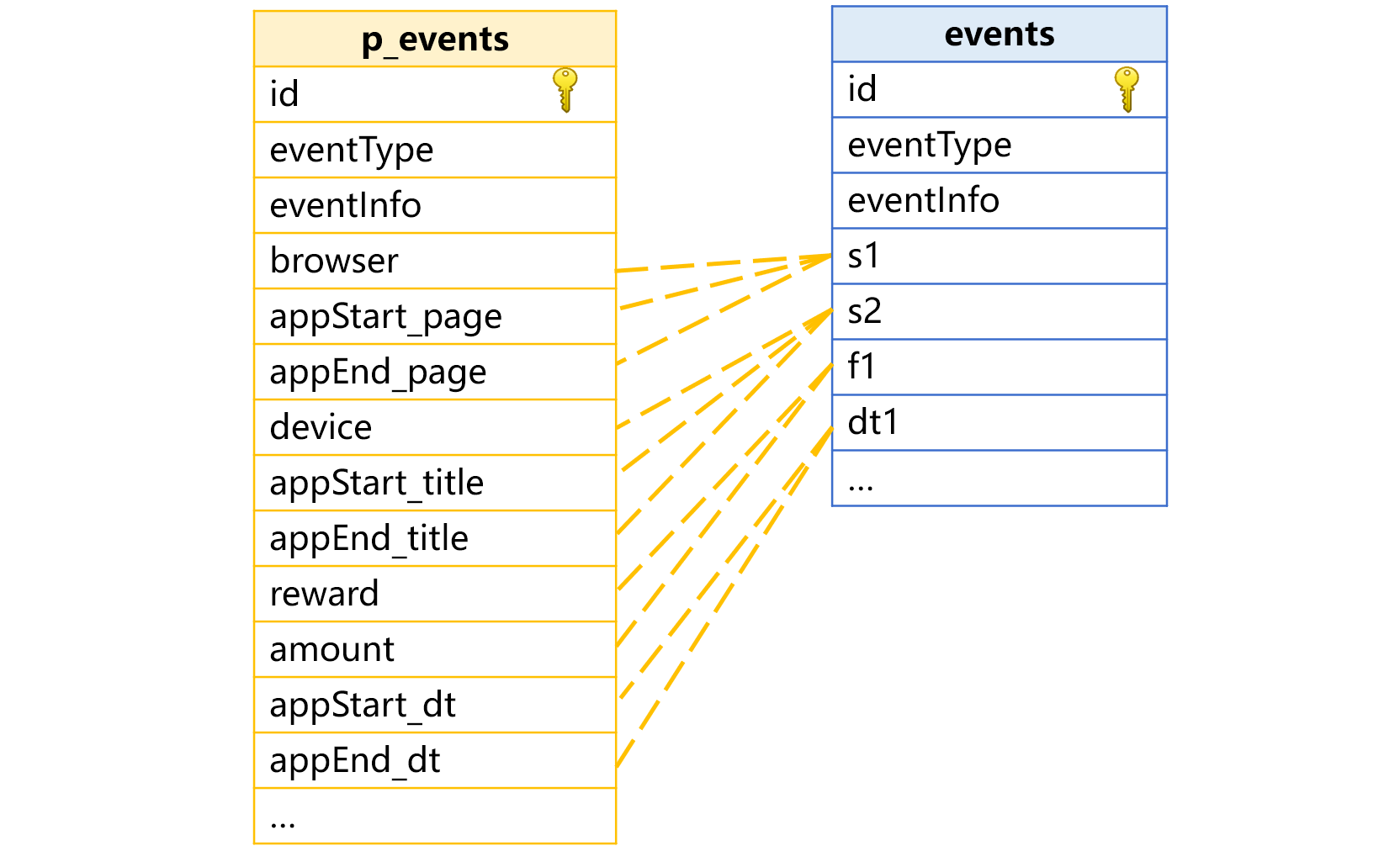
别名不能重复,所以有些别名加上了事件类型前缀,例如 appStart_page。
events 表中的 eventType 字段要用前面讲到的枚举维度,物理表存成连续自然数。
这时,虚表定义大致是这样的:
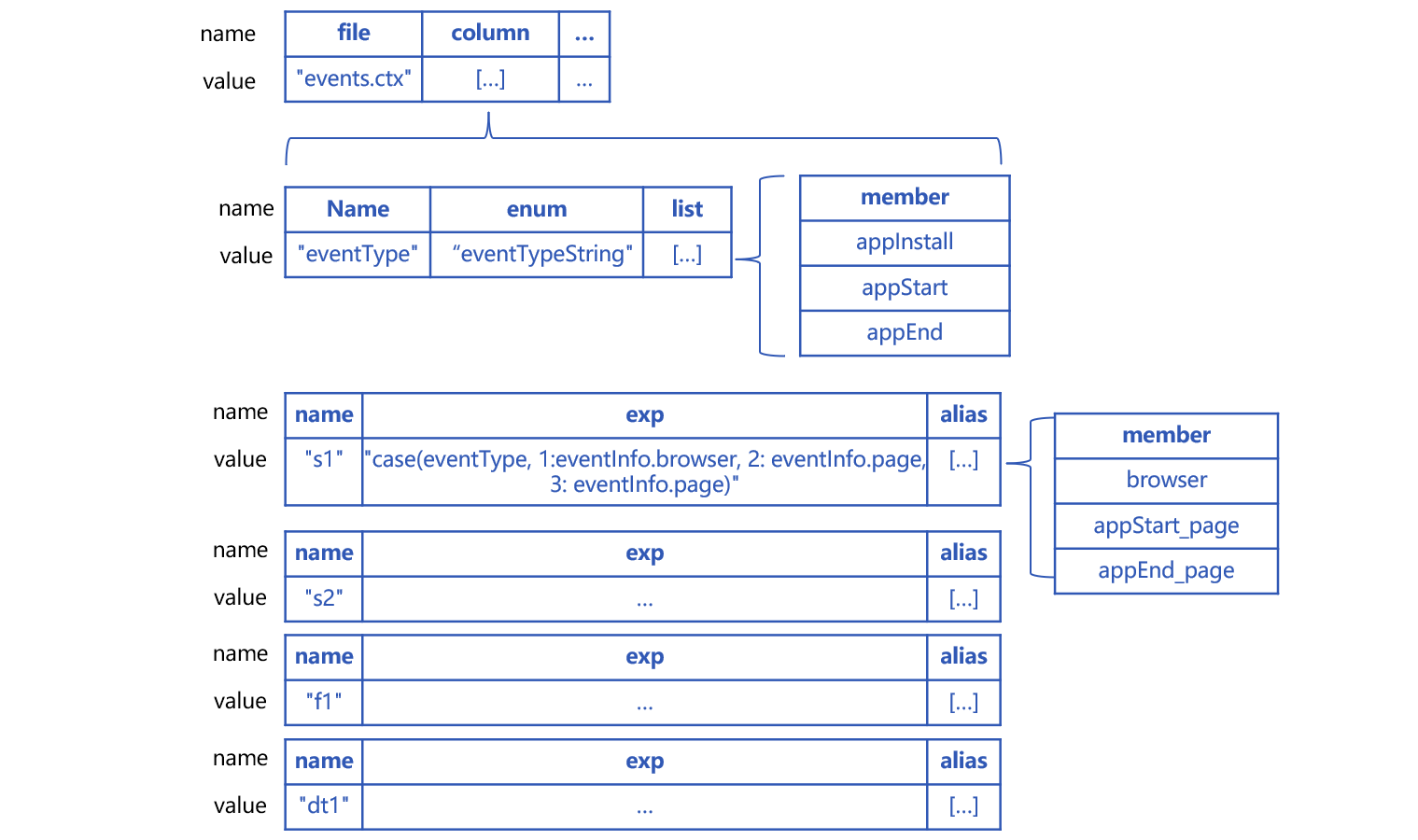
代码大致是这样的:
A |
B |
|
1 |
=[{file:"events.ctx", column:[ {name:"eventType",enum:"eventTypeString",list:["appInstall","appStart","appEnd"]}, {name:"s1",alias:["browser","appStart_page","appEnd_page"],exp:"case(eventType, 1:eventInfo.browser, 2: eventInfo.page, 3: eventInfo.page)"}, {name:"s2",alias:["device","appStart_title","appEnd_title"],exp:"case(eventType, 1:eventInfo.device,2: eventInfo.title, 3:eventInfo.title)"}, {name:"f1",alias:["reward","amount"],exp:"case(eventType,1:eventInfo.reward,3: eventInfo.amount)"}, {name:"dt1",alias:["appStart_dt","appEnd_dt"],exp:"case(eventType,2:eventInfo.dt, 3: eventInfo.dt)"} ] }] |
|
2 |
>p_events=pseudo(A1) |
|
3 |
=p_events.select(eventTypeString=="appInstall" && browser=="firefox") |
|
4 |
=A3.import(id,eventTypeString,browser,reward) |
|
A1:在虚表中定义了真字段 s1 的三个别名 "browser","appStart_page","appEnd_page",以及对应的计算式 exp:"case(eventType, 1:eventInfo.browser, 2: eventInfo.page, 3: eventInfo.page)"。
eventType 取值如果不是 1、2 或者 3,真字段 s1 应该为 null。所以这里不能写成 case(eventType, 1:eventInfo.browser;eventInfo.page)。
s2、f1、dt1 的写法和 s1 类似。
A3:过滤条件中出现了字段别名,SPL 并不会取出 eventInfo 的记录再取其中的字段,而是自动替换成真实字段 s1,用冗余字段的值完成后续计算。
A4:取出过滤结果。
在对虚表追加、修改数据时,只需要有类型字段和记录字段值就可以了,SPL 会自动转换为 s1、f1 等字段。
例如向 p_events 中追加数据时,待追加的 new.btx 中只要有 eventTypeString,eventInfo 就可以了,SPL 会根据这两个字段,自动生成 s1、f1 等。代码大致是这样的:
A |
|
1 |
=[{file:"events.ctx", column:[ {name:"eventType",enum:"eventTypeString",list:["appInstall","appStart","appEnd"]}, {name:"s1",alias:["browser","appStart_page","appEnd_page"],exp:"case(eventType, 1:eventInfo.browser, 2: eventInfo.page, 3: eventInfo.page)"}, {name:"s2",alias:["device","appStart_title","appEnd_title"],exp:"case(eventType, 1:eventInfo.device,2: eventInfo.title, 3:eventInfo.title)"}, {name:"f1",alias:["reward","amount"],exp:"case(eventType,1:eventInfo.reward,3: eventInfo.amount)"}, {name:"dt1",alias:["appStart_dt","appEnd_dt"],exp:"case(eventType,2:eventInfo.dt, 3: eventInfo.dt)"} ] }] |
2 |
>p_events=pseudo(A1) |
3 |
=file("new.btx").cursor@b(id,eventTypeString,eventInfo) |
4 |
=p_events.append(A3) |
按照 modify.btx 中的主键和数据(id、eventTypeString、eventInfo)更新 p_events,且按照 delete.btx 中的主键删除 p_events,代码是这样的:
A |
|
1 |
=[{file:"events.ctx", column:[ {name:"eventType",enum:"eventTypeString",list:["appInstall","appStart","appEnd"]}, {name:"s1",alias:["browser","appStart_page","appEnd_page"],exp:"case(eventType, 1:eventInfo.browser, 2: eventInfo.page, 3: eventInfo.page)"}, {name:"s2",alias:["device","appStart_title","appEnd_title"],exp:"case(eventType, 1:eventInfo.device,2: eventInfo.title, 3:eventInfo.title)"}, {name:"f1",alias:["reward","amount"],exp:"case(eventType,1:eventInfo.reward,3: eventInfo.amount)"}, {name:"dt1",alias:["appStart_dt","appEnd_dt"],exp:"case(eventType,2:eventInfo.dt, 3: eventInfo.dt)"} ] }] |
2 |
>p_events=pseudo(A1) |
3 |
=file("modify.btx").import@b(id,eventTypeString,eventInfo) |
4 |
=file("delete.btx").import@b(id) |
5 |
=p_edtail.update(A3:A4) |
回顾与总结
SPL 虚表相当于元数据,可以将物理表中比较复杂的存储机制透明化。这样,我们就可以像一个最简单的表一样使用虚表,降低了使用复杂度。同时,虚表又可以将逻辑结构上的简单计算,自动映射成高性能存储机制上的高效计算,可以保证计算性能。
在虚表中定义好枚举维度、位维度、冗余字段和字段别名后,使用者就不必再考虑这些存储和计算机制,将虚表当成简单的普通表即可。
除此之外,虚表还可以用于用户分析计算,实现两个维度字段同时有序,详情参见SPL 虚表的双维度有序机制。


英文版