


SPL 虚表的双维有序结构
依据用户、帐户明细数据做统计分析的场景比较常见。比如:用户行为分析、银行帐户统计、漏斗转化率、保险单分析等等,我们统称为帐户分析。这类场景的特征是:总数据量巨大但单个帐户数据量相对很小;数据涉及总时间跨度较长而每次参与计算的时间跨度不算很长;计算时帐户之间无关,帐户内计算可能很复杂。
因为一般都要对时间维度字段做过滤,如果预先将数据按时间排序存储,就可以快速排除大量不符合时间条件的数据,显著提高过滤性能。然后的计算将按帐户为单位实施,如果数据按帐户有序,也能很方便实现这一目标,代码编写简单,运算性能也会更好。
但是,一份数据不可能同时对两个维度都有序,即使用两个字段排序也要分先后。如果先帐户再时间排序,时间整体上就无序了,无法快速排除大部分不需要的数据。如果先时间再帐户排序,可以快速按时间过滤,但过滤后的结果又对帐户无序了。当内存足够大时,先时间再帐户排序比较有优势。按照时间过滤的结果,可以全部装入内存,利用内存的性能优势快速计算。但是,如果过滤之后的数据量仍比较大,还是需要外存计算的话,性能就比较差了。
SPL虚表提供了双维有序机制,可以做到数据整体上对时间维度有序(从而实现快速过滤),结果集还可以做到对帐户有序(从而方便地实施后续计算),看起来相当于实现了两个维度有序。
存储结构与取数过程
虚表是定义在复组表上的一个对象,复组表由多个结构相同的组表构成,这些组表称为分表。
设复组表 T 存储了 2021 年的帐户交易明细数据,包含帐户字段 userid、日期字段 dt、帐户所在城市 city、商品 product、交易金额字段 amt 等。整个复组表由 12 个分表组成,按照顺序分别存储 1 到 12 月的数据,大致如下图 1:

图 1 复组表 T.ctx
这样,这些分表整体上对 dt 有序。分表内部的数据则是按照 userid、dt 两个字段有序。以第二个分表 2.T.ctx 中存储的 2 月份数据为例,大致是下图 2 这样:
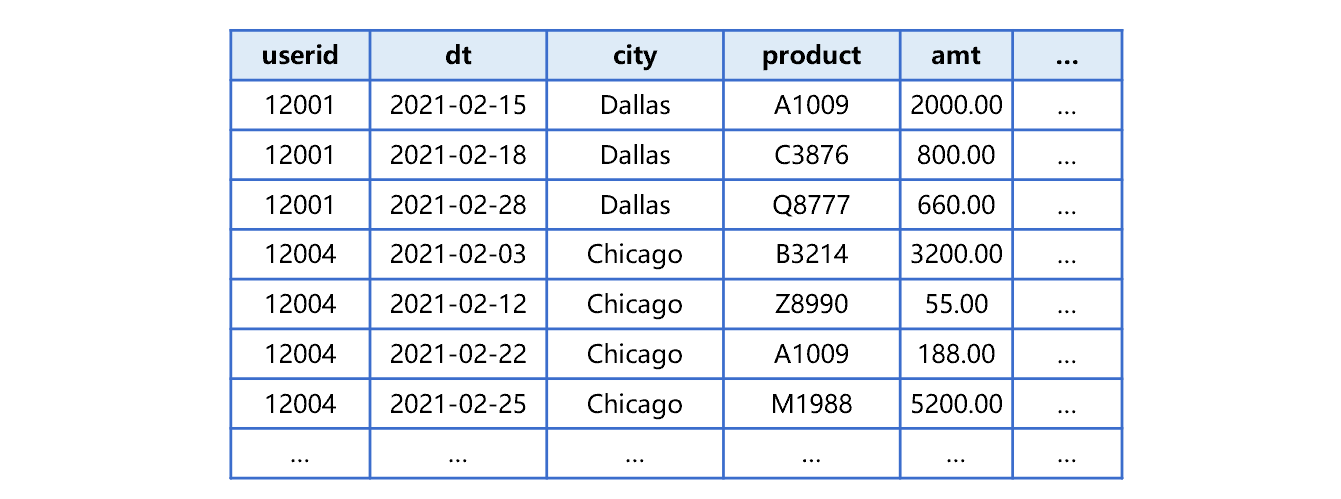
图 2 分表 2
有了复组表后,可以用一个由确定名称属性组成的结构(可以理解为一条记录,属性也就是字段)定义出虚表,大致是下图 3 这样:

图 3 虚表 T 的属性和值
file 是构成虚表的复组表的名称,本例中是 "T.ctx"; zone 是复组表的分表号,本例中是数值 1 到 12 组成的集合; date 是时间维度字段的名称,本例中是 "dt"。时间维度字段是将复组表分成多个分表的依据,又称为分列计算式。
虚表在创建时,会计算并记录各个分表中分列计算式(本例中即 dt)的最大值和最小值。大体是下图 4 所示:
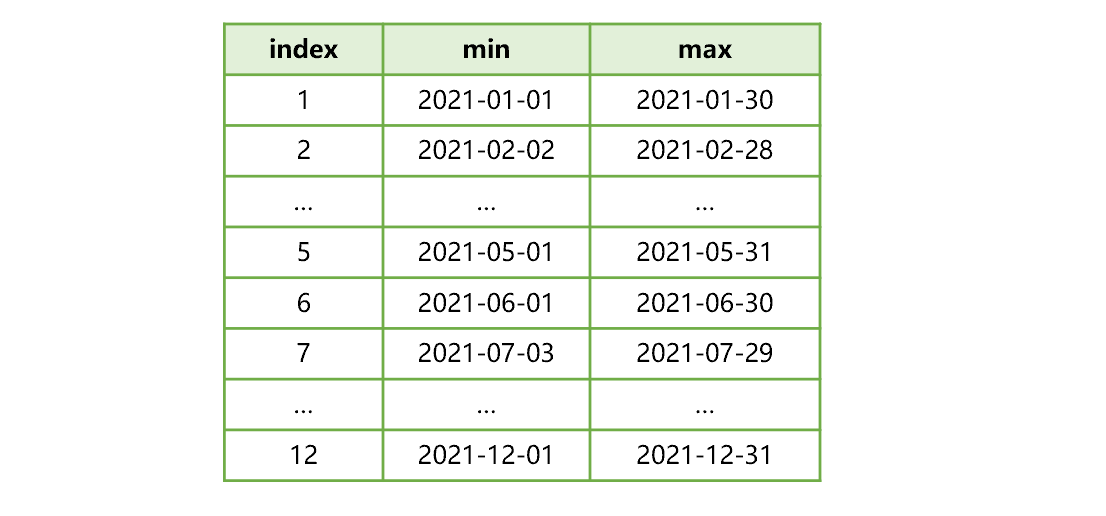
图 4 分列计算式的最大最小值集合
比如,图 4 中序号 2 的一行就表示:分表 2 的数据中,dt 最小值是 2021-02-02,最大值是 2021-02-28。需要注意的是,创建复组表 T.ctx 时,要用 userid、dt 作为复组表的维。这样作,一方面保证在分表中 userid 和 dt 有序。另一方面,组表中存储了维的最大最小值信息,可以在计算分列计算式的最大最小值集合时避免遍历全部数据,缩短生成虚表的时间。
下面我们来看使用虚表 T 的取数过程。假设计算需求是:先过滤出 dt 字段值在 2021 年 5 月 15 日到 5 月 25 日之间的数据,然后对 userid 字段分组计算。
首先,SPL 可以发现,过滤条件 dt 是虚表 T 的分列计算式。因此,会用 dt 在过滤条件中的起止时间,去查找分列计算式的最大最小值集合。如下图 5:
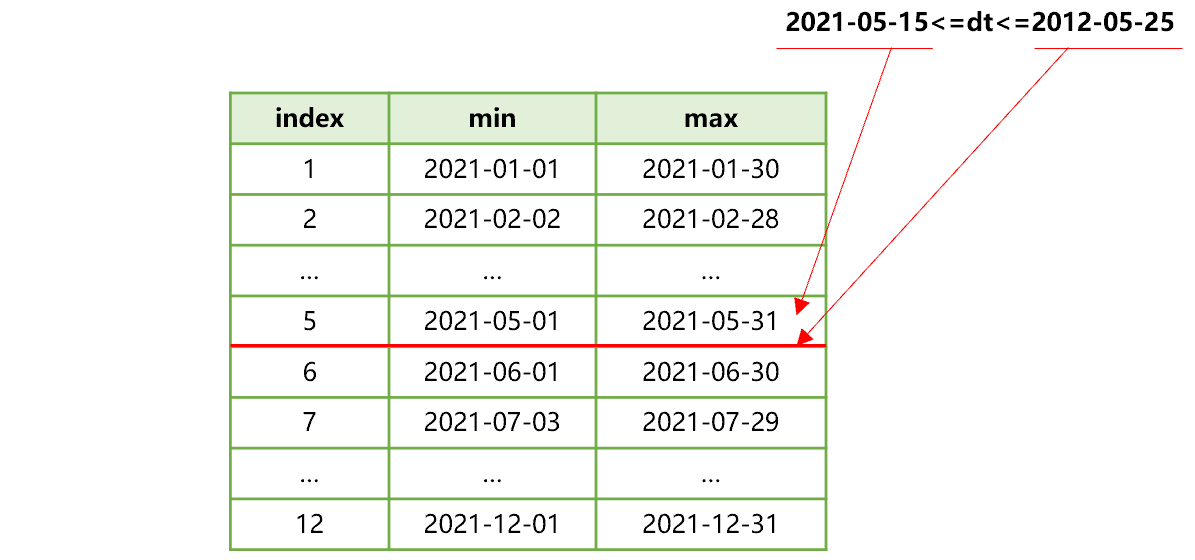
图 5 查找分列计算式的最大最小值集合
从图 5 可以看出,dt 过滤条件的起止时间都在第 5 个分表的分列计算式最大最小值范围内。由此可以确定,符合 dt 过滤条件的数据在复组表 T.ctx 的分表 5 中。这样就可以迅速把其它分表过滤掉,后续计算只读取一个分表 5 即可。
由于每个分表中的数据都是按照 userid 和 dt 有序的,所以 SPL 会按照顺序分批读取分表 5 的数据,做下一步有序分组计算。
因为分表 5 内部不再对 dt 有序,在读出数据时还要再次执行针对 dt 的过滤条件,而这将会遍历该分表,但比起遍历所有数据来讲还是快了很多。
如果扩大时间范围为 2021 年 5 月 15 日到 7 月 5 日,SPL 查找分列计算式的最大最小值集合的过程,会变成下图 6 这样:
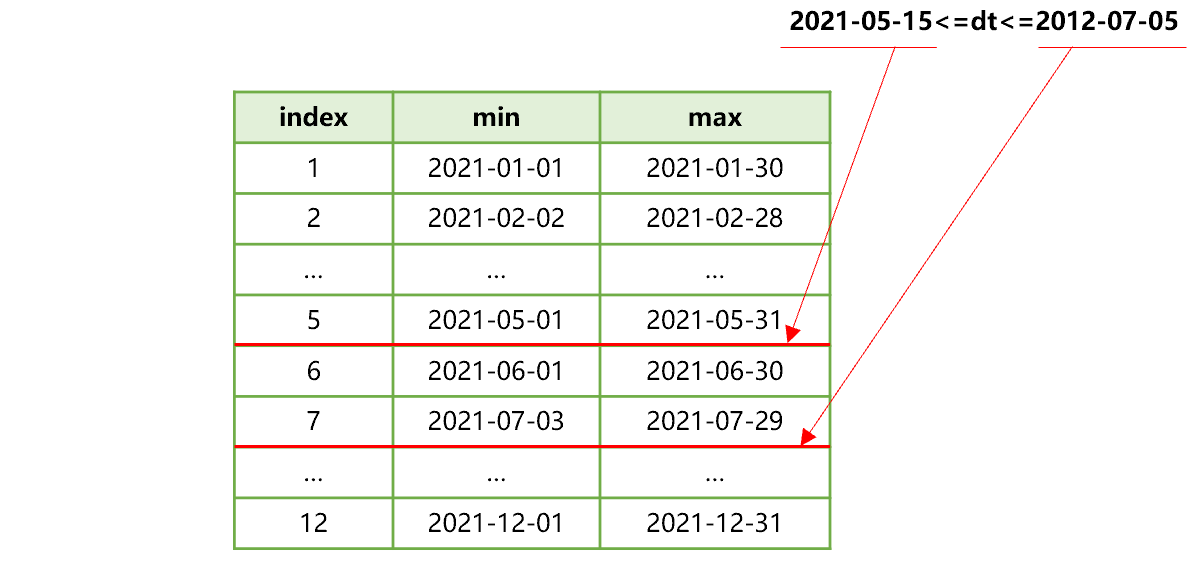
图 6 查找分列计算式的最大最小值集合
这时,符合 dt 过滤条件的数据在复表 T.ctx 的第 5、6、7 三个连续分表中。又由于分表 5、6、7 的数据都是按照 userid 有序的,所以在下一步计算中,SPL 会将这三个分表的数据按照 userid 有序归并,以游标的方式分批读入内存,做下一步有序分组计算。
这时候的遍历量是这 3 个涉及到的分表。
用 SPL 代码实现上述虚表生成和取数过程,大致是下面这样:
A |
|
1 |
=create(file,zone,date).record(["T.ctx",to(12),"dt"]) |
2 |
>T=pseudo(A1,0) |
3 |
=T.select(dt>=date("2021-05-15") && dt<= date("2021-07-05") ) |
4 |
=A3.groups@u(userid;...) |
A1 按照上面介绍的各个属性,准备虚表定义。
A2 生成虚表对象。虚表也支持多线程并行计算,pseudo 函数的第二个参数为 0,表示使用系统默认的线程数做多线程并行计算。
A3 对虚表 T 做快速时间过滤,A4 中的 groups 使用了 @u 选项,对过滤后的虚表做有序分组计算。
如果每个 userid 的计算都很复杂,也可以逐个 userid 取出数据,用多步骤代码实现:
A |
B |
|
… |
… |
|
4 |
=A3.cursor() |
|
5 |
for A4;userid |
… |
A4 对过滤后的虚表定义游标,A5 循环从游标中每次取出一个 userid 的数据做后续复杂计算。
应用示例
我们再基于上面的数据做一些稍复杂的运算 。假设对虚表 T 完成时间维度过滤之后,要按照产品分组,求组内 userid 去重个数和金额总和。SPL 代码大致是这样的:
A |
|
1 |
=T.select(dt>=date("2021-05-15") && dt<= date("2021-07-05") ) |
2 |
=A1.groups@u(product;icount(userid),sum(amt)) |
A1 对虚表 T 做快速时间过滤。A2 做分组有序去重计数及求和。
由于时间过滤之后的结果对帐户 userid 有序,所以 SPL 自动采用有序去重计数算法,性能要比 userid 无序的情况快很多,也不需要占有多少内存。
还有些计算更复杂,比如电商漏斗转化率计算。假设帐户事件表 T1 包括字段有帐号 userid、事件发生时间 etime、事件类型 etype。etype 可能是登录 "login",搜索 "search",查看 "pageview" 等等。典型的漏斗转化率就是计算一定时间内,连续完成登录、搜索、查看等多个步骤的去重帐户数。越是后续的事件帐户数越少,就像一个上大下小的漏斗一样。
这种情况下,就需要在虚表中循环取出帐户的数据,再按照时间顺序,用多步骤代码来计算。SPL 的写法大致如下:
A |
B |
C |
D |
|
1 |
=["login","search","pageview"] |
=A1.(0) |
||
2 |
=T1.select(dt>=date("2021-05-15") && dt<= date("2021-06-14")).cursor() |
|||
3 |
for A2;userid |
=first=A3.select(etype==A1(1)) |
if first.len()==0 |
next |
4 |
=t=null |
=A1.(null) |
||
5 |
for A1 |
if #B5==1 |
>C4(1)=t=t1=first.dt |
|
6 |
else |
>C4(#B5)=t=if(t,A3.select@1(etype==B5 && dt>t && dt<elapse(t1,7)).dt,null) |
||
7 |
=C4.(if(~==null,0,1)) |
>C1=C1++B7 |
||
A2 对已经快速过滤的虚表定义游标。A3 循环每次取出一个帐户的数据做复杂计算。
由于每次循环都能快速取出一个 userid 的全部数据,所以仅用很少的代码就能实现漏斗转化这样复杂的计算。关于这个漏斗转化计算详细的介绍参考这里:SQL 提速:漏斗转化分析,代码量还可以进一步减少。


英文版