


SPL 附表
在大数据表关联场景中,如果各个表按照主键或部分主键关联,我们可以采用 SPL 附表机制来做性能优化。
附表机制是将上述要关联的表绑在一起存储。以客户表 customer 和联系方式表 contact 为例,两表关系如下图 1:
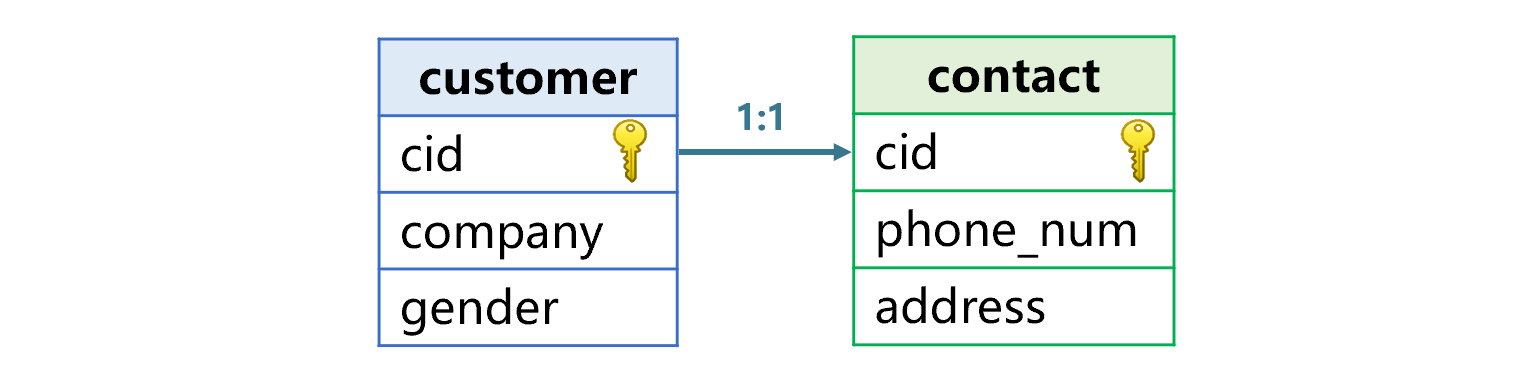
图 1 客户和联系方式表关系
图 1 中,客户表和联系表是通过各自的主键关联的,我们称这样关联的两个表互为同维表。
采用 SPL 附表机制存储客户表和联系表数据的方案,大致是下图 2 这样:
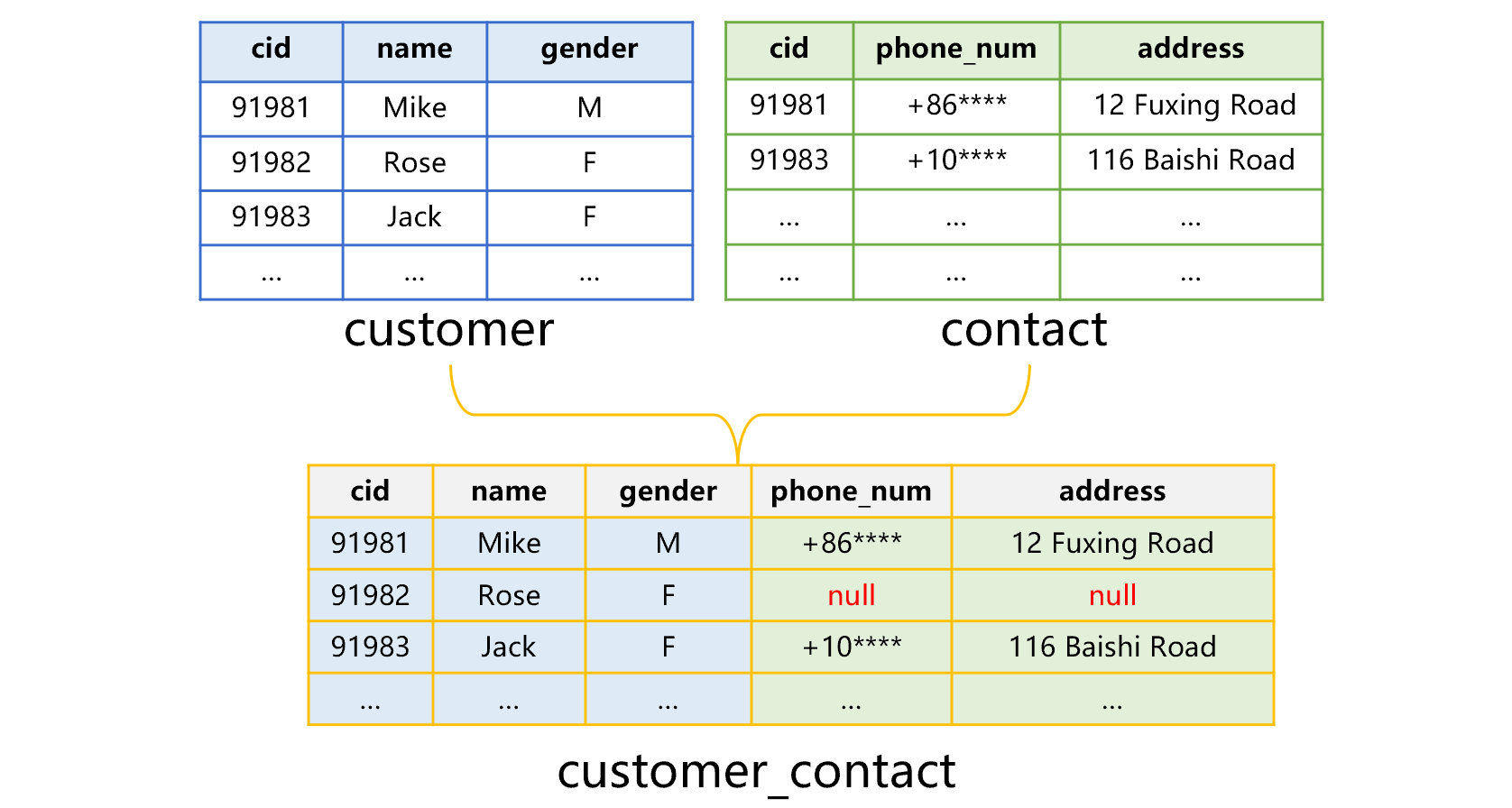
图 2 客户 - 联系表的附表存储方案
客户表用来存储客户的主要数据,所以主键 cid 字段值应该是最完整的。而有些客户可能并没有记录联系方式,因此联系方式表中的 cid 值则有可能不全。要绑定在一起存储时,我们以客户表为基准,称为基表,联系方式表称为附表。
图 1 中,先建立基表,附表的字段则作为基表记录的附加字段存储。附表字段也可以认为是基表的字段,只是这些字段在很多记录中是空值。新建的 customer_contact 表,是基表和附表的组合,称为组表。组表中的基表和附表称为实表。
对于三个或更多的同维表,可以存储成一个基表和多个附表。存储方案和图 2 类似,只是有更多的附加字段而已。
附表存储机制在性能方面有以下优势:
1) 客户表(基表)和联系表(附表)有共同的主键 cid。附表字段是基表记录的附加字段,基表中存储 cid 就可以了,附表不需要再存储 cid,存储量会更小。采用列存方式时,关联计算需要读取的数据量也变少了。
2) 附表字段可以作为基表记录的附加字段直接被引用,比如联系表中的 phone_num 和 address 字段。不需要再做两个表的关联比对,计算量会变小。特别地,如果基表被过滤了,附表会自然被过滤,不需要再做附表过滤计算了,反过来也成立。
3) 附表字段作为基表记录的字段,和基表记录绑在一起,分段时天然同步,不需要再做特殊的跟随分段。有利于并行计算提速。
同维表是通过各表的主键关联的。如果是一个表的主键和其他表的部分主键关联,情况会复杂一些。以订单表 orders、明细表 details、付款表 payments 为例,三个表的关系如下图 3:
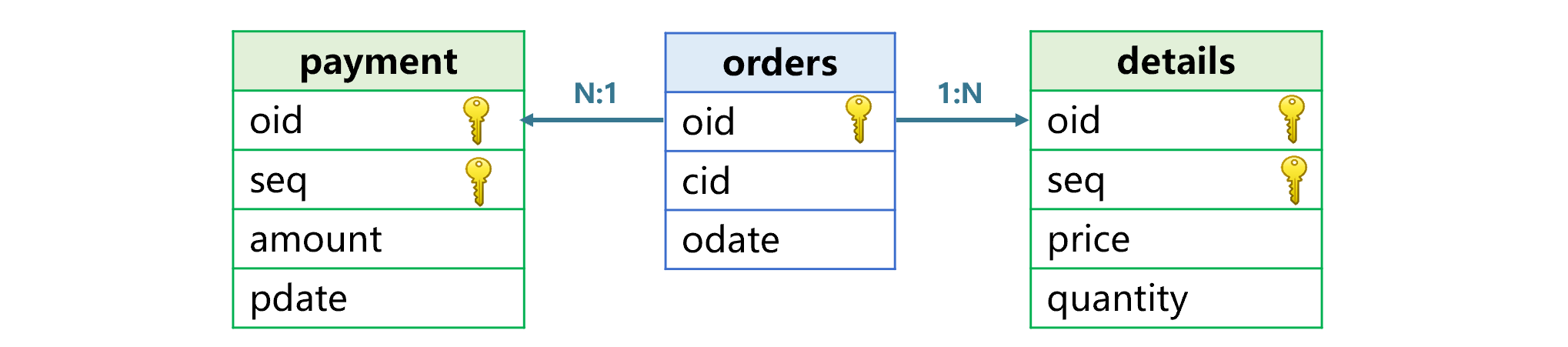 图 3 订单表、明细表、付款表的关系
图 3 订单表、明细表、付款表的关系
图 3 中,三个表要按照订单编号 oid 关联。oid 是订单表的主键,是另外两个表的部分主键。我们将这样关联的表称为主子表,订单是主表,明细和付款是子表。
将三个表数据转换为 SPL 附表机制存储,大概是下图 4 这样:
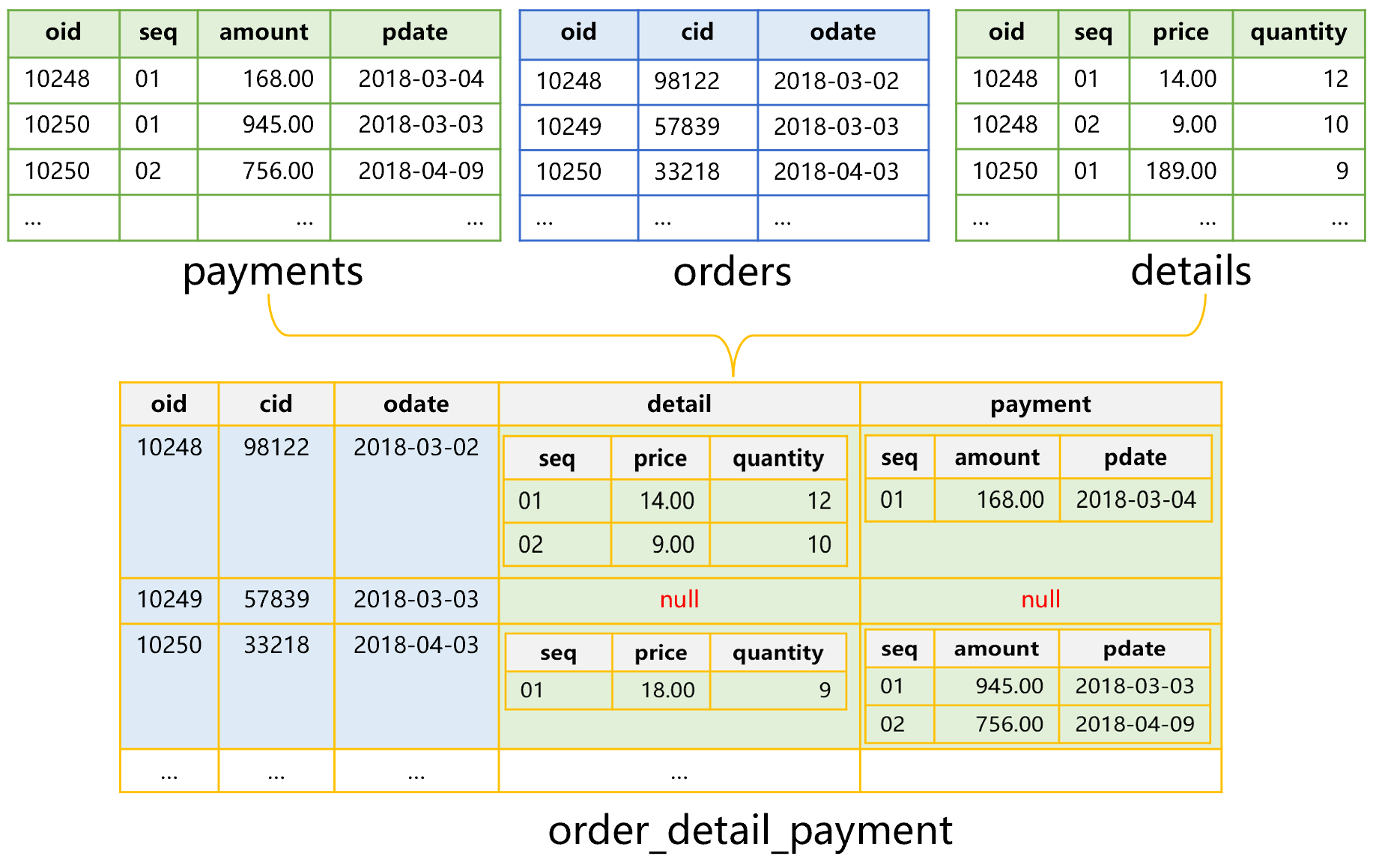
图 4 订单 - 明细 - 付款表的附表存储机制
这时,要以主表为基表,子表为附表。图 4 中,先建立基表,再用附表的字段作为基表记录的附加字段。由于订单的一条记录对应明细表或者付款表的多条记录,所以这些附加字段的取值是个集合。来自同一个附表的附加字段,其取值集合的长度是相同的,比如附表明细表的 price 字段和 quantity 字段都是集合,且长度相同。这些附加字段也可能为空。
主子表采用附表机制存储,也具备前面讲到的性能优势。只是附加字段的取值是个集合,所以基表引用附表字段的方式会有所不同。
不过,同维表和主子表的附表存储方式也有坏处。因为存储方案变得更复杂了,在引用附加字段时会有不少额外的判断。
通常在主键及关联较为复杂时,使用附表方案就会有更大的性能优势。比如客户表和联系表的主键字段有多个,或订单 - 明细关联的 1:N 比例中 N 更大,这就意味着直接用普通表做常规关联时,会有更多的对比计算。
如果是简单的单一主键一对一关联,附表机制性能优势会不太明显,甚至可能会有劣势。因此,要根据具体的场景因地制宜地分析,是否采用附表机制。
理论上,主子表建立的附表还可以再有附表,但不太常见了。
SPL 在组表上实现了附表功能,需要在创建组表时指定附加字段。以订单 - 明细 - 付款表为例,代码是下面这样:
A |
B |
|
1 |
=file("orders.ctx").open().cursor() |
|
2 |
=file("details.ctx").open().cursor() |
=file("payments.ctx").open().cursor() |
3 |
=file("order_detail.ctx").create(#oid,cid,odate) |
|
4 |
=A3.attach(detail,#seq,price,quantity) |
=A3.attach(payment,#seq,amount,pdate) |
5 |
=A3.append@i(A1) |
|
6 |
=A4.append@i(A2) |
=B4.append@i(B2) |
A3 创建一个常规的组表,A4 在 A3 附加一个附表,要指定附表的名字 detail 及字段。
因为是主子表,所以子表 detail 还要设计自己的主键 seq。而 oid 是主子表共同的主键,这里不需要再写了。
同样 B4 继续在 A3 上附加了附表 payment。
A5、A6、B6 中和普通数据表一样追加数据,SPL 会使用附表的主键把记录附加到正确的主表记录上。
需要注意,基表和附表除了主键外,不能有同名的字段,否则会发生混淆。
创建好有附表的组表后,就可以在运算中引用附表的字段了。SPL 代码是这样的:
A |
|
1 |
=file("order_detail.ctx").open() |
2 |
=A1.cursor(odate,detail.sum(quantity):quantity,payment.sum(amount):amount) |
3 |
=A2.groups(odate;sum(quantity),sum(amount)) |
也可以再还原出子表的记录:
A |
|
1 |
=file("order_detail.ctx").open() |
2 |
=A1.cursor(odate,detail{price,quantity}:amount) |
3 |
=A2.run(amount=amount.sum(price*quantity)) |
4 |
=A3.groups(odate;sum(amount)) |
因为子表记录是多个,还原之后将作为主表游标的一个字段,其取值是一个序表。生成序表等动作比较复杂,这样做会损失性能,有可能抵消减少关联带来的优势。
还可以从附表来引用基表字段:
A |
|
1 |
=file("order_detail.ctx").open().attch(detail) |
2 |
=A1.cursor(odate,price,quantity) |
3 |
=A2.groups(odate;sum(price*quantity)) |
引用基表字段时直接写就可以了,性能会比上面那种生成序列字段的方法更好。
这些运算都可以支持多路游标。


英文版