


SPL 程序游标
大数据计算场景下,很多比较复杂的算法都会产生落地的中间结果,出现对外存的读写,从而影响性能。
例如,帐户交易表 trades 包含帐号 id,交易日期 dt 和交易金额 amount 字段。现在希望找出每月内连续 n 天都有交易的那些交易记录,然后按发生日期的星期几统计交易金额。
我们将前半段计算称为 compute1,后半段称为 compute2。先看 compute1,要找出连续 n 天都发生的交易,可以预先将数据按照帐号和交易日期排序存储。因为一个帐号的交易数据一般不会太多,内存足够放下。所以,计算时就可以顺序读取排好序的数据,每次取出一个帐号的记录(也就是分组子集),在内存中完成 compute1 计算。
但是,compute1 比较复杂,分组子集取出来后还要再写几句代码才能过滤出来需要的记录。然后这些记录就在内存中,怎么让它们继续进行下一步的分组汇总运算呢?
很容易想到的办法就是中间结果落地。也就是把这些算出来的数据逐步写入一个外存缓存表 temp,再对这个缓存表做分组汇总。计算写入缓存表的过程,大致是下图 1 这样:
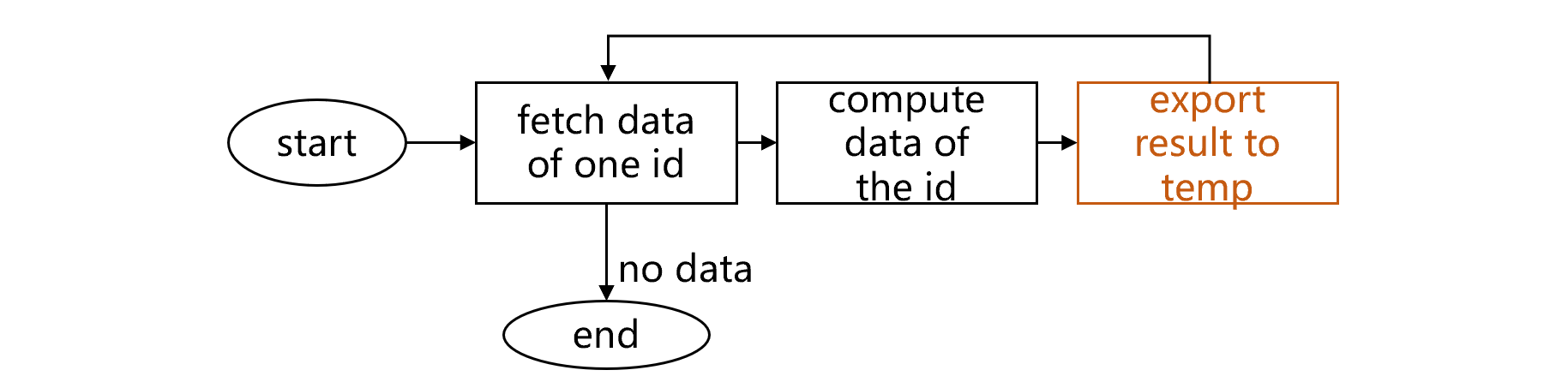
图 1 结果写入缓存表
图 1 开始计算后,从帐户交易表读取帐号相同的一组数据,计算出满足条件的记录,写入缓存表 temp。然后继续下一次循环,直到所有数据读完为止,符合条件的记录都写入 temp 了。这就完成了 compute1。
接下来,可以对 temp 建立一个普通游标,做分组汇总完成 compute2,基本上是图 2 这样:
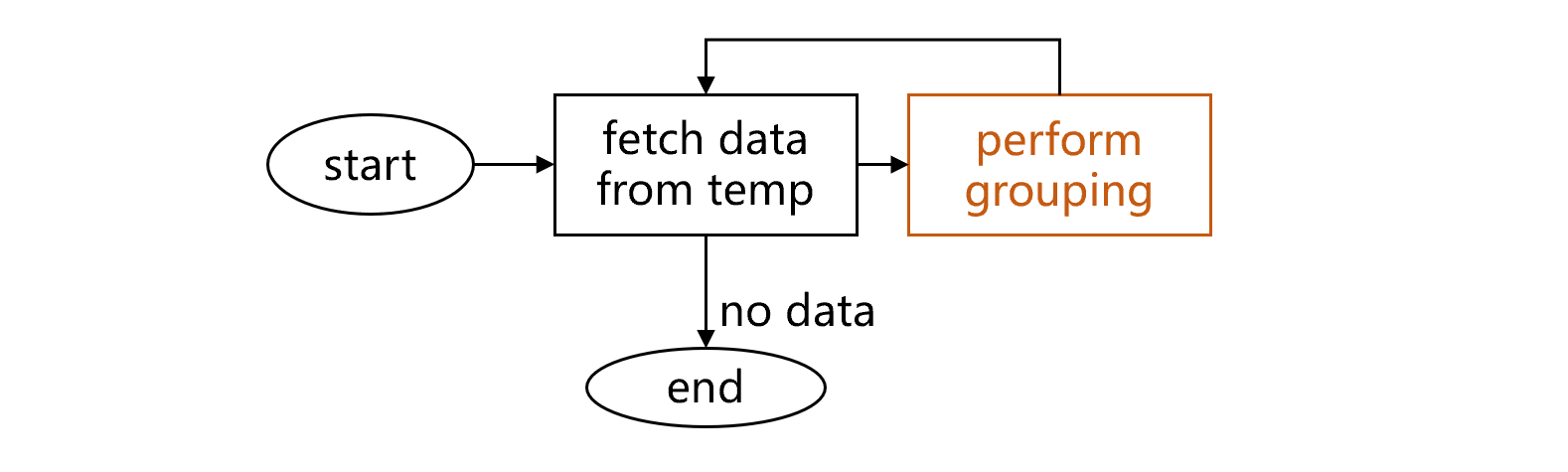
图 2 用 temp 游标做分组汇总
图 1、2 对应的 SPL 代码是下面这样:
A |
B |
|
1 |
=file("trades.ctx").open().cursor(id,dt,amount) |
|
2 |
for A1;id |
=A2.align@a(31,day(dt)).group@o(~==[]) |
3 |
=B2.select(~.len()>=n ).conj().conj() |
|
4 |
=file("temp.btx").export@ab(B3,dt,amount) |
|
5 |
=file("temp.btx").cursor@b().groups(day@w(dt);sum(amount)) |
|
A1 到 B4 对应图 1,完成 compute1。
A2 循环取出分组子集。
B2 将分组子集按交易日期对齐到 31 天,再用有序分组拆成连续空和不空的一些子集。
B3 找出子集长度超过 n 的,即有连续 n 天都有交易或都没有交易,再合并起来就得到了有连续 n 天内发生的交易(连续 n 天没有交易的是空集,不会改变合并的结果)。注意这里要 conj 两次,因为 align@a 的结果是序列的序列。
B4 把计算完的结果写入 temp,只要写入两个字段即可。
A5 对应图 2,用 temp 建立游标做分组汇总,完成 compute2。
这个计算过程显然会很慢,因为要把中间数据写到外存缓存表中,有一次写和读的动作。其实这些数据只要直接拿去做 compute2 的分组汇总就可以了,没有必要写入外存。如果真能做到这样直接计算的话,大致过程应该是下图 3 这样:
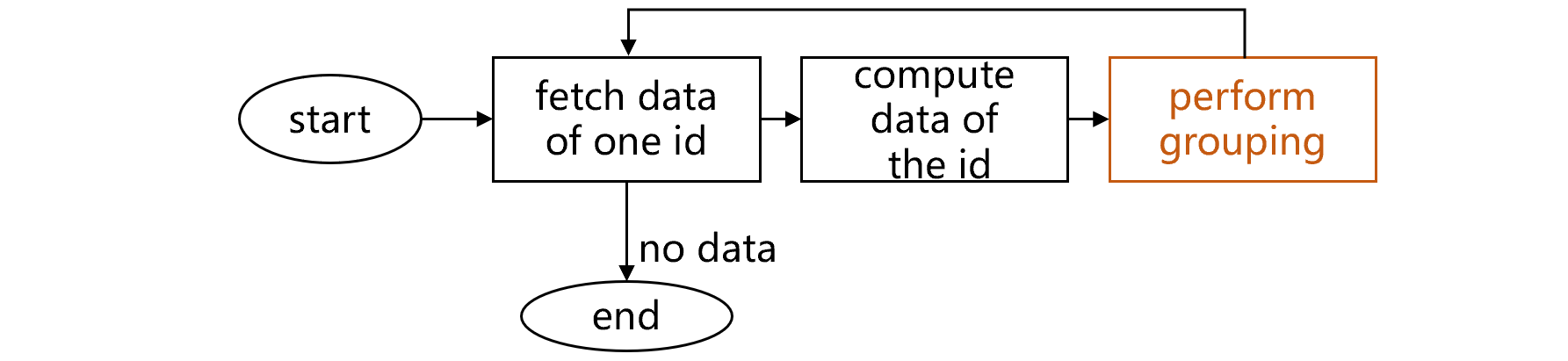
图 3 直接计算分组
在设想中,图 3 不再写入外存,而是直接计算分组。但实际情况是:分组函数只能基于序表或游标,要实现这个新步骤,必须对着每一组数据硬编码实现分组汇总,就太麻烦了。如果 compute2 不是分组,而是其他更复杂的计算,这个新步骤的代码就更难写了。
SPL 提供了程序游标可以完成这个机制,即把循环过程中产生的数据模拟成一个游标。
实现程序游标机制,先要定义一个子程序 func1,大致如下图 4:
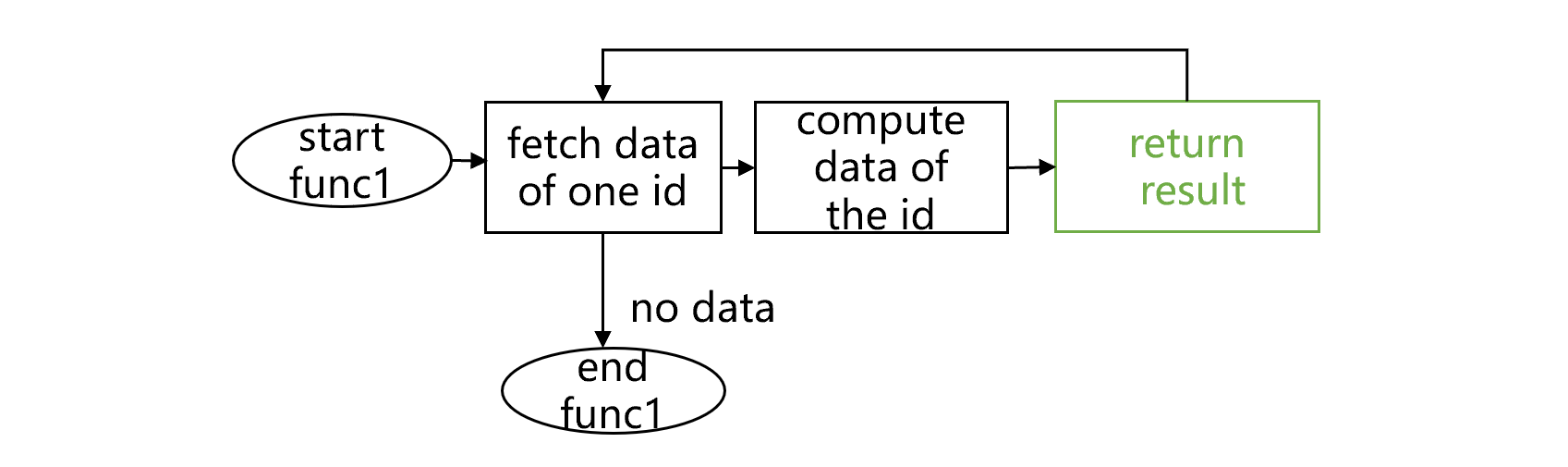
图 4 子程序 func1
图 4 中,func1 是在循环内部返回结果的。按照一般的子程序调用过程,func1 只会返回第一个分组子集的计算结果,然后就会被调用者关闭了。
SPL 的程序游标机制提供了不同的方法来调用 func1,计算过程大致是下图 5 这样:
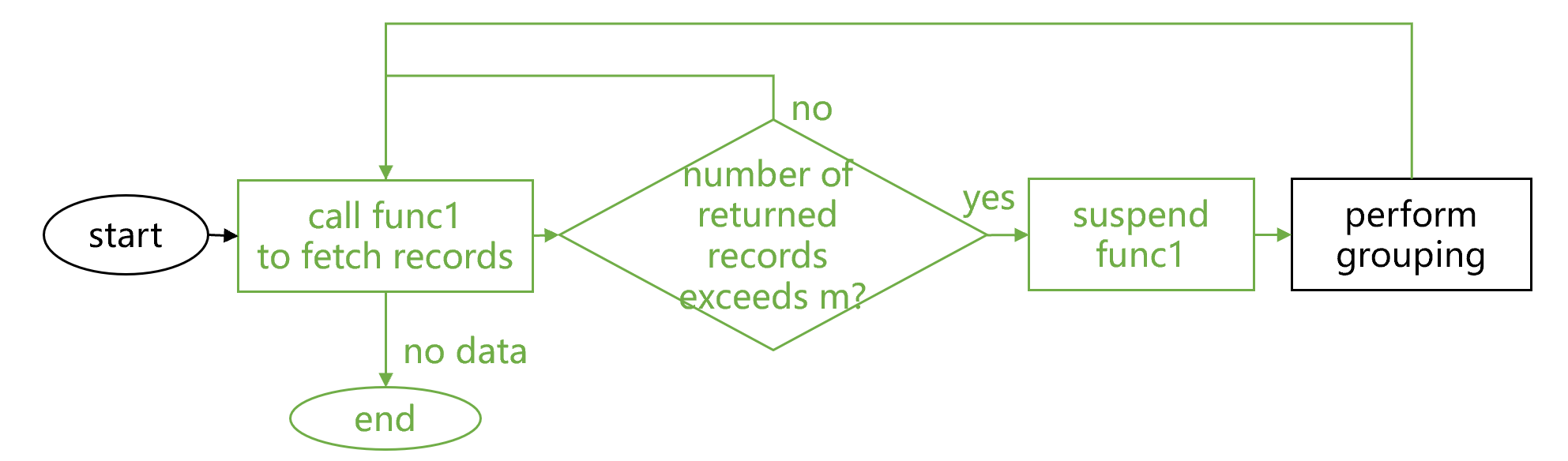
图 5 程序游标
图 5 中,程序游标机制作为一个外部程序,调用并收集 func1 的返回结果,拼成一个游标。当 compute2 的分组汇总计算向这个游标 fetch 请求 m 条数据时,程序游标机制会开始执行 func1,收集返回值。与普通子程序调用不同的是,执行完图 4 中的绿框返回结果后,func1 并不会被无条件结束。如果返回记录没有达到 m 条,那么图 4 中的循环将继续执行。如果达到 m 条了,则会暂停 func1 的循环并返回本次 fetch。
这时,func1 也不会被关闭,下一次需要再 fetch 数据时则继续执行 func1。直到子程序彻底循环完毕后结束执行,程序游标机制会返回游标结束。
这种过程可以把循环中不断计算出来的数据拼成一个游标,中间数据不必落地到外存,让这种复杂过程的运算也获得更高性能。这种游标称为程序游标。
SPL 将程序游标机制封装在 cursor@c 函数中。图 4、5 对应的 SPL 代码如下:
A |
B |
C |
|
1 |
func |
=file("trades.ctx").open().cursor(id,dt,amount) |
|
2 |
for A1;id |
=A2.align@a(31,day(dt)).group@o(~==[]) |
|
3 |
return B2.select(~.len()>=n ).conj().conj() |
||
4 |
=cursor@c(A1).groups(day@w(dt);sum(amount)) |
||
A1 到 C3 对应图 4,定义了 func A1,也就是 func1。
A4 对应图 5,用 cursor@c 函数调用 func A1,完成程序游标计算。
我们可以利用程序游标实现哈希大排序算法。比如将订单表按订单额排序:
A |
B |
C |
|
1 |
func |
=file("orders.btx").cursor@b() |
=100.(file(~)) |
2 |
=B1.groupn(int(amount/100)+1;C1) |
>B1.skip() |
|
3 |
for C1 |
return B3.import@b().sort(amount) |
|
4 |
return cursor@c(A1) |
||
在 B2 中把订单按金额分成 100 份(这里我们假定订单金额范围在 0-10000 区间内基本平均分布,可以根据实际情况调整拆分方式,要保证这个拆分表达式和待排序字段值是单调不降或不增的,且每个拆分取值对应记录数较少,可以装入内存)。然后,只要按次序依次返回每一份的排序结果就可以了。cursor@c 函数会把这些返回值收集起来组织成游标。


英文版