


SPL 的全文索引
结构化数据查询中,常常会遇到全文检索的需求。比如,在国家表中,查找 Ch 开头的国家;或者在“帖子”表中,查找“内容”字段包含 water 的记录。
面向搜索的全文检索虽然能解决这个问题,但不太适合用于结构化数据计算任务。其面对的是大规模网页,数据量非常大,所以索引也非常庞大,而且还可能涉及到很专业的自然语言理解和分词技术。
结构化数据的规模通常远小于搜索面临的网页,查找范围一般也会限定在某个字段内,这样涉及数据量会更小一点。而且,字段内容通常也就是几个字符到一句话,很少会像网页那样是一整篇文章。
SPL 针对结构化数据的这种特征,采用更简单的技术,提供了轻量级的全文索引方案。
多索引归并
多索引归并技术能够在一定程度上让多个索引配合工作。SPL 全文检索方案中也用到了多索引归并。
以用户表为例,我们要利用单个字段的索引查找生日是 2020-12-30,城市在 Chicago 的用户。先看按照城市建立排序索引的过程,大致如下图 1:
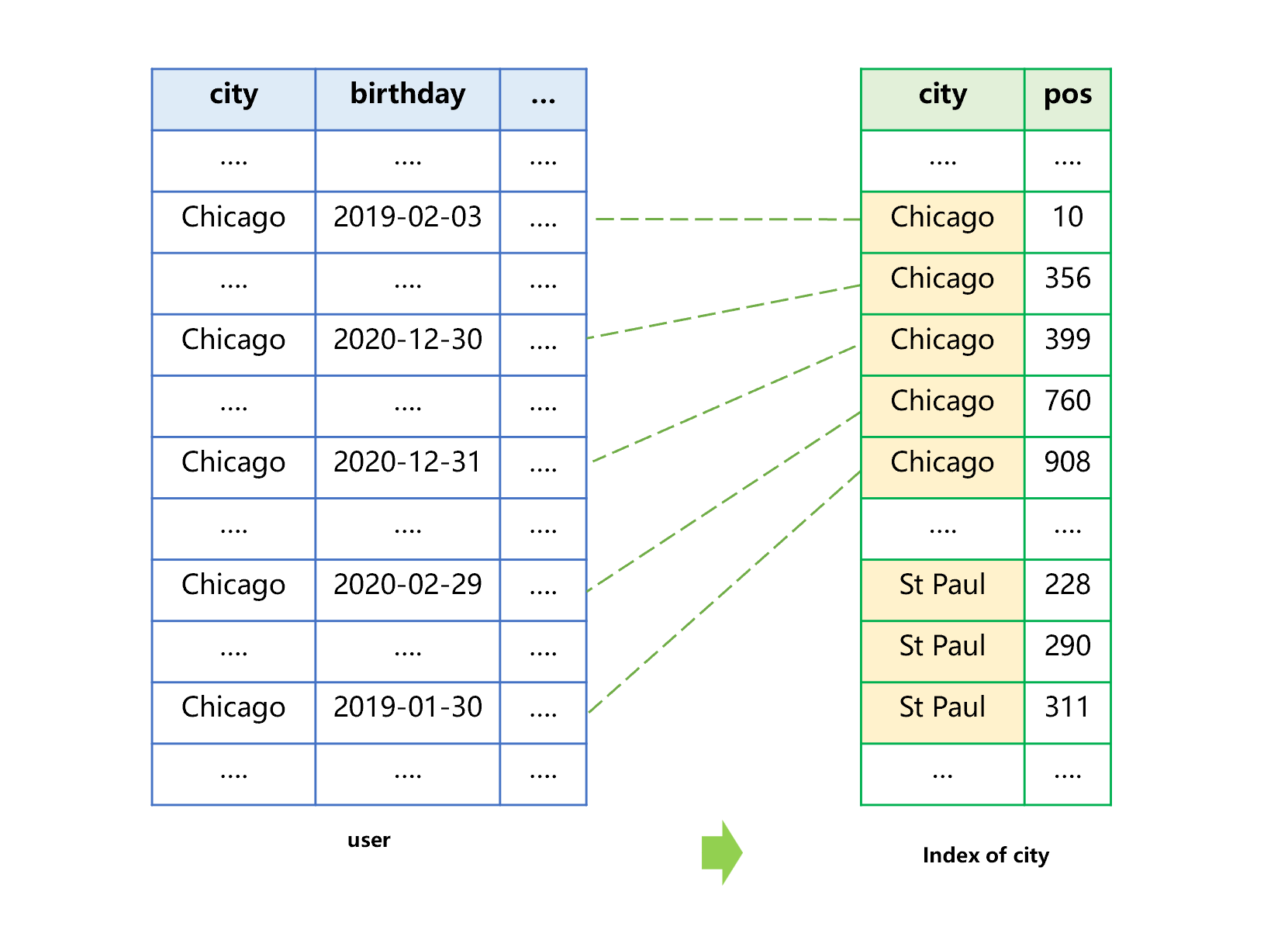
图 1 按照城市建立索引
建立索引时,是将城市排序后,和记录在原表中的位置 pos 一起存入索引。为了方便理解,我们用自然数来表示原表中的位置,数值越大位置越靠后。
从图 1 可以看出,生成索引的排序过程中,并不会改变 Chicago 多条记录之间在原表中的先后顺序。所以在索引中,不仅会将相同的城市(例如 Chicago)存储在一起,而且相同城市多条记录的原表位置 pos 也是从小到大排序的。
同样,按照生日建立索引的过程,也是这样的。参见下图 2:
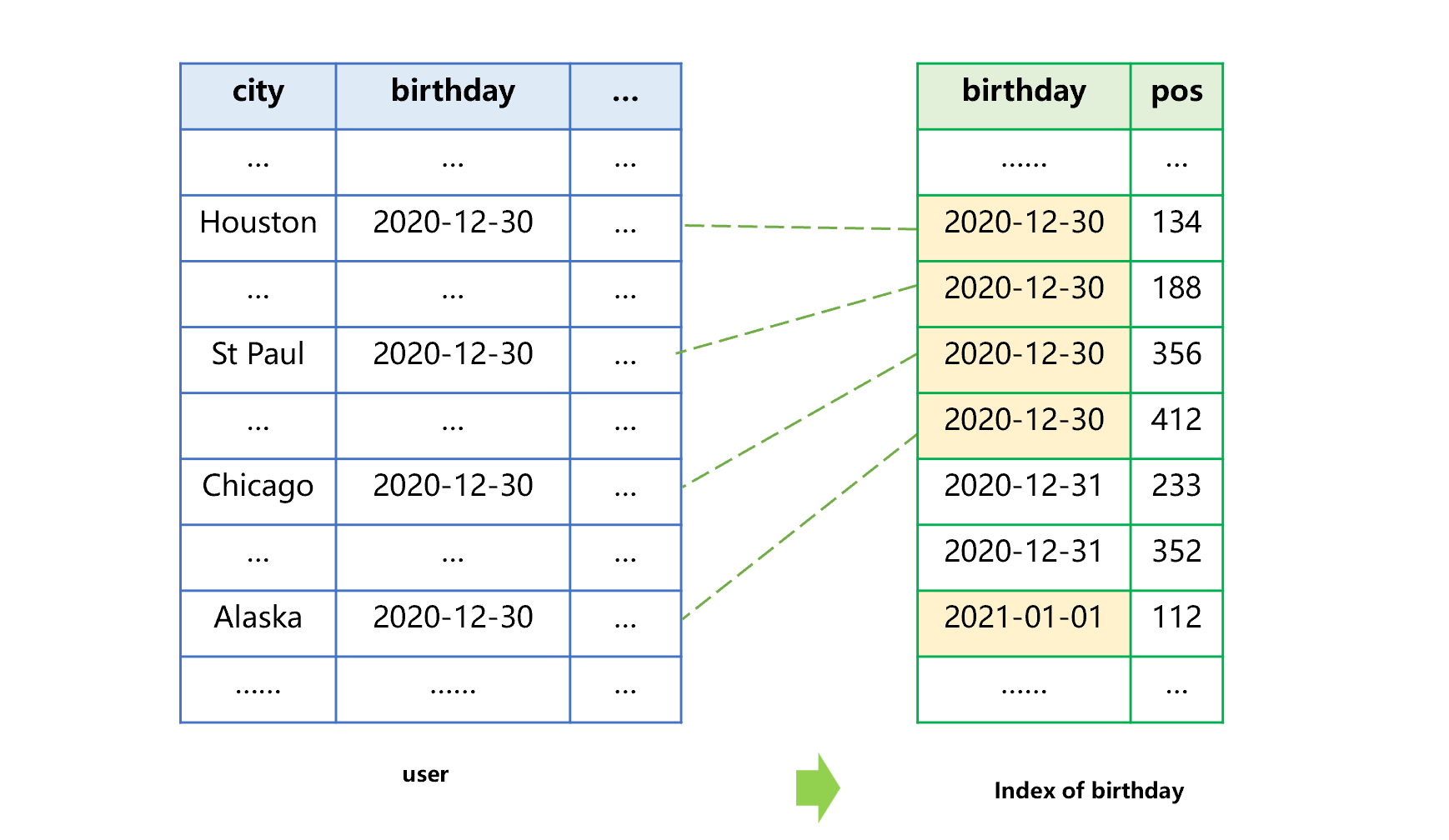
图 2 按照生日建立索引
建立两个索引后,用城市的索引,可以快速定位出城市是 Chicago 的用户,如下图 3 所示:
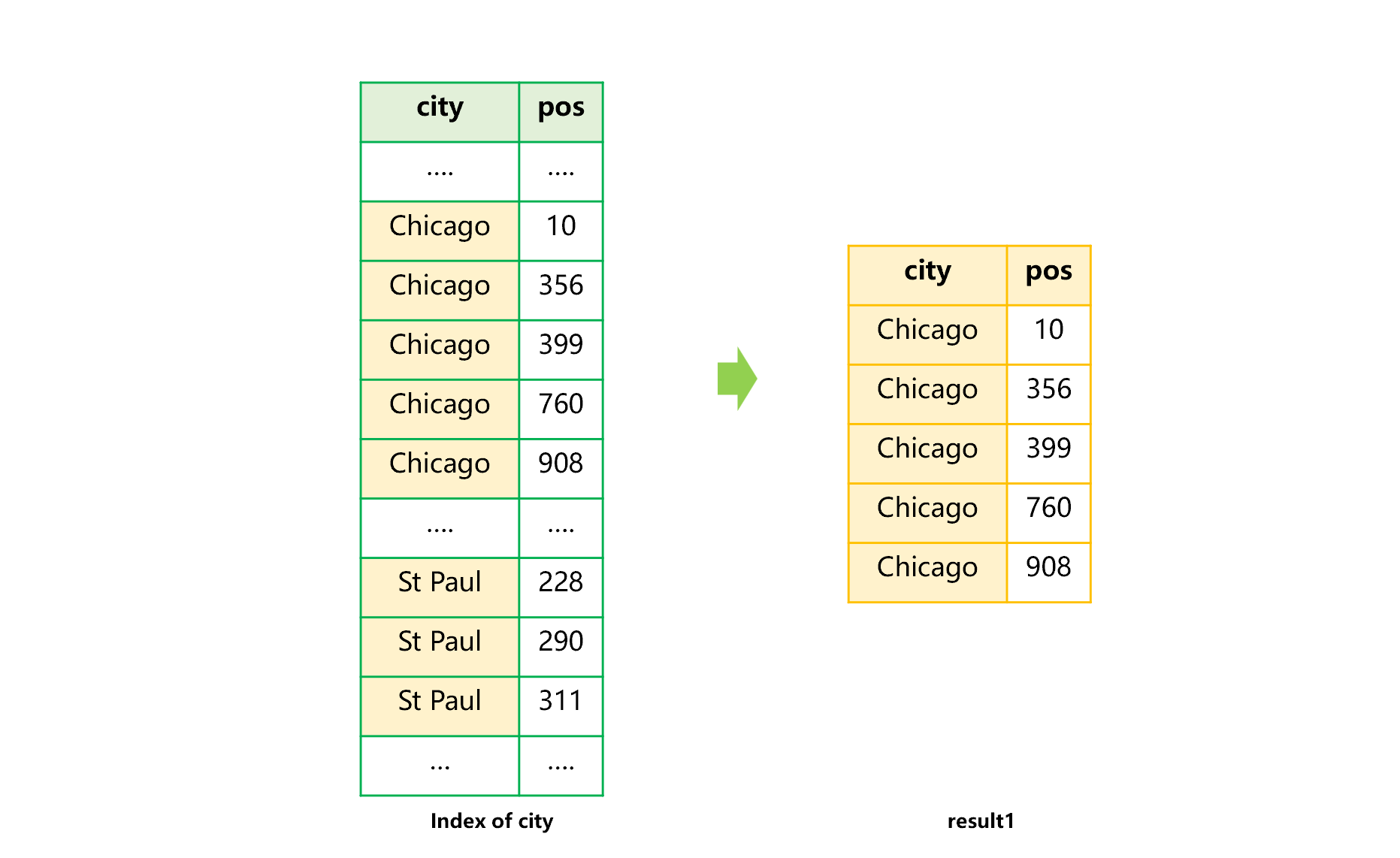
图 3 用城市索引查找 Chicago
图 3 可以看到,要从结果 1 中,继续查找生日 =2020-12-30,是无法直接使用生日索引的。
类似的,用生日的索引可以快速定位出 2020-12-30,如下图 4 所示:

图 4 用生日索引查找 2020-12-30
同样,要从结果 2 中再找出城市 Chicago,也无法直接使用城市索引。
SPL 的多索引归并技术,可以利用城市和生日的两个索引配合工作,查找到最终数据。多索引归并要用到结果 1、2,大致过程是下面图 5 的样子:
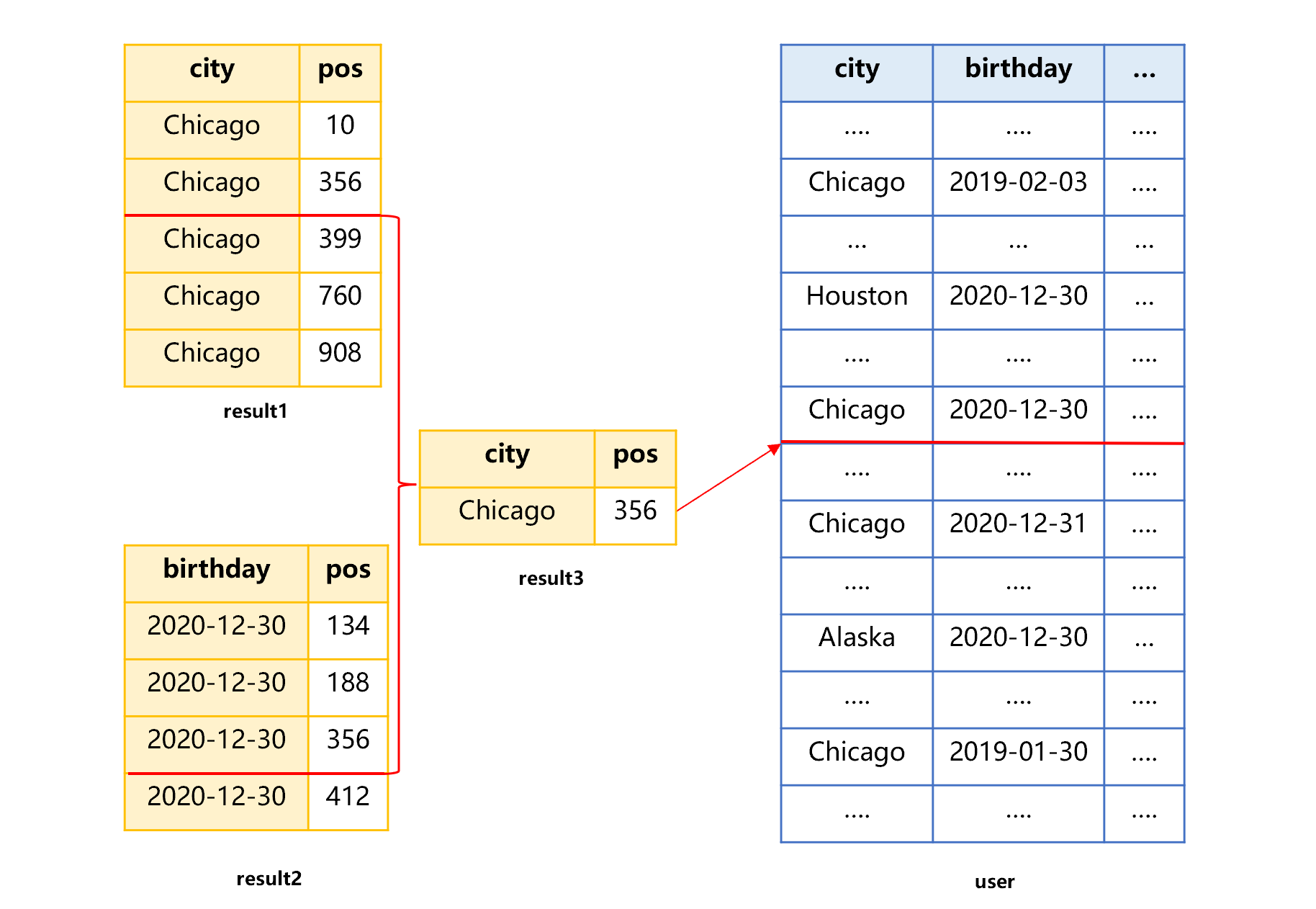
图 5 多索引归并
图 5 中,结果 1、2 都对记录的物理位置 pos 有序。那么,只要用归并算法求它们的交集 result3,就是满足城市和生日两个条件的索引了。再利用 result3 中的记录位置,可以取出用户表满足条件的记录。
但是,这个算法在复杂度上不一定比在满足城市条件的记录中,遍历计算生日条件是否成立更有优势,因为后者只需要针对满足城市条件的一个集合遍历,而多索引归并的算法要遍历 结果 1 和结果 2 两个集合。
多索引归并的优势在工程方面,归并求交集时不需要读出原数据表的记录来计算生日是否成立,只需要对比索引即可。而索引块有可能已经在内存中,或即使在外存也是连续存储、只有两个列(被查找字段和物理位置)、行存格式,读取性能要远好于多个字段、存储不连续、列存格式的原数据集,这样归并对比的性能就会好于读出记录再做判断。
如果我们选择结果 1 和结果 2 中较小的那个作为基准去归并另一个较大的,这样只要小的已遍历完就可以停止归并了,大的中尚未遍历完的成员都可以放弃了。这样总的遍历次数也不会很大。而建索引时通常能够知道结果 1 和结果 2 的记录数。
多索引归并也适用于更多个字段上都有条件的情况。
对于写在游标上形如 city==“Chicago” && birthday==date(“2020-12-30”) && …的多字段条件,SPL 会自动在给出的索引文件列表中找出可以利用的索引并实施归并,不需要程序员干预。
全文索引
结构化数据全文检索,是指查找某字符串字段是否含有某确定子串的记录。如果是形如 like(X, "abc*") 的条件,即子串会位于待查找字段的前部,则可以利用该字段的索引来快速定位。以国家表为例,要利用国家名称的排序索引查找 Ch 开头的国家,大致过程如下图 6:
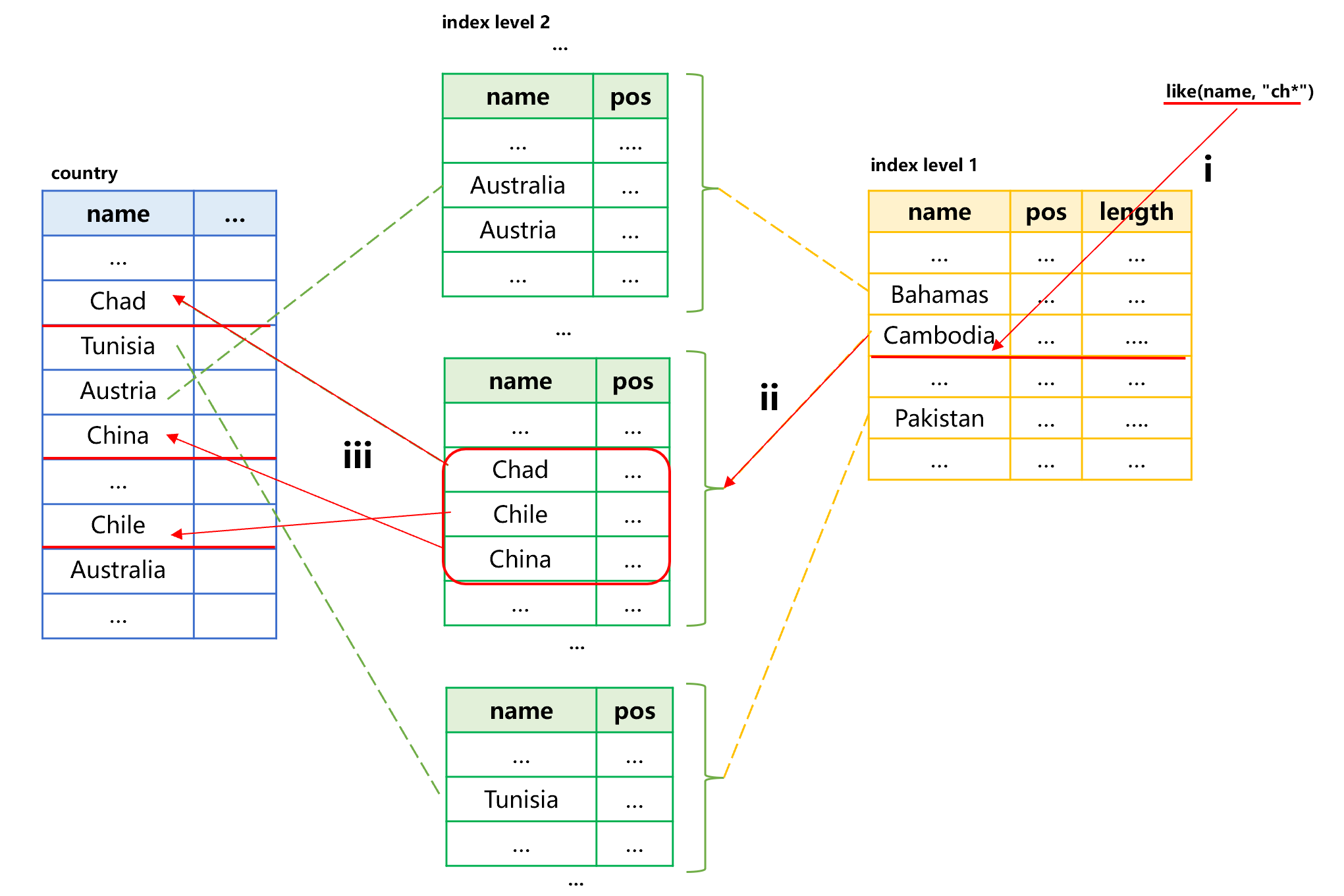
图 6 利用索引查找国家
图 6 中假设国家名称的索引是二级。由于索引对 name 有序,所以满足条件 like(name, "Ch*") 的记录在第 1、2 级排序索引中一定是连续存储的。查找第 i 步,先从一级索引中找到 Ch 开头的名称都在 Cambodia 段内,得到二级索引段的位置和长度。第 ii 步,按照位置和长度将二级索引段读入内存,找到 Ch 开头的第一个国家 Chad,继续遍历直到出现不以 Ch 开头的国家为止,就得到了所有 Ch 开头的记录在原表中的位置。第 iii 步,将这些位置排序,再去原表中取得目标记录。
SPL 发现 like(name, "Ch*") 这种条件时,就会自动检查原表是否有排序索引并加以利用。
如果子串位于待查找字段的中间,就没法再利用排序索引或哈希索引了,而是需要建立针对文字的索引,也就是全文索引。
例如,对帖子表 post 的内容 content 字段建立全文索引,查找内容字段包含 water 的记录,形如 like(content,"*water*")。
SPL 建立全文索引的过程大致是下图 7 这样:
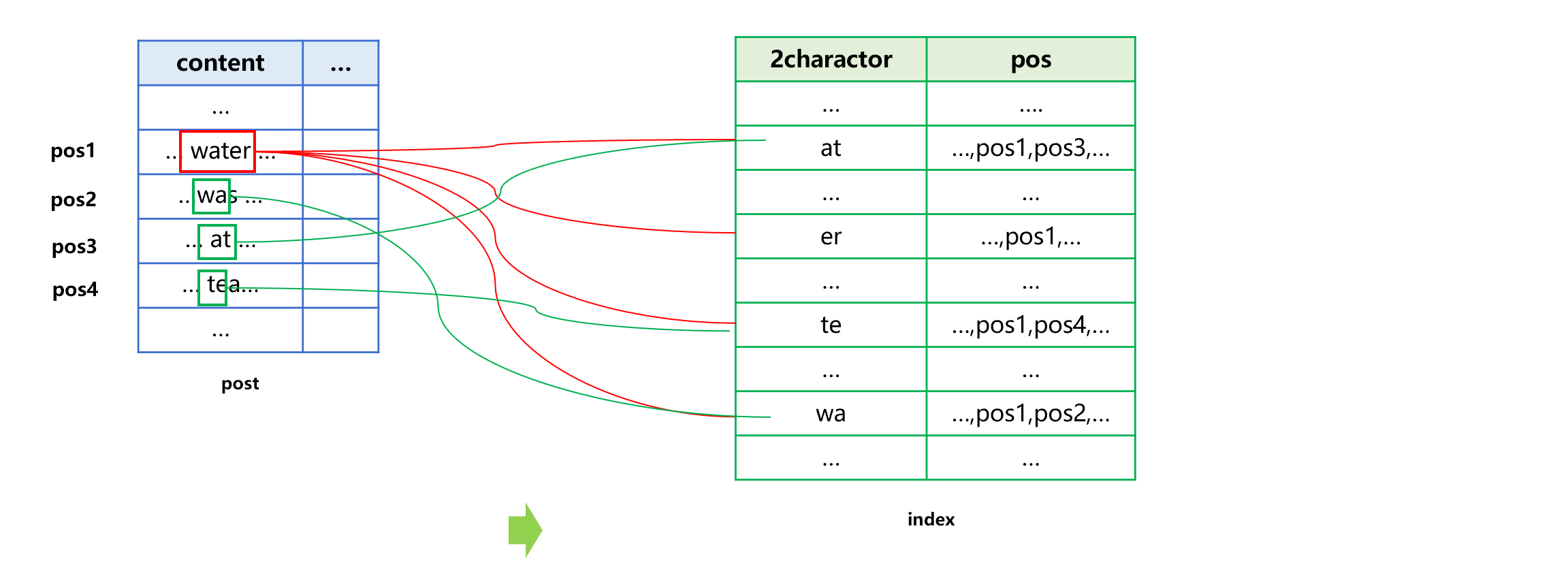
图 7 建立全文索引
首先,要将 content 中的字符串拆开,取出其中所有出现过的两个(或三个)字符的组合情况。比如 pos1 记录 content 中的 water 就提取为 wa,at,te,er 四个组合,连同 water 所在记录的位置 pos1 一起保存下来。
每条记录的 content 字符串都要这样提取,比如 was 拆分为 wa、as,也要连同这两个组合所在记录出现的位置 pos2 一起存储下来。wa 已经出现过,所以合并存储。
所有记录的 content 都抽取之后,对全部组合排序,和对应的记录位置一起存入全文索引。
用这种办法建出来的索引不会很大。常用字符大概有几千个(汉字和英文字符),如果只取两个字符,这种组合数最多也就是几千乘几千个,大概百万到千万级,并不是很大。如果是取到三个字符,大概会几十亿到百亿规模,现代好一点的服务器也都能支撑住。
有了全文索引,就可以用来查找包含 water 的记录了。大致过程是下图 8 这样:
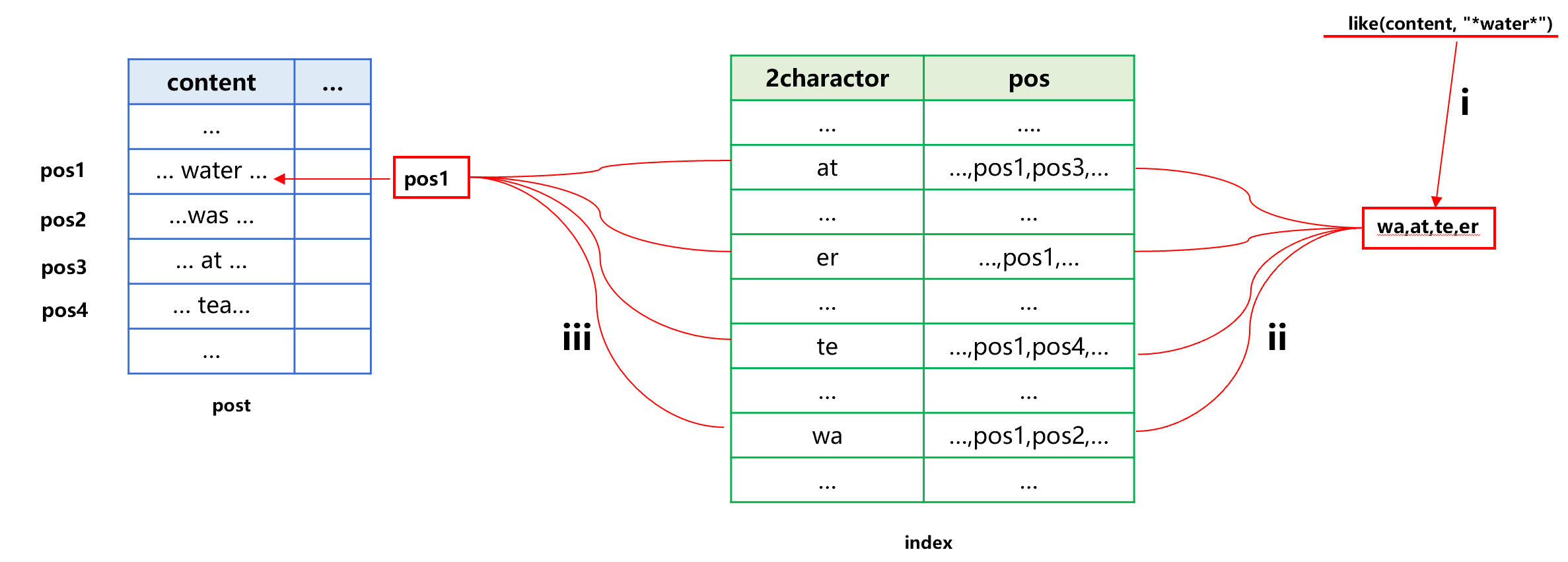
图 8 利用全文索引查找
图 8 中第 i 步,将要查找的 water 提取为 wa,at,te,er 四种组合。第 ii 步,从全文索引中分别查出四种组合对应的结果 1 到结果 4。第 iii 步,采用索引归并技术,计算出结果 1 到 4 的交集。将交集中的原表记录位置排序后取得原表记录,得到一个新集合。
这个新集合中一定有 wa,at,te,er 四种组合同时出现,但是并不一定就是 water。所以,还要在这个新集合中进一步查找 like(content,"*water*"),得到最终结果。
从上述介绍可以看出,全文索引相比硬遍历大幅减少了计算量,而且不需要搜索引擎那种高成本的全文检索技术。
SPL 的全文索引代码大致是下面这样:
A |
|
1 |
=file("post.ctx").open() |
2 |
=file("post.idx") |
3 |
=A1.index@w(A2;content) |
4 |
=A1.icursor(like(content,"*water*");A2) |
A3中使用 index@w 建立全文索引,存入索引文件post.idx,目前使用的是两字符方案,在很多场景也够用。
A4 在查找时指定索引文件 A2 后,就直接使用 like 作为条件即可。


英文版