


SPL 的外存索引
外存索引是在原表之外建立的,被查找字段值和原表记录物理位置的关联表。在查找时,用指定值从这个关联表中迅速获得原表物理位置,再去读取原表记录。
这样,索引中会存储很多被查找字段值。要在其中找到指定值,也会用到本来要用于原表的查找动作。所以,我们要专门设计索引的结构,提高在索引内的查找速度。
哈希索引
外存哈希索引,是计算出原表中被查找字段的哈希值,按哈希值依次将被查找字段值和对应的原表物理位置存储起来。相同哈希值的记录存储在一起。
通常原表数据量都很大,索引也会大到内存装不下。这时还要为索引本身建立一个小索引。以外存表 data 为例,建立主键 id 字段的哈希索引的大致过程如下图 1:
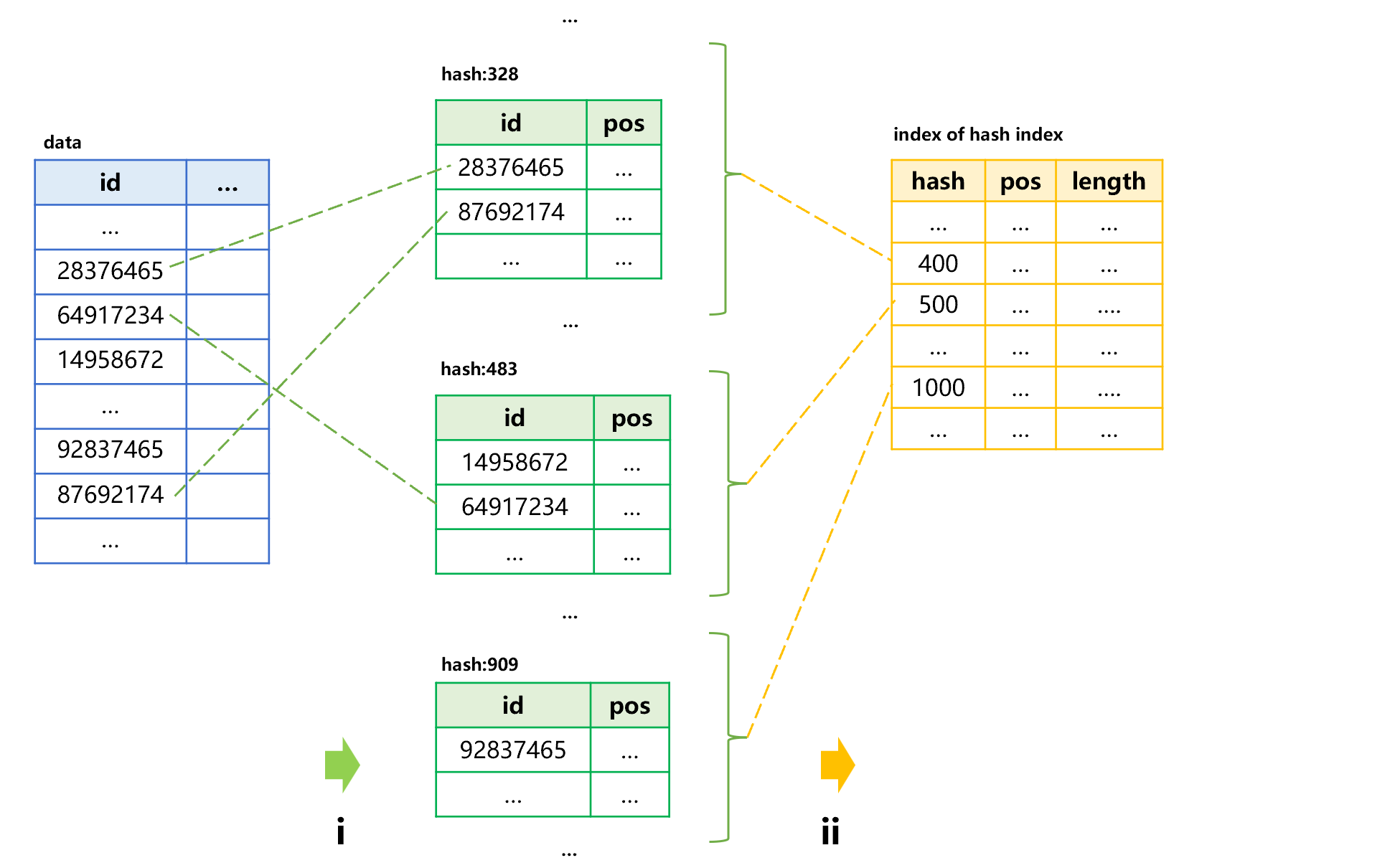
图 1:建立哈希索引
图 1 中第 i 步,计算 data 表 id 字段的 hash 值。按照 hash 值顺序分段存储到外存的哈希索引中。由于预先知道哈希值的范围,所以能确定分成若干段。比如图 1 中哈希值在 1-100 的存为一段,101-200 再存一段,保证每一段都足够小而能装入内存。图 1 中第 ii 步,在索引头部保存一个固定长度的小索引,用以记录每一段存储的哈希值范围以及这一段的物理位置和长度。
建好哈希索引后,就可以通过索引查找指定的 id 了,大致过程如下图 2 所示:
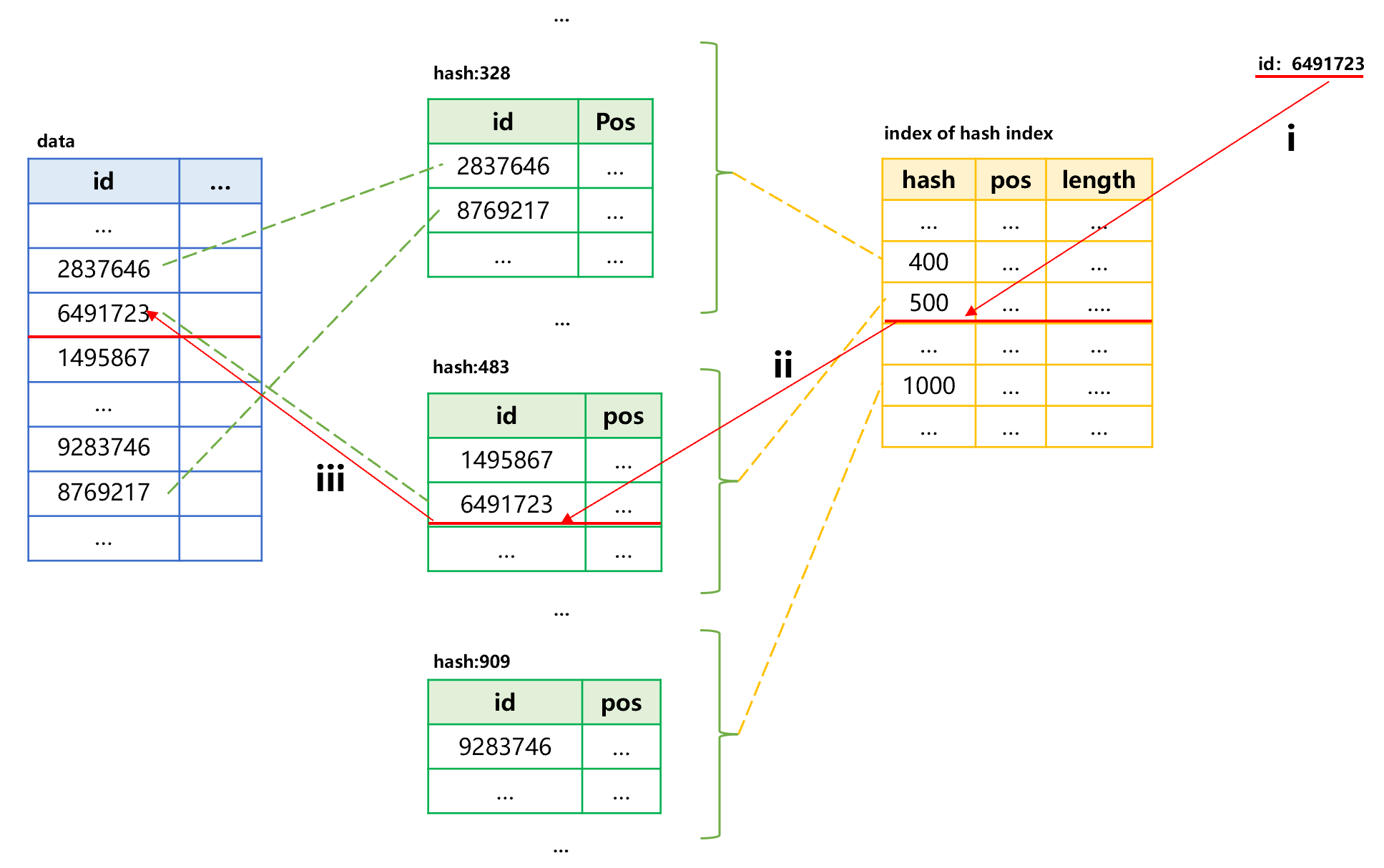
图 2 利用哈希索引查找
图 2 第 i 步根据指定 id 值 6491723 计算出哈希值是 483,在 401-500 这一段。将小索引读入内存,查找到这一段的起始位置和长度。这时候可以使用内存查找技术,通常每段的哈希值为按次序存储的,就可以使用二分法,如果每段存储的哈希值数量固定,还可以用序号定位。
第 ii 步,将哈希索引的这一段读入内存中,采用内存查找技术找到 id 值为 6491723 的记录,得到原表中对应的位置。
第 iii 步,利用位置在原表中读取目标记录。
这样,先读取小索引, 再读取哈希索引段,最后再读取原表。共读取 3 次就找到目标值了。而且小索引可以常驻内存,多次查找时就不用再反复读入了。
以上是假设小索引能装入内存中,但是数据量非常大时,可能小索引也大到内存装不下了。这时要为这个小索引再建立一级小小索引。也就是说,索引可能会分成多级。我们用加载次序来表示索引的级数,最初装载的最小索引部分称为一级索引,通过一级索引找到合适的二级索引,再找到三级、四级(四级已经足够大了),最后一级就能定位目标值的物理位置。每次查找最多读取的次数就是索引的总级数再加将目标读出的那一次,第一级索引还可以常驻内存而不需要反复读入。
哈希索引有个问题在于,哈希函数的运气可能不好,导致某一片哈希值下对应的记录数太多而无法存储在一个索引段之内。例如,图 1 中 hash 为 401 到 500 的记录太多了,一个索引段存不下。这时候就需要再做第二轮哈希,换个哈希函数把这些记录重新分布一下。运气再不好可能还会有第三轮、第四轮、…。结果会导致,哈希索引的级数不是固定的,对某些查找值来讲有可能会有更多级。
SPL 建立和利用哈希索引查找的代码大致是这样:
A |
|
1 |
=file("orders.ctx").open() |
2 |
=file("orders.idx") |
3 |
=A1.index(A2:1000000;id) |
4 |
=A1.icursor(;id==123456;A2).fetch() |
A3 为组表 A1 创建索引,被查找字段为 id,索引文件是 orders.idx。创建哈希索引时还需要给出哈希值的范围,这里是 1000000。
A4 就可以使用相应的索引文件 A2 查找了。
排序索引
外存中更常见的是排序索引。
哈希索引只能针对查找值做等值查找,即判断条件是相等;而不能做区间查找,即判断条件是被查找键在一个指定区间。而且,哈希索引在运气不好的时候还可能出现二轮哈希,其性能不够稳定。排序索引就能够解决这些问题。
排序索引的原理,就是在索引中将被查找键值有序存储,然后使用二分法找到查找值对应的目标值的物理位置。这种方案既可以做等值查找,也可以做区间查找。
工程实现时,不能简单地直接针对索引做二分查找,仍然和哈希索引类似,将索引分成若干段,并为这些段建立一个小索引。先读出小索引,用二分法找到查找值对应的索引段,再读出索引段找出目标值的物理位置。小索引也可以常驻内存减少读取量。
同样的,当数据量很大时,索引也会再分级。不过排序索引可以事先确定每个索引段存储的记录数,不会出现哈希索引那种运气不好导致第二轮哈希的现象。如果每级存储 1K 个值,分到四级就可以对应 1K*1K*1K*1K=1T 条记录的庞大规模,已经足够用了,一般三级就够了。
排序索引做等值查找时,在每级索引中要做二分查找,比哈希方法的直接定位稍慢一点。但外存查找的主要时间消耗在数据读取,而不是 CPU 运算,所以两者差别不算很大。由于排序索引的适应面更广,所以绝大多数的外存索引都是排序索引。只有个别有极端性能要求,且只需要实现等值查找的场景才会使用哈希索引。下文中再提到外存索引,如未声明都是指排序索引。
SPL 缺省的索引就是排序索引。
A |
|
1 |
=file("data.ctx").open() |
2 |
=file("data.idx") |
3 |
=A1.index(A2;id) |
4 |
=A1.icursor(;id==123456;A2).fetch() |
5 |
=A1.icursor(;id>=123456 && id<=654321;A2) |
index 函数中不指明哈希范围的就认为是建立排序索引。
A5 中基于排序索引还可以执行区间查找。
我们之所以不把原数据表直接按被查找字段排序,而另外建立排序索引,主要是因为索引占用空间更少。索引中只有被查找字段和物理位置,相当于两个字段的数据表。而原数据表常常几十甚至上百字段,比索引要大得多,如果整个表都排序,要多占一倍的空间。
而且,即使数据有序,针对原数据表执行二分查找仍然没有使用索引的性能好。前面也说过,直接的二分法没有多级索引,也不能精确定位,还会有不少无效的读取动作。简单二分法通常在性能要求不是很高、同时不想维护索引的场景。索引虽然比原数据小,但空间占用仍然可观,在数据追加时还要同时更新。
索引的本质是排序。哈希索引本质上也是排序,只是用了待查找字段值的哈希值来排序。
有时我们需要用两个字段作为被查找键,理论上这和单个字段并没有区别,只是比对动作复杂了一点。不过,理解索引的本质是排序后,还可以指导这种索引的建立。
比如用户表中城市 city 和出生日期 birthday 都会被查找。我们可以对两个字段单独建立索引,就像下图 3 这样:
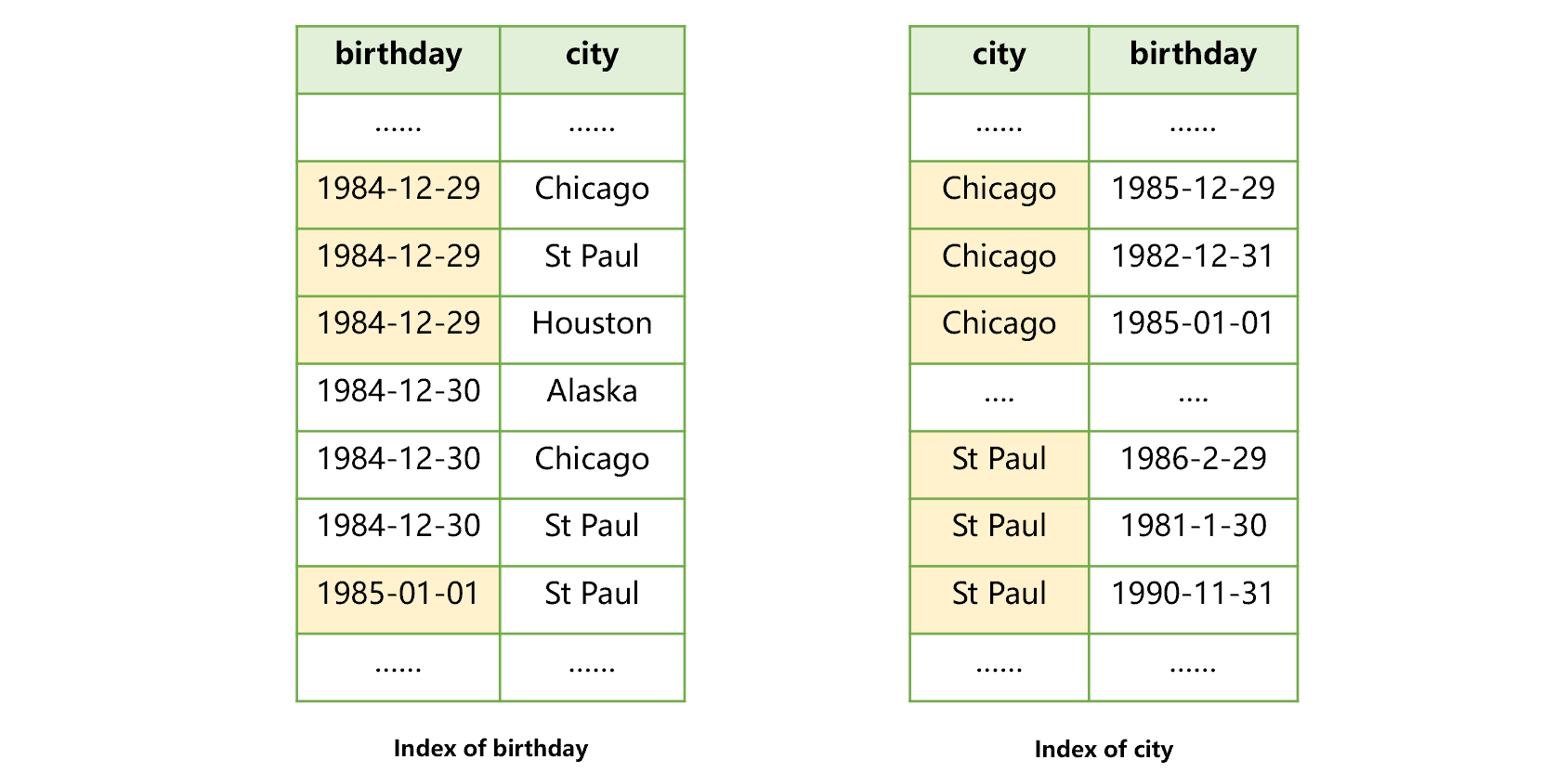
图 3 对两个字段单独建立索引
这样做对于生日和城市两个条件查找有帮助,但只能用到其中一个索引。比如利用图 3 生日索引查找到 1984-12-29 出生的用户后,这些记录的城市字段并不是有序的,所以不能再使用这个索引查找 St Paul 了。
我们也可以建立针对生日和城市的联合索引,比如下图 4 这样:
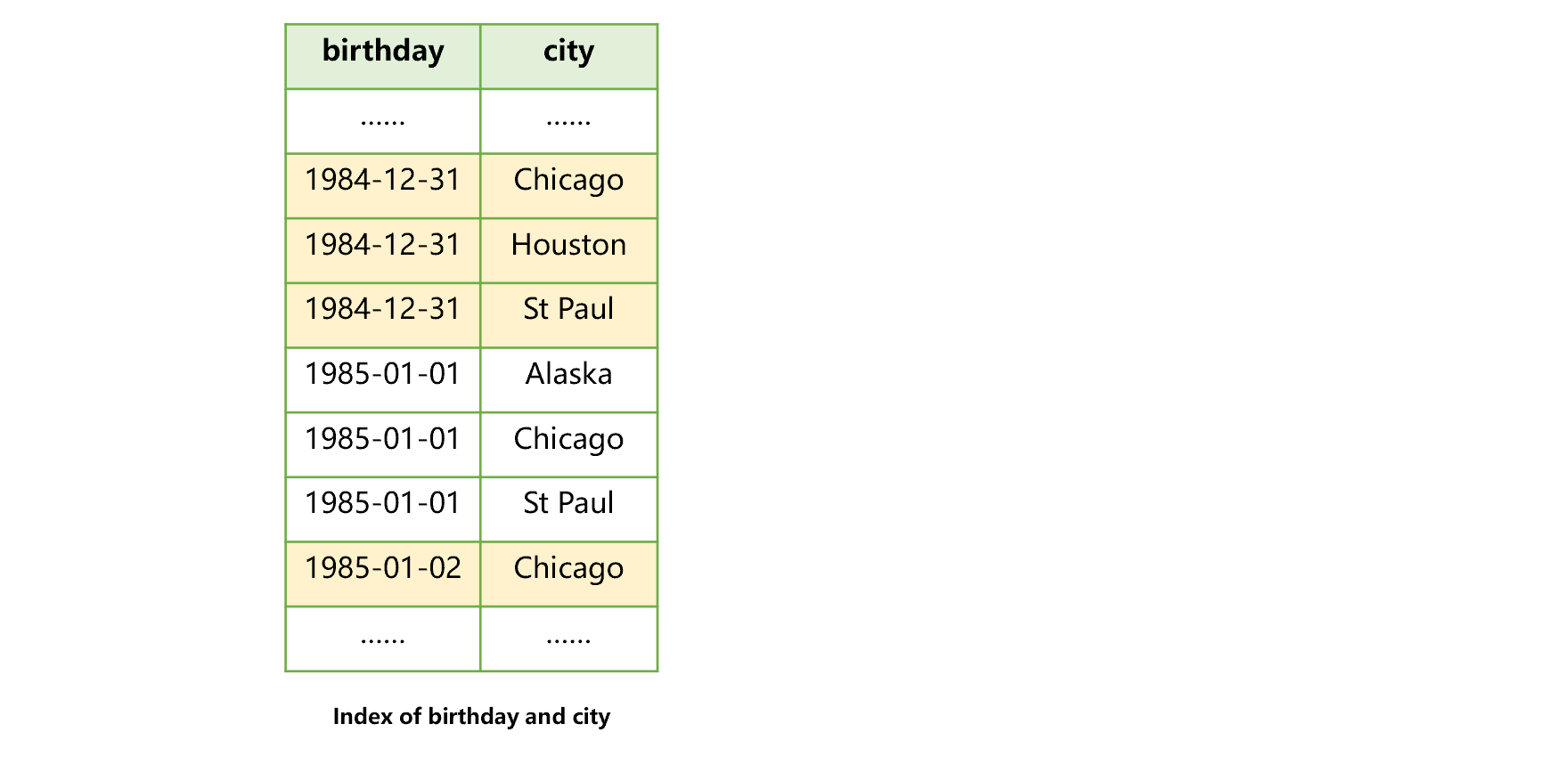
图 4 生日和城市的联合索引
使用生日和城市的联合索引,可以先查找生日再查找城市。也可以用于针对生日一个字段的查找。但是不能用于针对城市一个字段的查找,也不能用于先找城市再找生日。
如果空间允许,可以建立两个索引,即针对(生日、城市)和(城市、生日)分别建立索引。这样针对两个字段单独查找和联合查找都可以利用索引了。如下图 5 所示:
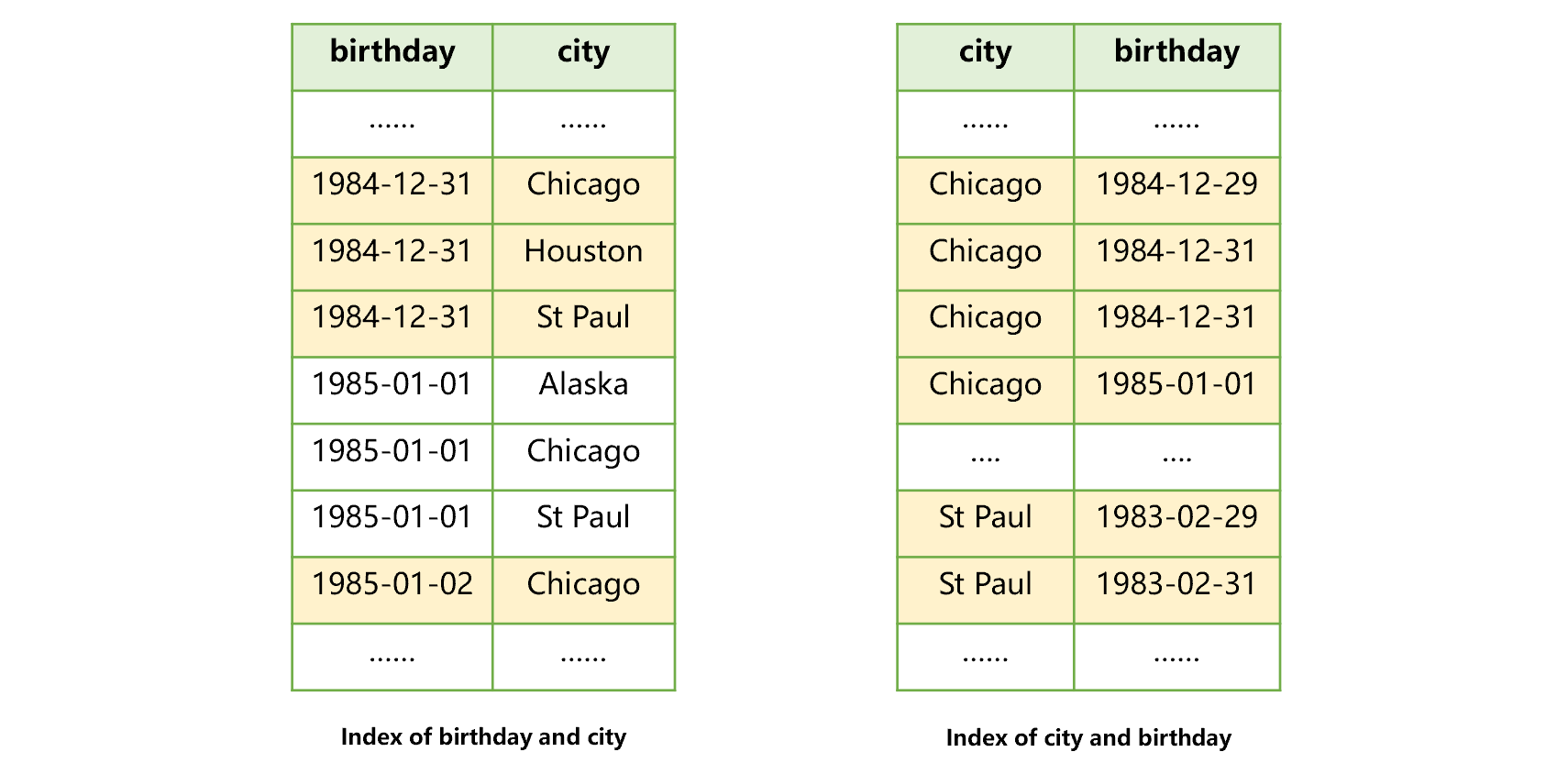
图 5 推荐的联合索引
有多个索引可用时,SPL 中实现了自动寻找最佳索引的机制,可以按照上述这些方法,在已有索引中找到最适合的,用以提高查找速度。
分级加载
大数据的索引经常也很大,需要建立多级索引,每次查找时都要一级一级地读入,才能最终定位到目标值。
有些索引要反复使用几百上千次,如果每次用到都重新加载,就会有明显延迟了。
SPL 提供自动缓存索引的机制, 已经使用过的索引会被缓存。在短时间内再次用到时就不会重复读取,能有效地减少查找延时。同时,SPL 还提供了主动预加载部分索引段的方法,系统启动时主动加载,之后的查找都会比较快,而不必等到这些索引段都被访问过。
SPL 组表的索引最多有四级。以三级索引为例,在内存允许的情况下,预加载的级数越多,性能越好。组表索引分级加载的大致情况,可以参考下图 6:
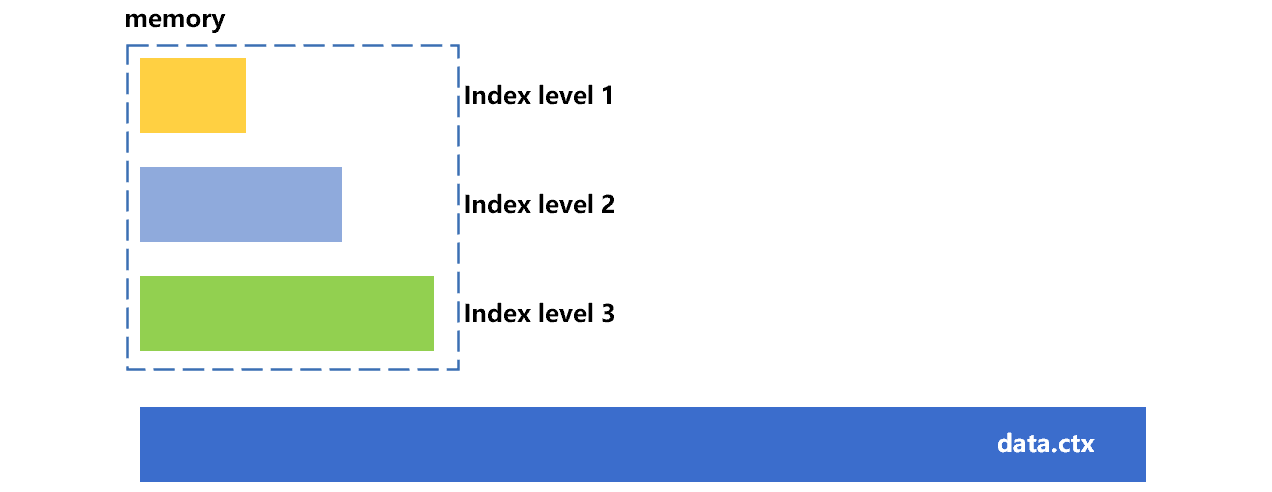
图 6 分级加载
每一级索引相当于是 1K 个待查找值,四级可以支持到 1T 条记录。前三级索引可能会占用到约几个 G 的空间。加载到三级索引后,对于记录数不超过 1G 的组表都不必再读索引段了,更大数据量的组表也只要再读一次索引段即可。
SPL 主动预加载分级索引的代码大致是这样:
A |
|
1 |
=file("data.ctx").open() |
2 |
=file("data.idx") |
3 |
=A1.index@3(A2) |
4 |
=A1.icursor(…;id==123456).fetch() |
index@3 表示预先将前三级索引段读入并常驻内存。
如果内存不足,也可以用 @2 只加载两级。
预加载的索引段缓存会全程存在,同进程的其它线程也会自动使用。
批量查找
在使用索引做外存查找时,除了前面讨论的单个查找值之外,还有多个查找值的批量查找。如果是在内存中查找,我们可以简单重复查找多次就可以了。对于外存查找,因为读取硬盘的时间相对于处理判断要慢得多,如果后面的查找能重复利用前面查找中已经读取的结果,即使代码复杂导致判断时间变多也常常是值得的,多查找值时就需要更细致的优化方法。
我们来观察一下利用外存排序索引实现批量查找的过程。假设数据表 data 表的 id 字段是自然数。data 的排序索引有两级,第一级可以装入内存。第二级第 1 个索引段对应 id 范围是 1-100,第 2 段对应 101-200,后面的索引段以此类推。
现在要利用索引,查找前端通过参数传入的 n 个给定值。为了容易理解,假设传入四个值为 143、98、177、355。查找第一个值 143 的过程大致如下图 7 所示:
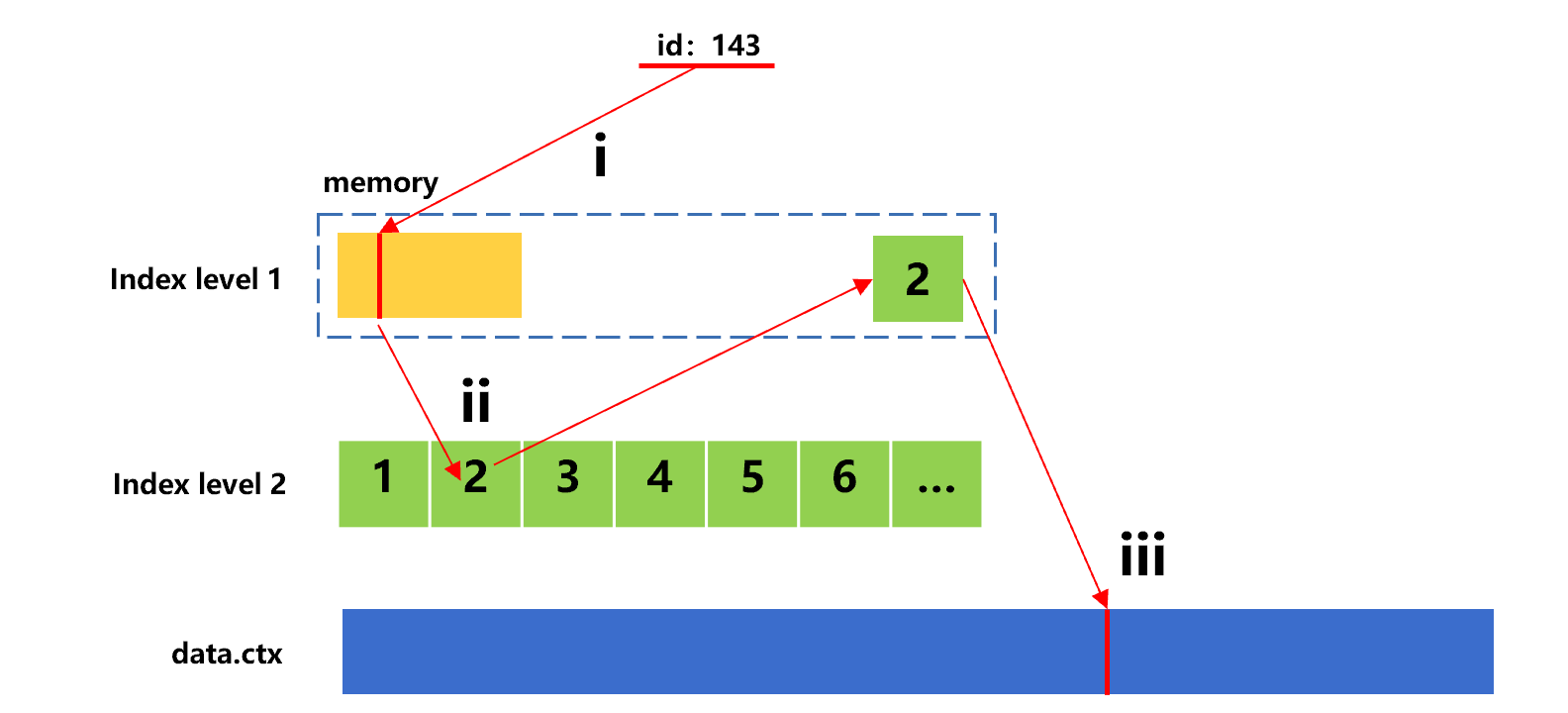
图 7 用排序索引查找第一个值
本次查找中,id=143 是在二级索引的第 2 索引段,所以第 ii 步要从硬盘上读取这个索引段。
继续查找第二个值 98 的过程,用下图 8 来示意:
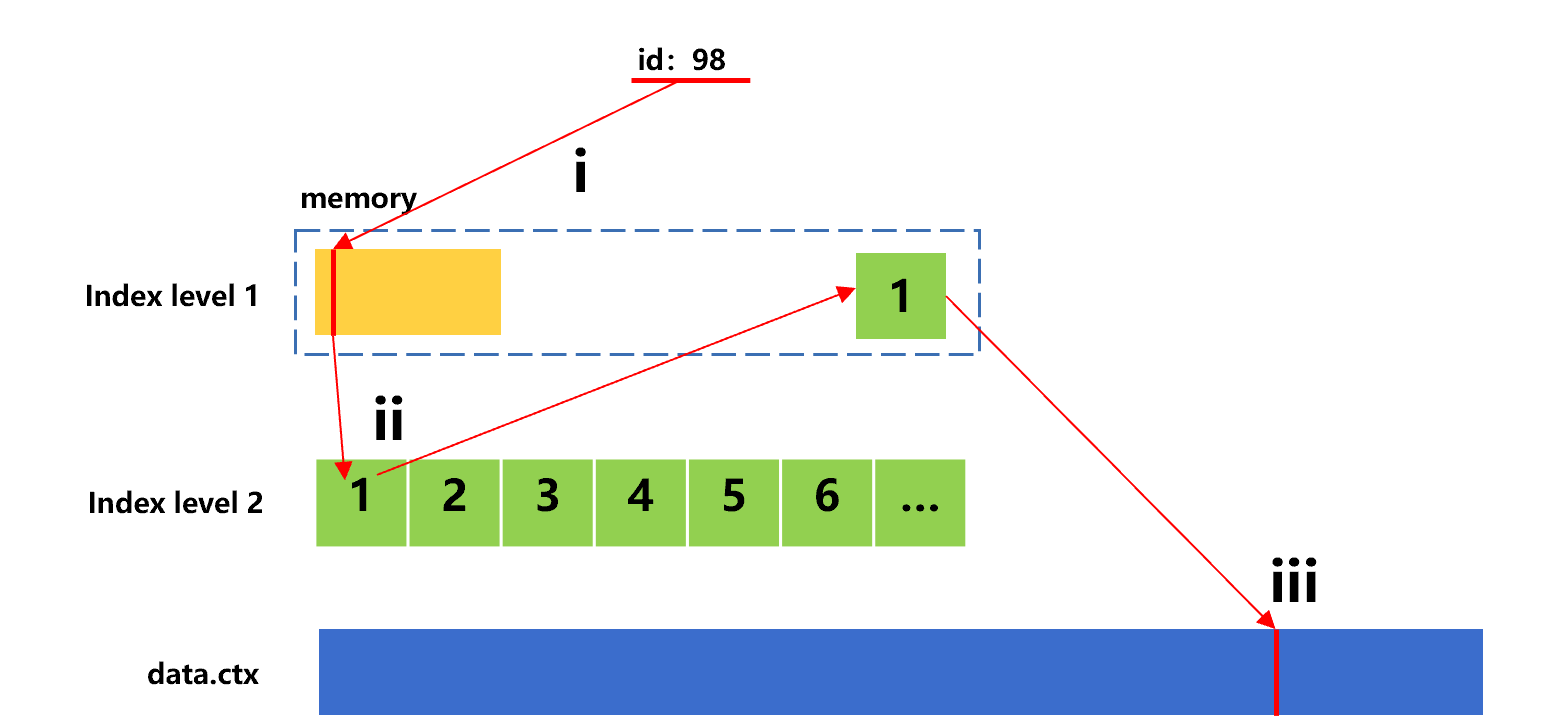
图 8 用排序索引查找第二个值
id=98 是在二级索引的第 1 索引段,第 ii 步要从硬盘上读取这个索引段。
再查找第三个值 177 的过程,用下图 9 来示意:
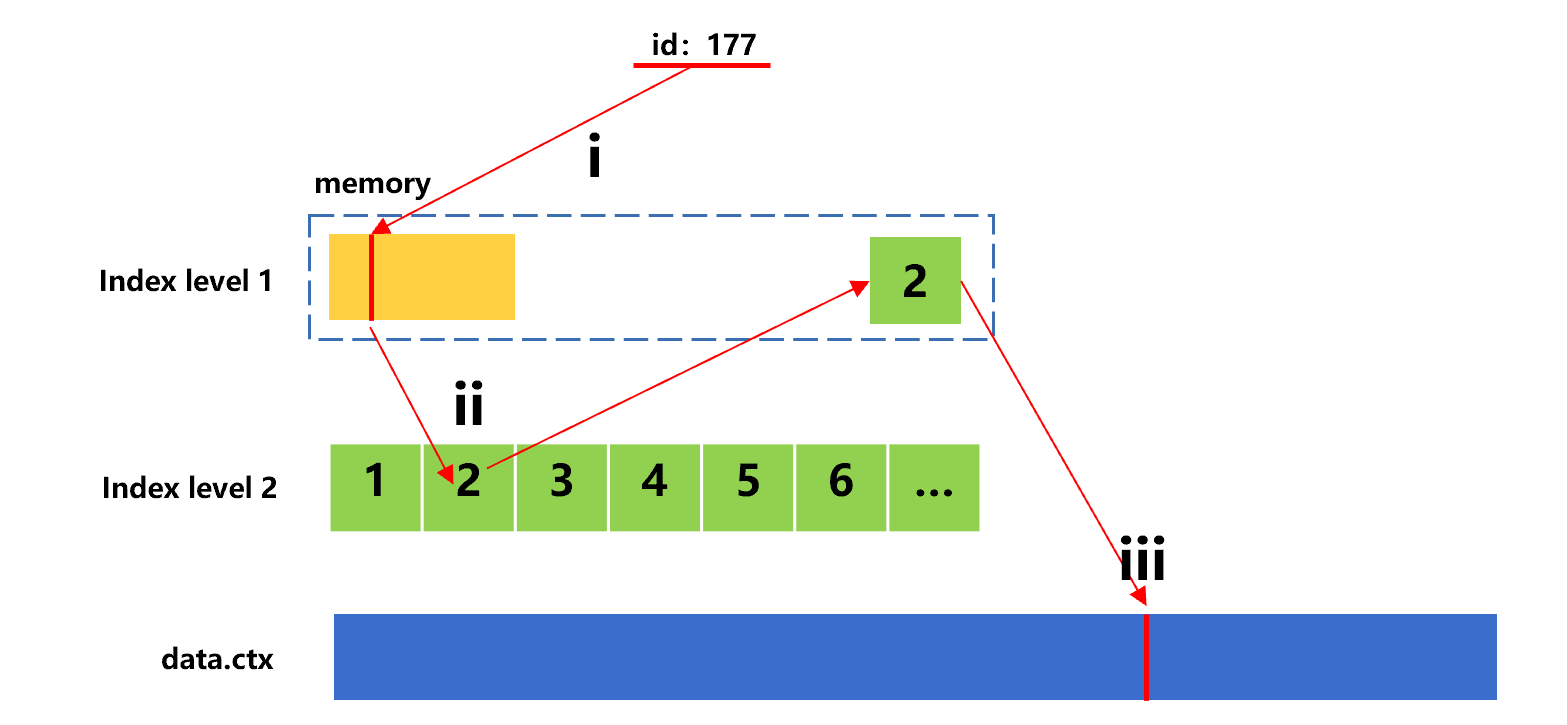
图 9 用排序索引查找第三个值
这时,id=177 也是在二级索引的第 2 索引段,图 9 中第 ii 步要再次从硬盘上读取这个索引段,也就出现了对索引段的重复读取现象。
在实际应用中,给定值的个数 n 会很大,这种重复读取索引段的情况会非常频繁出现。
我们可以把查找 143、98 用到的第 2、1 索引段都缓存起来。再查找 177 时就可以复用这些缓存数据而减少读取次数了。但是,当 n 很大时,我们会发现有可能需要缓存非常多的索引段,因为不能预测哪些缓存的索引段是否会在将来用得上。太多缓存数据会占用很大的内存,有时可能被迫要丢弃一部分缓存,结果就可能在后面的查找时发生重复读取某个索引段的现象。
SPL 提供了批量查找的优化方案,当我们将多个给定值排序后再依次查找,就可以从原理上避免出现重复读取索引段的现象。例如我们将四个给定值排序后,顺序变成 98、143、177、355。查找第一个值 98 的过程大致是下图 10 这样。
图 10 优化后用排序索引查找第一个值
继续查找第二个值 143 的过程参见下图 11:
图 11 优化后用排序索引查找第二个值
再查找第三个值 177 的过程参见下图 12:
图 12 优化后用排序索引查找第三个值
图 12 中,id=177 也是在第 2 索引段,我们可以继续使用查找 id=143 时候已经读取的第 2 索引段,而不会产生重复读取。
由于给定值是有序的,后边的给定值 177 一定大于前面的 143。而索引对查找字段也是有序的,所以查找 177 用到的索引段一定不会在 143 的索引段之前。如果这时用到的正好是上次查找读取的索引段,则可以直接使用。如果不是,那么可以确定,后续的查找再也不会用到前面读取过的索引段了,也就彻底避免了重复读取的现象。
SPL 索引最多四级。采用优化方案后,只要从第一级开始,逐级加载需要的索引段,数量不会太多,很容易在内存中放下。这样就能保证不会出现因丢弃而导致的重复读取。每次批量的查找值越多,总体优势就越大。
实际上,在图 10、11 和 12 中,第 ii 步在索引段中找到 98、143 和 177 的位置之后,还不能马上就做第 iii 步(从原数据表中读取数据)。要等待把所有目标记录的 4 位置都找出来,将这 4 个位置排序后,再去原数据表中读取数据。
原因是类似的,原数据表通常也会按块存储,每次读取一个数据块,如果两个目标值在同一个数据块中,那么只要读取一次就可以了。按位置排序后就容易复用目标值的数据块,否则,又可能发生重复读取原数据表中数据块的现象,导致时间浪费。
SPL 中已经内置了这些算法,代码是下面这样:
A |
|
1 |
=file("data.ctx").open() |
2 |
=file("data.idx") |
3 |
=10000.id(rand(1000*10000)+1) |
4 |
=A1.icursor(…;A3.contain(id);A2).fetch() |
A3:随机生成大量 id 值。
A4:使用 contain 作为批量查找条件,icursor 函数会先将 A3 排序后执行前面讲的优化方法。
另外,即使用了 SPL 的预加载索引,在数据量很大,需要用到四级索引段时,查找值排序仍然是有意义的。这时,预加载了前三级,不会重复读取。由于第四级索引段数量太多,只能临时读入。且前三级已经占用很大内存了,第四级的索引段用过之后就会丢弃,以减少内存占用。因此,查找值无序时仍然有可能出现重复读取的现象,而在前三级已经缓存之后,这部分时间在整个查找过程中的占比就会更明显。
列存索引
列式存储是提高性能的常用手段。使用索引技术时,列存和行存有很大的不同。行存数据记录的位置可以用一个数值表示,而列存时每列都有自己的位置,如果都存在索引中,占用空间太大,甚至会超过原数据。
SPL 列存索引并不记录每个列的位置,只记录内部序号,即可快速找到所有列。例如,用户表包括 id、名字(name)、性别(gender)等字段。为列存用户表 id 字段建立索引的过程大致是下图 13 这样的:
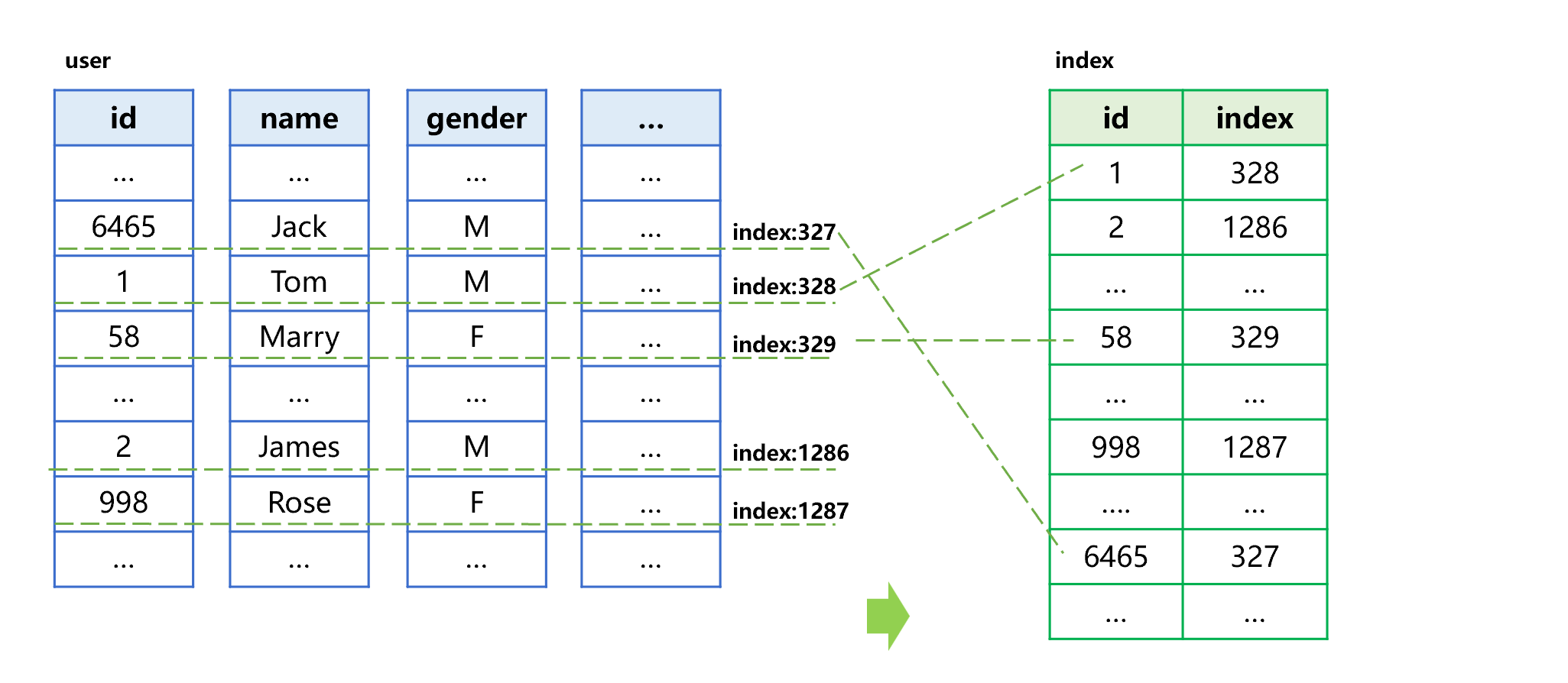
图 13 生成列存索引
生成列存索引时,按用户表的 id 字段排序后,和对应记录在原表中的序号一并存入索引。例如:索引第一条的 id 是最小值 1,对应记录在用户表第 328 行,则将序号 328 存入索引。以此类推,其他 id 值和序号顺序存入,最终生成索引。
图 14 大致描述了按照索引查找的过程:
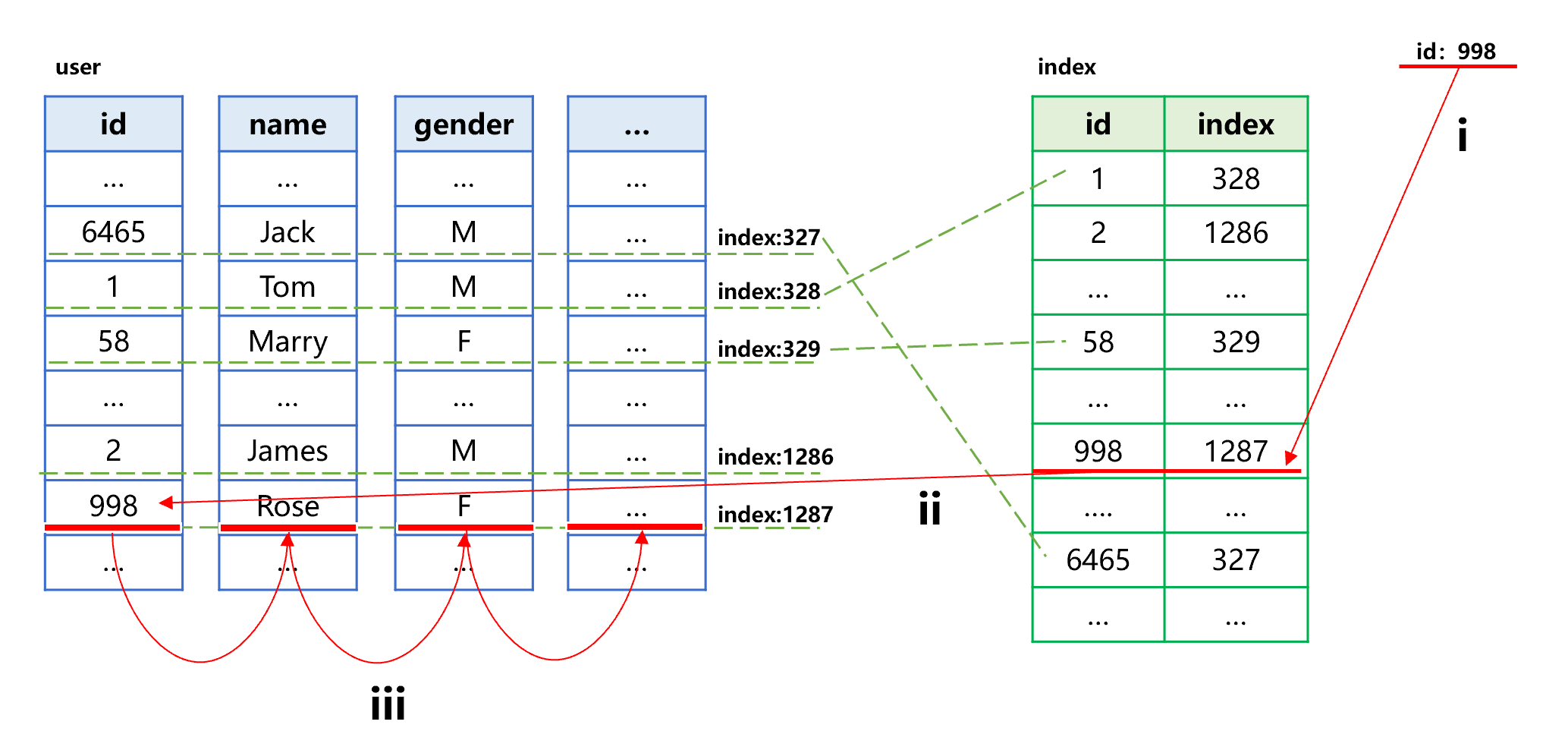
图 14 按照列存索引查找
查找指定 id 值 998 的第 i 步,在索引中找到 id=998,获得对应记录在原表中的序号为 1287。第 ii、iii 步,按照序号 1287 到原表各列的数据区中读取对应字段值。
SPL 的列存采用了倍增分段技术,可以比较快的按照序号找到各个字段值。但是,与行存直接按位置读取相比,列存还是要慢很多。从图 14 可以看到,读取原表时也要分别到各个列的数据区去读,而硬盘有个最小读取单位,这会导致各列的总读取量远远超过行存。而且,列存数据通常是压缩的,读取多少个列,就要解压缩多少次。总体来说,列存的查找性能要比行存差。
列存适合用于遍历计算,给定值的查找用行存会更好。
带值索引
SPL 提供带值索引技术,在建立索引时可以把其它字段值一起复制过来。例如,生成列存用户表的带值索引,过程大致是下图 15 这样:
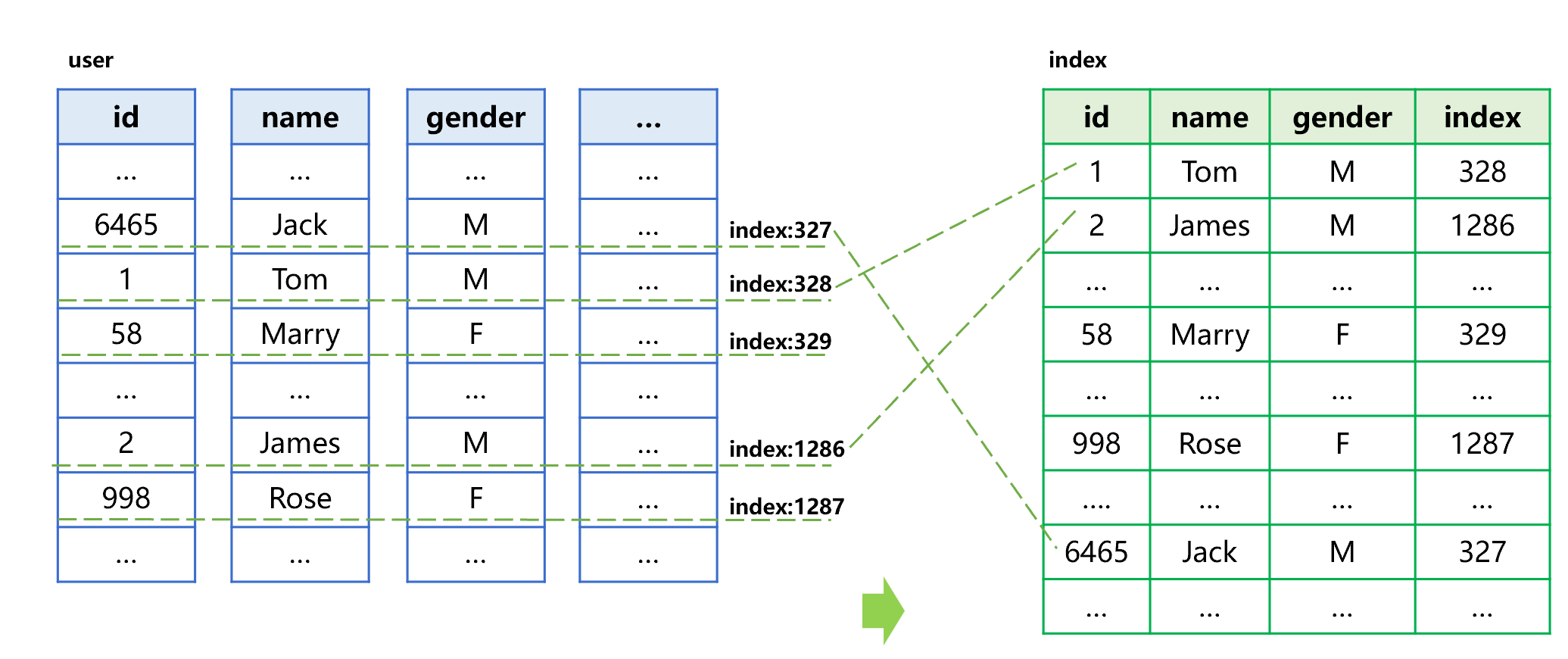
图 15 生成带值索引
和普通索引不同的是,带值索引中除了有排好序的 id 和原表序号外,还有查询需要的名字、性别字段。
图 16 描述了利用带值索引查找的过程:
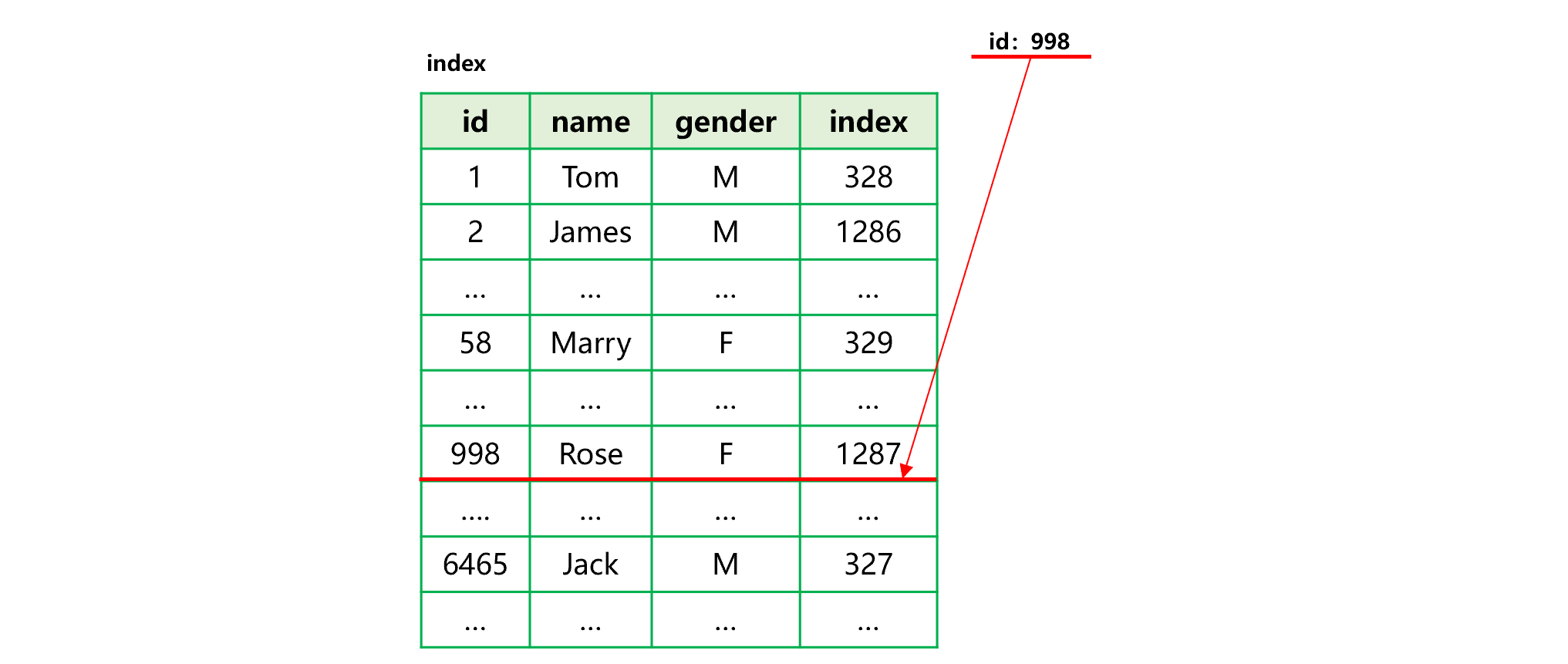
图 16 利用带值索引查找
索引采用行存且存储了名字、性别,在查找时如果只用到这些字段,就可以不访问原组表。这就相当于在行存数据中做查找,可以得到更好的性能。
这样,原组表继续采用列存用于遍历,带值索引用于给定值的查找计算,整体性能得到提升,且扩大了适用范围。缺点是带值索引中保存了更多的字段值,所以也会占用更大的存储空间。
带值索引的代码大致是这样:
A |
|
1 |
=file("user.ctx").open() |
2 |
=file("user.idx") |
3 |
=A1.index(A2;id;name,gender) |
4 |
=A1.icursor(id,name,gender;id==998;A2).fetch() |
5 |
=A1.icursor(id,name,gender;id>=123456 && id<=654321;A2) |
A3 建立索引时将要引用的字段写在 index 函数参数中,就可以在索引中复制这些字段值。A4、A5 取出目标值时,只要涉及字段在这部分内,就不必再读取原组表。
利用索引排序
前面介绍了索引的本质就是排序。SPL 提供了利用已有索引,将数据表按照对应字段排序的技术。例如,data 表已有按照 id 有序的索引,利用这个索引将 data 按 id 排序的过程大致如下图 17:
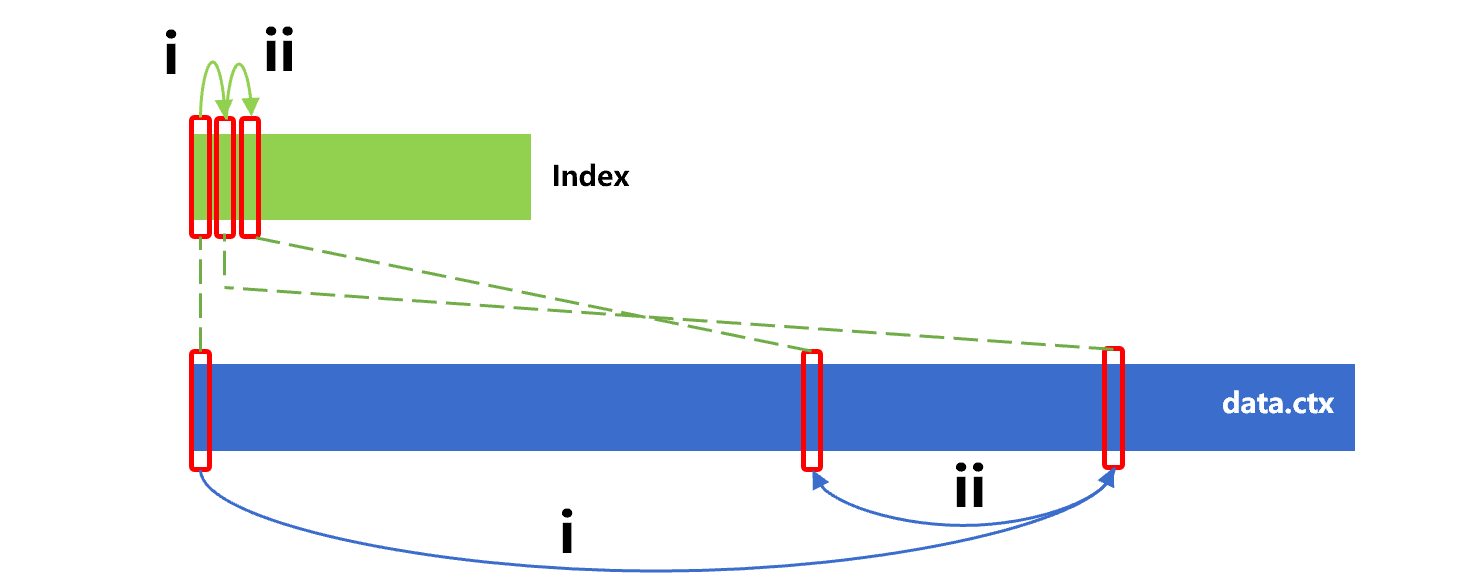
图 17 利用索引排序
图 17 中,顺序读取索引,按照索引中存储的记录物理位置,再去原表中读取原记录。由于索引是对 id 有序的,所以这样读取的结果也是对 id 有序的。
从图 17 可以看出,对索引的读取是连续的。但是,由于原表对 id 是乱序的,所以第 i、ii 步读取原表则是不连续的。而硬盘有最小读取单位,在读不连续数据时,会取出很多无关内容,性能会下降很多。综合算下来,也就很可能比直接对原表做大排序的性能还要差。
但是,按照索引排序的方法可以很快就开始输出数据,而大排序算法需要先把所有数据遍历完,生成外存缓存之后才能开始输出数据,会有个较长时间的等待期。
在有些场景下,这个优势就能发挥作用。比如把大数据按次序传输出去,远程传输本身很慢,常常比大排序快不了多少。如果能早点开始传输,就能节约很多时间。这时候用索引排序就有优势,这种算法马上就可以开始返回数据进行传输,而不必等待。
SPL 按照索引排序的代码大致是这样:
A |
|
1 |
=file("data.ctx").open() |
2 |
=file("data.idx") |
3 |
=A1.index(A2;id;…) |
4 |
=A1.icursor@s(…;;A2) |
icursor@s 将保证返回按指定索引排序的数据,无选项时不保证次序,但一般是按原表物理位置为序,这样速度更快。将返回成游标,然后可以 fetch 出数据做其他计算,比如去做传输。


英文版