


早下班系列 - 合并 Excel
日常工作中,经常需要把多个 Excel 文件的数据合并到一起,便于做各种统计分析。
1 纵向合并 - 列名列数相同
最简单常见的是把几个列名列数列顺序完全一样的文件,纵向合并到一起。
如:
Fruits.xlsx Meats.xlsx
合并前:  和
和
合并后:
实现代码:
A |
|
1 |
=file("Fruits.xlsx").xlsimport@t() |
2 |
=file("Meats.xlsx").xlsimport@t() |
3 |
=A1|A2 |
4 |
=file("Foods.xlsx").xlsexport@t(A3) |
2 横向合并 - 行名行数相同
一些行数一样,行名一样的 Excel 文件,常常需要横向合并到一起,如:
合并前:
Fruits.xlsx FruitStock.xlsx
和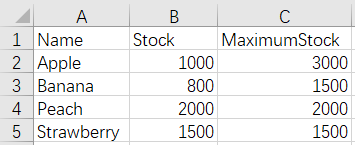
合并后:

实现代码:
A |
|
1 |
=file("Fruits.xlsx").xlsimport@t() |
2 |
=file("FruitStock.xlsx").xlsimport@t() |
3 |
=A1.new(Name,UnitPrice,A2(#).Stock,A2(#).MaximumStock) |
4 |
=file("FruitsPriceStock.xlsx").xlsexport@t(A3) |
3 纵向合并 - 列名列数不同 - 保留所有列
合并前:
FruitsPriceStock.xlsx MeatsPriceStock.xlsx

合并后:

实现代码:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=create(${(A1.fname()&A2.fname()).concat@c()}) |
/需要保留所有列,所以用列名的并集 |
4 |
=A3.insert@f(0:A1) |
|
=A3.insert@f(0:A2) |
||
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
4 纵向合并 - 列名列数不同 - 只保留重复列
合并前:
FruitsPriceStock.xlsx MeatsPriceStock.xlsx
合并后:

实现代码:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=create(${(A1.fname()^A2.fname()).concat@c()}) |
/只保留重复列,所以用列名的交集 |
4 |
=A3.insert@f(0:A1) |
|
=A3.insert@f(0:A2) |
||
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
5 纵向合并 - 列名列数不同 - 只保留第一个文件的列
合并前:
FruitsPriceStock.xlsx MeatsPriceStock.xlsx
合并后:

实现代码:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=A1.insert@f(0:A2) |
/@f的意思是把 A2 中同名字段的数据插入 A1 中 |
4 |
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
6 横向合并 - 行名行数不同 - 保留所有行
合并前:
Meats.xlsx MeatStock.xlsx
 和
和
合并后:
实现代码:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join@f(A1:Price,Name;A2:Stock,Name) |
/@f是全连接 |
4 |
=A3.new([Price.Name,Stock.Name].ifn():Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
/蓝色代码意思是选出不为空的 Name 值 |
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
7 横向合并 - 行名行数不同 - 只保留重复行
合并前:
Meats.xlsx MeatStock.xlsx
和
合并后:

实现代码:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join(A1:Price,Name;A2:Stock,Name) |
/内连接 |
4 |
=A3.new(Stock.Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
|
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
8 横向合并 - 行名行数及次序不同 - 只保留第一个文件的行并对齐
合并前:
Meats.xlsx MeatStock.xlsx
和
合并后:

实现代码:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join@1(A1:Price,Name;A2:Stock,Name) |
/@1是左连接,注意这里是数字 1,不是字母 l |
4 |
=A3.new([Price.Name,Stock.Name].ifn():Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
/ifn()在这里是选出不为空的 Name |
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
9 纵向合并 - 文件名转成列值 - 文件个数不定
合并前:
Apple.xlsx Bread.xlsx Pork.xlsx



合并后:

SPL 实现代码:
A |
B |
|
1 |
=directory@p("tmp/*.xlsx") |
/列出目录下的所有文件,此种方式可处理不定数量的文件 |
2 |
=A1.conj((fn=filename@n(~),T(~).derive(fn:Commodity))) |
|
3 |
=file("Amount.xlsx").xlsexport@t(A2) |
10 横向合并 - 文件名转成列名
合并前:
Apple.xlsx Bread.xlsx Pork.xlsx
合并后:

SPL 实现代码:
A |
B |
|
1 |
=directory@p("tmp/*.xlsx") |
/列出目录下的所有文件名 |
2 |
=A1.(filename@n(~)) |
/获得不带扩展名的文件名 |
3 |
=A1.(T(~)) |
/把文件读成序表 |
4 |
=A3(1).new(Name,Amount:${A2(1)},A3(2)(#).Amount:${A2(2)},A3(3)(#).Amount:${A2(3)}) |
/产生新序表的同时,把原序表中的 Amount 字段转成各自的文件名 |
5 |
=file("Amount.xlsx").xlsexport@t(A4) |
11 横向合并 - 一对多 - 复制数据
合并前:
Types.xlsx

Foods.xlsx

合并后:

SPL 实现代码:
A |
B |
|
1 |
=T("Types.xlsx") |
|
2 |
=T("Foods.xlsx") |
|
3 |
=join@f(A1:Type,Type;A2:Food,Type) |
/@f为全连接 |
4 |
=A3.new(Food.Type,Food.Name,Food.UnitPrice,Type.Description) |
|
5 |
=T("FoodsDescription.xlsx",A4) |
12 横向合并 - 一对多 - 后续行置空
合并前:
Types.xlsx
Foods.xlsx
合并后:

SPL 实现代码:
A |
B |
|
1 |
=T("Types.xlsx") |
|
2 |
=T("Foods.xlsx") |
|
3 |
=A1.align(A2:Type,Type) |
/align表示 A1 向 A2 对齐,对齐条件是 A2 的 Type 字段和 A1 的 Type 字段,如果 A2 有重复数据,只对齐第一行 |
4 |
=A2.new(Type,Name,UnitPrice,A3(#).Description) |
|
5 |
=T("FoodsDescription.xlsx",A4) |
13 纵向合并去重 - 整行重复
纵向合并时如遇到整行数据重复,合并时只保留相同记录中的一条,如:
合并前
 和
和
从上图可以看出,Cindy 和 Lily 为整行重复数据,合并后的结果如下:

实现代码:
A |
B |
|
1 |
=file("Customer1.xlsx").xlsimport@t().sort(Name,Times) |
/因为 merge 为归并,所以源数据需排序 |
2 |
=file("Customer2.xlsx").xlsimport@t().sort(Name,Times) |
|
3 |
=[A1,A2].merge@u(Name,Times) |
/merge@u表示并集,以 Name 和 Times 作为判断相等的标准,所以如果以整行作为判断相等的标准,则必须写上所有字段名 |
4 |
=file("CustomerTimes.xlsx").xlsexport@t(A3) |
14 纵向合并去重 - 行头重复 - 保留初次出现的数据
纵向合并多个 Excel 文件时,可能只以行头或者其中某一 / 几个关键列作为判断数据是否重复的标准,如下例所示,仅用 Name 作为判断是否重复的标准:
合并前
和
从上图可以看出,Cindy 和 Lily 为 Name 字段重复的数据,合并后的结果如下:
实现代码:
A |
B |
|
1 |
=file("Customer1.xlsx").xlsimport@t().sort(Name,Times) |
/因为 merge 为归并,所以源数据需排序 |
2 |
=file("Customer2.xlsx").xlsimport@t().sort(Name,Times) |
|
3 |
=[A1,A2].merge@u(Name) |
/merge@u表示并集,以 Name 作为判断相等的标准 |
4 |
=file("CustomerTimes.xlsx").xlsexport@t(A3) |
15 纵向合并去重 - 行头重复 - 保留不为空的数据
Customer3.xlsx Customer4.xlsx


从上图看出,Cindy 和 Lily 重复了,合并时去掉 Quantity 值为空的记录,合并后的结果如下:

实现代码:
A |
|
1 |
=file("Customer3.xlsx").xlsimport@t().select(Quantity!=null) |
2 |
=file("Customer4.xlsx").xlsimport@t().select(Quantity!=null) |
3 |
=A1|A2 |
4 |
=file("CustomerQuantity.xlsx").xlsexport@t(A3) |
16 纵向合并去重 - 行头重复 - 删除所有重复数据
CustomerTotal.xlsx Customer.xlsx


Name 字段作为关键列,关键列相同认为是重复数据,需要从 CustomerTotal.xlsx 中把在 Customer.xlsx 里重复出现的数据都删了, 去重后的结果如下所示:

实现代码如下:
A |
B |
|
1 |
=file("CustomerTotal.xlsx").xlsimport@t().sort(Name) |
/因为 merge 为归并,所以源数据需排序 |
2 |
=file("Customer.xlsx").xlsimport@t().sort(Name) |
|
3 |
=[A1,A2].merge@d(Name) |
/@d表示从第一个序表中删除后续序表中出现的数据 |
4 |
=file("CustomerTotalNew.xlsx").xlsexport@t(A3) |
17 横向合并去重 - 列名重复 - 保留后出现的列数据
合并前:
CustomerFruits.xlsx CustomerMeats.xlsx
 和
和
可以发现,Bread 重复了,合并后希望保留第二个文件中的 Bread 字段,去掉第一个文件中的 Bread,结果如下所示:

实现代码:
A |
|
1 |
=file("CustomerFruits.xlsx").xlsimport@t() |
2 |
=file("CustomerMeats.xlsx").xlsimport@t() |
3 |
=A1.new(Name,Apple,Strawberry,Peach,A2(#).Mutton,A2(#).Pork,A2(#).Bread,A2(#).Duck) |
4 |
=file("CustomerFoods.xlsx").xlsexport@t(A3) |
18 横纵两个方向同时合并 - 保留先出现的数据
合并前:
CustomerFruits1.xlsx CustomerMeats1.xlsx


按照先 CustomerFruits1.xlsx 后 CustomerMeats1.xlsx,重复项保留先出现在 CustomerFruits1.xlsx 中的数据,合并后:

SPL 的实现代码:
A |
B |
|
1 |
=file("CustomerFruits1.xlsx").xlsimport@t() |
|
2 |
=file("CustomerMeats1.xlsx").xlsimport@t() |
|
3 |
=A1.pivot@r(Name;col,val) |
/将原交叉结构的数据转置成列表 |
4 |
=A2.pivot@r(Name;col,val) |
|
5 |
=(A3|A4).group@1(Name,col) |
/分组后取第一条出现的记录 |
6 |
=A5.pivot(Name;col,val) |
/再转置回交叉结构 |
7 |
=file("CustomerFoods1.xlsx").xlsexport@t(A6) |
19 汇总文件 - 相同行列
业务上有时候需要在合并多个 Excel 的同时汇总数据,比如:
Apple.xlsx Bread.xlsx Pork.xlsx
现需要将 Amount 汇总起来,形成一个总金额字段,存到新文件中,结果如下:

SPL 实现代码:
A |
|
1 |
=file("Apple.xlsx").xlsimport@t() |
2 |
=file("Bread.xlsx").xlsimport@t() |
3 |
=file("Pork.xlsx").xlsimport@t() |
4 |
=A1.new(Name,Amount+A2(#).Amount+A3(#).Amount:TotalAmount) |
5 |
=file("TotalAmount.xlsx").xlsexport@t(A4) |
20 汇总文件 - 横纵两个方向同时合并 - 汇总重复项
合并前:
CustomerFruits1.xlsx CustomerMeats1.xlsx
重复项汇总,合并后:

SPL 的实现代码:
A |
B |
|
1 |
=file("CustomerFruits1.xlsx").xlsimport@t() |
|
2 |
=file("CustomerMeats1.xlsx").xlsimport@t() |
|
3 |
=A1.pivot@r(Name;col,val) |
/将原交叉结构的数据转置成列表 |
4 |
=A2.pivot@r(Name;col,val) |
|
5 |
=(A3|A4).groups(Name,col;sum(val):val) |
/分组汇总 |
6 |
=A5.pivot(Name;col,val) |
/再转置回交叉结构 |
7 |
=file("CustomerFoods2.xlsx").xlsexport@t(A6) |
21 汇总文件 - 按单元格位置对位汇总 - 文件个数不定
总公司有收到各分公司发来的资产负债表,其中某分公司的表格如下图所示 (共有 37 行,图中只列出 14 行):

现在需要用各分公司的表格汇总出总公司的资产负债表。
编写 SPL 脚本:
A |
B |
C |
|
1 |
=directory@p("zc*.xlsx") |
/列出目录下文件名匹配格式的所有文件,此种方式可处理不定数量的文件 |
|
2 |
=A1.(file(~).xlsopen()) |
||
3 |
=to(4,37) |
[B,C,E,F] |
=A3.(B3.(~/A3.~)).conj() |
4 |
for C3 |
>v=null |
|
5 |
for A2 |
>v+=number(B5.xlscell(A4,1)) |
|
6 |
>A2(1).xlscell(A4,1;string(v)) |
||
7 |
=file("total.xlsx").xlswrite(A2(1)) |
||
A1 列出文件夹中要汇总的所有以 zc 开头的资产负债表文件名,选项 @p 表示列出文件全路径
A2 打开 A1 中列出的文件为 Excel 对象
A3 指定要汇总的数字单元格的行号范围 4-37
B3 指定要汇总的数字单元格的列号 B,C,E,F
C3 用 A3 行号和 B3 列号拼出所有要汇总的数字单元格的名称
A4 循环 C3 中所有要汇总的单元格
B4 定义汇总值变量 v
B5 循环所有分公司资产负债表
C5 从当前分公司资产负债表中读出当前汇总单元格的值,转成数值后累加到 v
B6 将完成累加后的 v 保存到第 1 个分公司的资产负债表中
A7 将第 1 个分公司的资产负债表保存到总公司资产负债表 total.xlsx
22 汇总文件 - 追加汇总
有每日商品进货发货统计表如下图:

另有商品每日进销存汇总表如下:

现在需要把一日的进货发货数据追加到汇总表,并计算新的库存:前日库存 + 进货 - 发货,汇总后的结果如下所示:

编写 SPL 脚本:
A |
|
1 |
=T("20200803.xlsx").derive(Inventory) |
2 |
=T("total.xlsx") |
3 |
=A1.run(Inventory=A2.select@z1(Goods==A1.Goods).Inventory+Purchase-Delivery) |
4 |
=file("total.xlsx").xlsexport@a(A3) |
A1 读出需追加汇总的当日数据并新增一列 Inventory
A2 读出汇总表数据
A3 循环 A1 中每一行,令 Inventory 的值为汇总表中最后一条当前商品的 Inventory 加上当前的 Purchase 再减去当前的 Delivery。选项 @z1 表示从后向前选择第 1 条满足条件的记录
A4 将 A3 中的结果追加保存到文件 total.xlsx,选项 @a 表示追加数据
23 汇总文件 - 累计汇总
现有本月一些商品的日销售额统计表,每日一个文件,需要在这些文件的当月累计销售额字段中增加累计值
合并前:
20220101.xlsx

20220102.xlsx

20220103.xlsx

其它日期文件略过…
合并后:
20220101.xlsx

20220102.xlsx

20220103.xlsx

其它日期文件略过…
SPL 的实现代码:
A |
B |
|
1 |
2022-01-01 |
2022-01-31 |
2 |
=periods(A1,B1).(string(~,"yyyyMMdd")+".xlsx") |
|
3 |
=A2.(T(~)) |
|
4 |
>A3(1).run(MonthlyCumulativeSales=DailySales) |
|
5 |
for A3.to(2,) |
=A5.run(MonthlyCumulativeSales=DailySales+A3(#A5).select@1(Name==A5.Name). MonthlyCumulativeSales) |
6 |
=A3.run(T(A2(#),~)) |
|
24 汇总文件 - 插入汇总 sheet 页
商场有全年 12 个月的重点客户购买量汇总表,格式如下所示:
Jan.xlsx:

Feb.xlsx:

其它月份的数据这里略过……
现在需要把这些 Excel 文件汇总到一个文件的不同 sheet 中,且以文件名作为 sheet 名,并在首页插入汇总页面,取名为 Total。
汇总后的 Excel 如下所示:

SPL 实现代码:
A |
B |
B |
|
1 |
[Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec] |
||
2 |
=A1.(T(~+".xlsx")) |
||
3 |
=A2.conj().groups(CustomerName;sum(Apple):Apple, sum(Banana):Banana,sum(Peach):Peach,sum(Strawberry):Strawberry) |
/汇总数据 |
|
4 |
=T("Total.xlsx",A3;"Total") |
/将 T3 导出到 Excel 的第一个 sheet 页,命名为 Total |
|
5 |
for A2 |
=file("Total.xlsx").xlsexport@at(A5;A1(#A5)) |
/将原始数据追加到 Excel 后续 Sheet 页并以文件名命名,@a 表示追加 |


英文版