


报表工具怎样使用 Hadoop 的数据
Hadoop生态系统由核心应用HDFS,以及外围应用Hive、HBase、Spark等组成。具有官方JDBC接口的Hive是最容易被报表工具访问的,其他应用只提供了API接口,访问起来就困难多了。大部分报表工具只能在自定义数据集里调用API接口,代码非常繁琐;个别报表封装了API接口,简化了取数的过程,但没法简化计算过程,仍然需要大量硬编码。
更好的办法是用JAVA开源计算类库SPL。SPL将API接口封装为简单易用且语法统一的取数函数,不仅支持HDFS,也支持大量外围应用,既有强大的计算能力,还有易于被报表集成的JDBC接口。
SPL提供了方便易用的取数函数,支持多种Hadoop数据源。比如,HDSF存储了各类结构化文件,从这些文件读取数据:
A |
B |
|
1 |
=hdfs_open(;"hdfs://192.168.0.8:9000") |
|
2 |
=hdfs_file(A1,"/user/Orders.txt":"UTF-8").import@() |
//读取tab分隔的txt |
3 |
=hdfs_file(A1,"/user/Employees.csv":"UTF-8").import@tc() |
//csv,首行为列名 |
4 |
=hdfs_file(A1,"/data.xls":"GBK").xlsimport@t(;"sheet3") |
//xls,从sheet3取数 |
5 |
=hdfs_close(A1) |
|
6 |
return A2 |
//只返回A2 |
除了格式规范的结构化数据,SPL可以处理不规则的文件,以及多层的json\xml。
从HBase取数:
A |
|
1 |
=hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
2 |
=hbase_scan(A1,"Orders") |
3 |
=hbase_close(A1) |
4 |
return A2 |
从Spark取数:
A |
|
1 |
=spark_client("hdfs://192.168.0.8:9000","thrift://192.168.0.8:9083","aa") |
2 |
=spark_query(A1,"select * from tablename") |
3 |
=spark_close(A1) |
4 |
return A2 |
Hive有JDBC和API两种接口,后者性能更高。SPL不仅支持JDBC接口,也封装了API接口,用法如下:
A |
|
1 |
=hive_client("hdfs://192.168.0.8:9000","thrift://192.168.0.8:9083","hive","asus") |
2 |
=hive_query(A1, "select * from table") |
3 |
=hive_close() |
4 |
return A2 |
SPL内置丰富的计算函数,可以用简单直观的语法计算取到的数据,从而避免繁琐的硬编码。比如对订单进行区间查询,其中p_start、p_end是参数:
A |
|
1 |
=hdfs_open(;"hdfs://192.168.0.8:9000") |
2 |
=hdfs_file(A1,"/user/Orders.txt":"UTF-8").import@() |
3 |
=hdfs_close(A1) |
4 |
=A2.select(Amount>p_start && Amount<=p_end) |
SPL的取数过程高度相似,计算语法则完全通用,这里不再分开说明。
SPL提供了JDBC驱动,可以像普通RDB一样被报表工具集成。对于上面的SPL代码,先存为脚本文件,再在报表工具里以调用存储过程的形式调用脚本文件名。以Birt报表为例,可写作:
{call intervalQuery(? , ?)}
再举几例:
A |
B |
|
3 |
… |
|
4 |
=A2.select(Amount>1000 && like(Client,\"*S*\")) |
//模糊查询 |
5 |
=A2.sort(Client,-Amount)" |
//排序 |
6 |
=A2 .id(Client) |
//去重 |
7 |
=A2.groups(year(OrderDate);sum(Amount)) |
//分组汇总 |
8 |
=join(A2:O,SellerId;B2:E,EId) |
/关联 |
SPL还提供了标准SQL语法,可有效降低学习门槛,适合代码短难度低的计算。比如区间查询可以改写为下面的SQL语句:
A |
|
1 |
=hdfs_open(;"hdfs://192.168.0.8:9000") |
2 |
=hdfs_file(A1,"/user/Orders.txt":"UTF-8").import@() |
3 |
=hdfs_close(A1) |
4 |
$select * from {A2} where Amount>? && Amount<=?; p_start, p_end |
更多例子参考《在文件上使用 SQL 查询的示例》
SPL最鲜明的特点是计算能力强大,可简化分步计算、有序计算、分组后计算等逻辑较复杂的计算,很多SQL难以实现的计算,用SPL解决起来就很轻松。比如,找出销售额累计占到一半的前n个大客户,并按销售额从大到小排序:
A |
B |
|
1 |
… |
/取数据 |
2 |
=A1.sort(amount:-1) |
/销售额逆序排序 |
3 |
=A2.cumulate(amount) |
/计算累计序列 |
4 |
=A3.m(-1)/2 |
/最后的累计即总额 |
5 |
=A3.pselect(~>=A4) |
/超过一半的位置 |
6 |
=A2(to(A5)) |
/按位置取值 |
SPL提供了专业的IDE,具备完整的调试功能,允许以表格的形式观察每一步的计算结果,适合开发逻辑较复杂的计算。
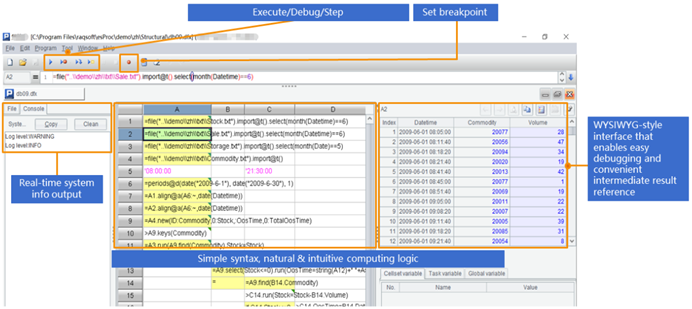
除了Hadoop之外,SPL还支持WebService、Restful、MongoDB、redis、ElasticSearch、SalesForce、Cassandra、Kafka等多种数据源,以及不同数据源/数据库之间的混合计


英文版