


SPL 看 JOIN 运算
现实中绝大多数 JOIN 都是字段相等的等值连接,非等值 JOIN 很少见,而且大多数可以转换成等值 JOIN 处理,我们在这里主要讨论等值 JOIN。
与 SQL 不同,SPL 将 JOIN 运算分成三种情况分别处理,由程序员根据不同的场景来选择使用不同的计算方法。这样做可以体现数据之间的关联特征,并能针对不同的特征采取不同的手段,有效简化语法、提高性能。
外键关联
表 A 的某个字段和表 B 的主键字段关联。A 表称为事实表,B 表称为维表。A 表中与 B 表主键关联的字段称为 A 指向 B 的外键,B 也称为 A 的外键表。A 和 B 是多对一关系,且只有 JOIN 和 LEFT JOIN,FULL JOIN 非常罕见。外键关联是不对称的,事实表和维表的位置不能互换。
我们通过下图中的订单表和雇员表来理解外键关联的定义:
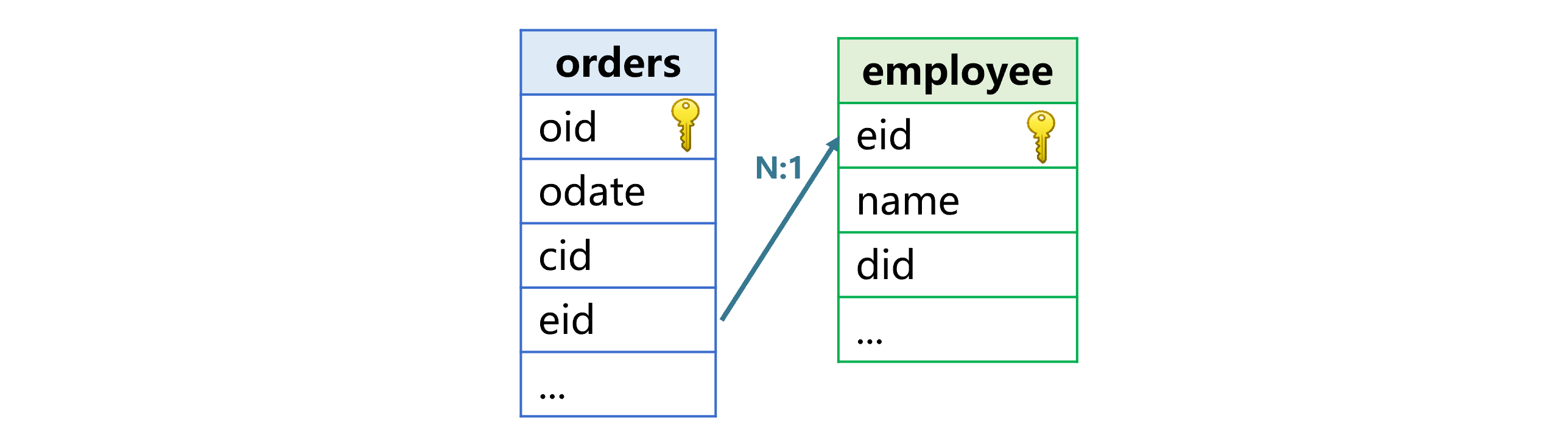
订单表的雇员字段 eid 和雇员表的主键字段关联,订单表是事实表,雇员表是维表。雇员字段是订单表指向雇员表的外键,雇员表是订单表的外键表,订单和雇员是多对一关系。这两个表其他字段的含义是:订单日期 odate、客户号 cid、雇员姓名 name、雇员所在部门号 did。
将两个表做外键关联的目的,是我们需要在计算中既可以使用事实表字段,也可以使用维表字段。比如,按照雇员姓名和订单日期来过滤订单数据,就要用到雇员表的姓名字段(name)和订单表的日期字段(odate)。
SPL 提供了一个自然直观的办法:外键地址化。也就是将外键字段转化为维表对应记录的地址,计算时通过地址直接引用维表记录的字段。比如:订单表中的雇员(eid)字段可以转换为雇员表的一条记录,计算时就可以用 eid.name 来引用这条记录中的姓名字段,其中的点操作符,含义是地址引用。这样,按照雇员姓名和订单日期来过滤订单数据的代码就是下面这个样子:
A |
B |
|
1 |
=file("employee.btx").import@b().keys(eid) |
=file("orders.btx").import@b() |
2 |
>B1.switch(eid,A1:eid) |
|
3 |
=B1.select(eid.name=="Tom" && odate=…) |
|
A1 将 employee 读入内存,并定义主键为 eid。B1 将 orders 读入内存。
A2 将订单表的 eid 字段转换为雇员表对应记录的地址,也就完成了外键地址化。因为雇员表的主键是确定的 eid,所以 A2 可以简化成 orders.switch(eid,A1)。
A3 中可以很自然的通过 eid 来引用雇员表中的字段 name。
被 switch 处理后,这两个表的记录感觉真地连到了一起,这个表的字段取值是另一个表的记录,就能通过这个字段去引用另一个表的字段了。
根据 SPL 对外键关联的定义,维表的关联字段必须是主键,这样,事实表中每一条记录的外键字段关联的维表记录就是唯一的。也就是说,订单表中每一条记录的 eid 字段唯一关联一条员工表中的记录。这也就保证了,对于订单表中的每一条记录,eid.name 都有唯一的取值,可以被明确定义,因此 SPL 才能做到外键地址化。
而 SQL 之所以不能实现外键地址化,是因为 SQL 对 JOIN 的定义是两个表做笛卡尔积再按照一定条件过滤,并没有主键的约定。如果基于 SQL 的规则,就不能认定与事实表中外键关联的维表记录有唯一性,有可能发生与多条记录关联,对于订单表的记录来讲,eid.name 没有明确定义,就无法使用了。
这种对象式的写法在 C、Java 等高级语言中很常见,在这类语言中,数据就是按照对象方式存储的。订单表中的雇员字段值就是一个对象,而不是编号。事实上,在数据库中许多表的主键取值本身并没有业务意义。因为有业务意义的字段值很有可能会随着业务的调整而改变,如果用来做主键和外键,那么业务上微小的变动,也可能会造成众多表的大量数据修改。因此,数据库中很多主键值只是用来区分记录,例如常见的全局唯一标识 UUID,而外键字段值也仅仅是用来找到维表对应记录。如果外键字段直接是对象,就不需要通过编号来标识了。但是 SQL 并不支持这种存储机制,只能借助于编号。
一个事实表通常有多个维表,并且维表还会有很多层。这时,可以更明显的体现出外键属性化在代码书写方面的优势,如下图:
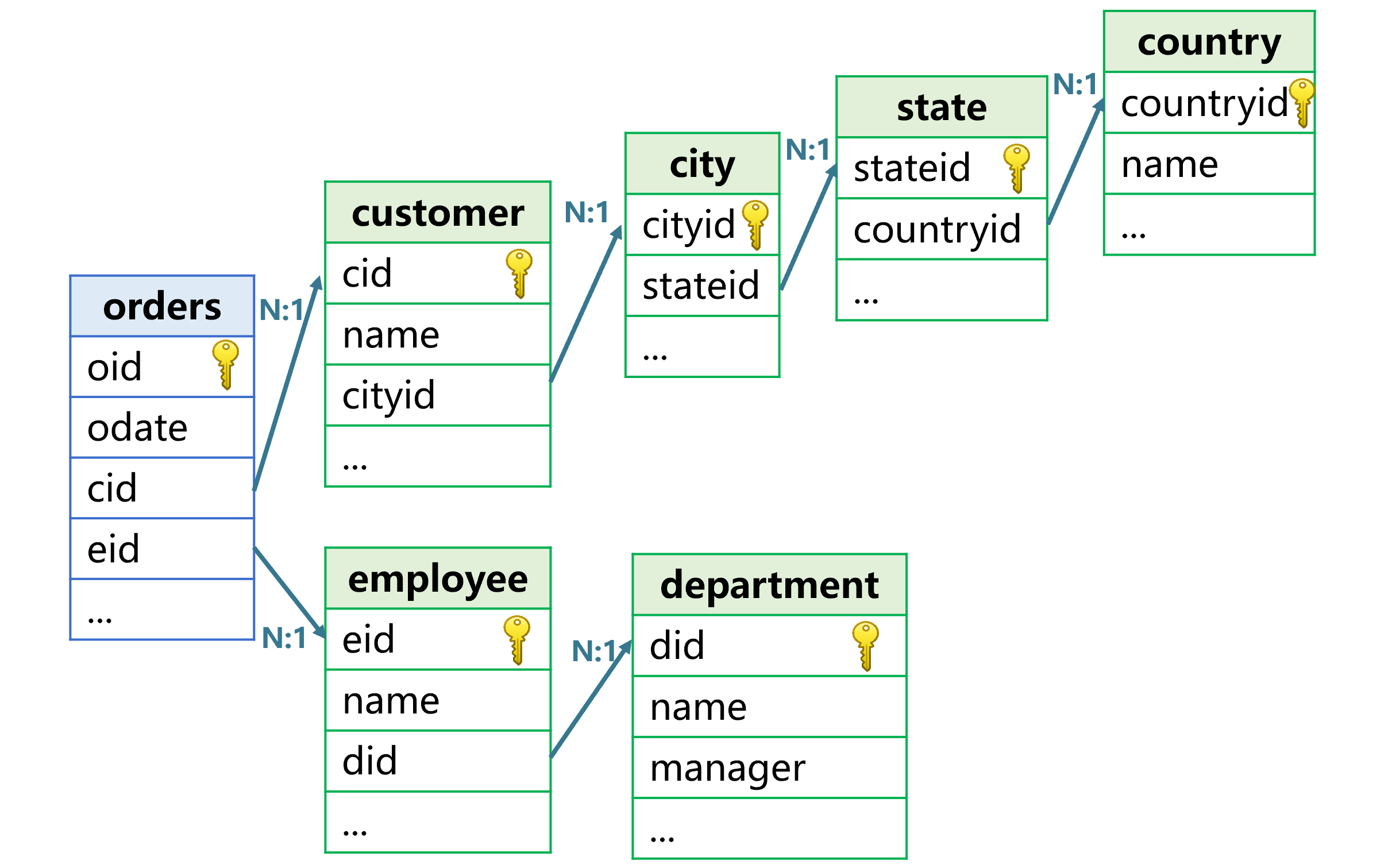
对于这种多个或者多层的外键关联,可以逐个完成外键地址化。订单表的客户号字段 cid 是客户表记录的地址,客户表的 cityid 字段是城市表记录的地址,依次类推。这样,订单对应的客户所在国家名称,可以写作 cid.cityid.stateid.countryid.name,雇员所在部门名称可以写作 eid.did.name。
这样的写法会大大简化代码,我们通过例子来感受一下。假设要对客户所在国家为 "US",雇员所在部门为 "Sales" 的订单,按照客户所在州和城市分组统计订单数量。那么,SPL 代码是这个样子的:
A |
B |
|
1 |
>state.switch(countryid,country) |
>city.switch(stateid,state) |
2 |
>customer.switch(cityid,city) |
|
3 |
>employee.switch(departmentid,department) |
|
4 |
>orders.switch(cid,customer;eid,employee) |
|
5 |
=orders.select(cid.cityid.stateid.countryid.name=="US" && eid.did.name=="Sales") |
|
6 |
=A5.groups(cid.cityid.stateid,cid.cityid;count(1)) |
|
这里省略了读入各表,设置主键,并赋值给对应变量的代码,例如:
>country=file("country.btx").import@b().keys(cid)
A1 使用 switch 函数,将 state 表中的 countryid 字段,转换成 country 表中记录的地址。这样就可以通过 country 引用 country 表中的字段了,也就完成了 country 表的外键地址化。
B1 再将 city 表中的 stateid 字段,转换为 state 表中的一条记录,就实现了 city、state 和 country 三个表多层外键的属性化。
A2 到 B3,依次完成了 customer 等四个表和 employee 等两个表多层外键的地址化。
A4 中,orders 表有两个外键,switch 函数可以同时转换为两个表记录的地址。
从 A1 到 A4,可以看作外键地址化的准备阶段,完成准备后,A5、A6 就可以很自然的写出过滤条件和分组表达式了。
更重要的是,表的主键和外键通常是固定的,完成外键地址化的各个表可以重复使用,计算时就只要写类似 A5 和 A6 的代码就可以了,非常便捷。我们可以在系统启动时把数据表读入后做好外键地址化,这个动作称为预关联。
有些情况下,事实表的某些外键字段值可能会在维表中找不到对应记录。这时候 switch 函数会将外键转换为空,也就找不到原来的外键值了。如果必须保留原外键值,可以用 SPL 的 join 函数,将维表的某些字段临时拼接到事实表。例如,将部门名称、经理字段拼接到雇员表的写法是:
A |
|
1 |
=employee.join(did,department,name:dname,manager:dmanager) |
A1 中新建了一个表,在 employee 表的基础上增加 dname 和 dmanager 字段,分别填入雇员的部门名称和经理编号,did 字段将保持原样。找不到对应的维表记录时,新增加的字段会填成空。
我们还可以利用 join 函数,将维表的记录地址作为一个新字段和事实表拼接起来,这样既能实现外键地址化,也能避免上面说的外键字段值丢失问题。对于雇员表和部门表,用这样的办法查询所在部门为 "Sales" 的雇员的写法是这样的:
A |
|
1 |
=employee.join(did,department,~:did_fk) |
2 |
=A1.select(did_fk.name=="Sales") |
A1 中新建一个表,除了 employee 的字段之外,还增加了一个 did_fk,储存 department 表对应记录的地址。如果找不到对应记录,就为空。相当于将外键字段 did 复制了一份,并完成了外键地址化。
A2 中用 did_fk 来引用部门表的字段 name。
和 switch 函数不同,join 函数不直接转换原表的字段,而是产生一个新的表。所以,在做多层外键地址化时要注意次序,那些既是事实表又是维表的数据表,要先关联自己的维表后得到新的数据表,然后再用来被事实表关联。
switch 函数不支持多个字段做维表主键和事实表外键的情况,也需要用 join 函数实现。假设专业号、班级号两个字段是学生表指向班级表的外键,如下图:
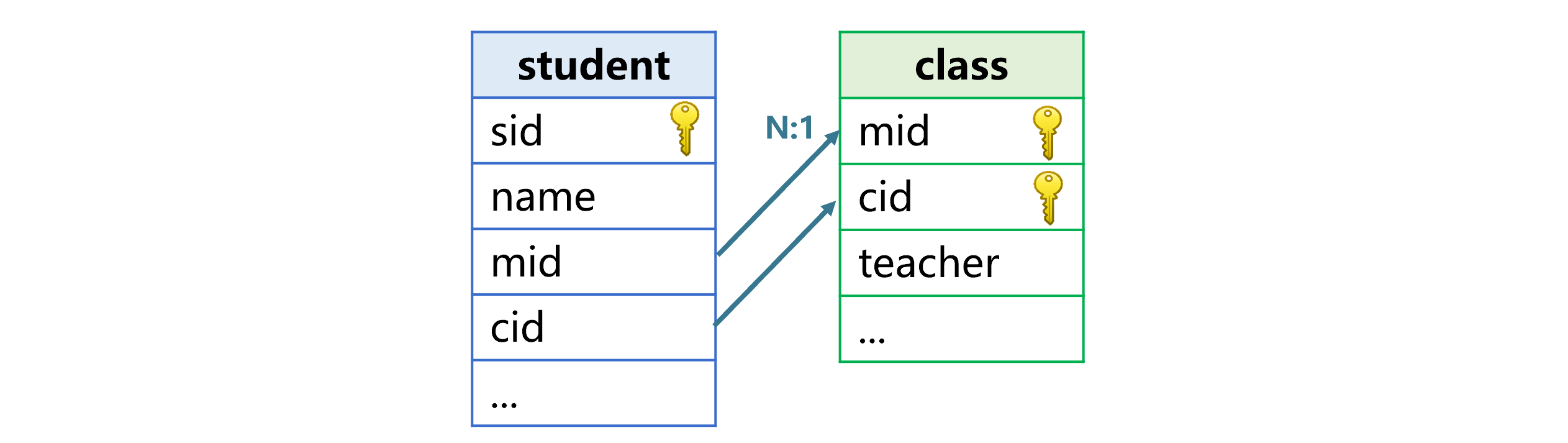
用 join 函数,将班主任字段拼接到学生表中的代码写法是:
A |
|
1 |
>class.keys(mid,cid) |
2 |
=student.join(mid:cid,class,teacher) |
A1 给 class 表指定联合主键。A2 中新建表,在学生表基础上,增加 teacher 字段,填入班主任。join 的关联字段有多个,用冒号分开。
同维表关联
表 A 的主键与表 B 的主键关联称为同维关联,A 和 B 互称为同维表。同维表是一对一的关系,JOIN、LEFT JOIN 和 FULL JOIN 的情况都会有,不过在大多数数据结构设计方案中,FULL JOIN 也相对少见。同维表之间是对称的,两个表的地位相同。同维表还构成等价关系,A 和 B 是同维表,B 和 C 是同维表,则 A 和 C 也是同维表。
雇员表和经理表是典型的同维表关系,如下图:
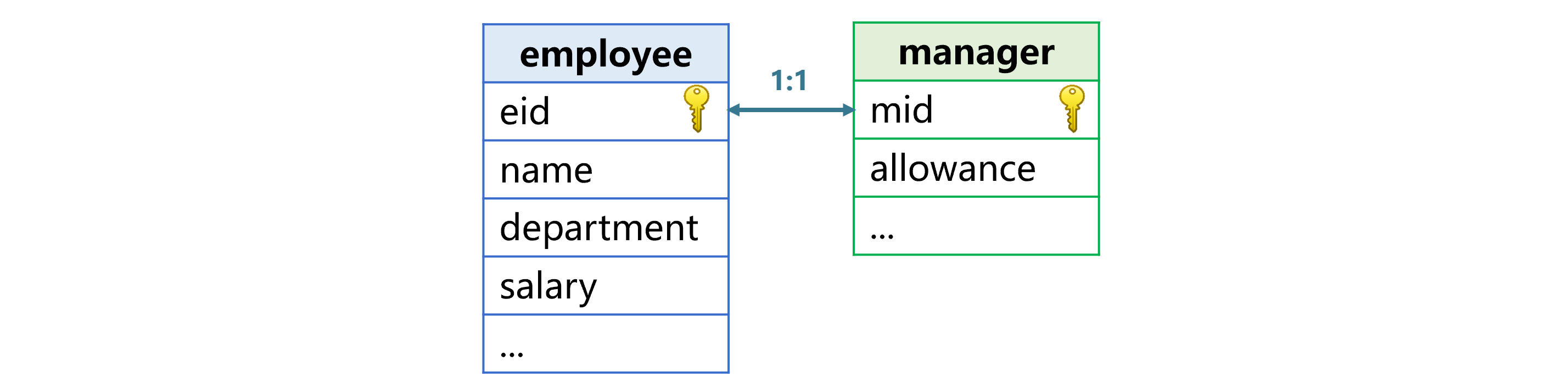
雇员表的主键 eid 和经理表的主键 mid 关联,有部分雇员是经理,eid 和 mid 都是员工编号。因为经理比普通员工多一些属性,比如岗位津贴(allowance),所以要另用一个经理表来保存。为了计算时能同时利用这两个表的字段,我们要用两个同维表生成一个新表。
两个数据表通过某个字段(或表达式)相等的关系生成一个两字段的新数据表,新表的两个字段分别是这两个数据表对应记录的地址。基于这个新数据表可以同时引用两个原来数据表的字段进行运算,这样就完成了两表的关联。用于判定关联的字段(表达式)称为关联键,关联键值相等记录互称为关联记录。SPL 把这种关联运算称为连接。这个定义在本质上和 SQL 中的等值 JOIN 是一回事,只是 SQL 不能返回由记录地址作为字段取值的记录,只能把关联记录的字段直接抄到结果表上。
SPL 用 join 函数来实现连接。比如要查询每个员工(包括经理)的编号、姓名和总收入(工资加津贴),代码是这样的:
A |
B |
|
1 |
=file("employee.btx").import@b().keys(eid) |
=file("manager.btx").import@b().keys(mid) |
2 |
=join@1(A1:e,eid;B1:m,mid) |
|
3 |
=A2.new(e.eid:eid,e.name:name,e.salary+m.allowance:income) |
|
A2 中的 join 函数返回一个新表,新表的两个字段分别为 e 和 m。它会将 A1 中的雇员记录和 B1 中的经理记录连接起来,也就是把 eid 和 mid 相等的记录分别填入 e 和 m 字段,作为新表的一条记录。字段 e 和 m 的值也是记录,有点像外键被 switch 函数转换后的结果。
因为两个表已经设置了主键,A2 可以简化为:=join@1(A1:e;A2:m)。
这里的 join 和前面外键关联用到的 join 是不同的两个函数。后面我们会介绍两个 join 函数的异同点。
A3 利用 A2 的结果,生成包含 eid、name 和 income 三个字段的新表。由于 e 和 m 都是记录,所以可以用 e 来引用雇员的编号、姓名字段填入新表的 eid 和 name 字段,再用雇员的工资加上 m 引用经理的津贴字段得到新表的 income 字段。用新表的两个字段来引用各自表的字段,和外键地址化一样,很自然、容易理解。
同维关联是一种一比一的关联,也就是某个关联表中的一条记录只会和另一个关联表中的一条记录关联,不会出现多条,因为主键是唯一的。
这个例子中,雇员表包含了经理,但并不是每个雇员都是经理。也就是说,很多雇员在经理表中是找不到对应记录的。这时候新表的 m 字段应该填上空,这样,雇员的总收入就等于工资。
这时 join@1 将会以左边的关联表(join 函数的第一个参数)为基准,其他关联表中如果有与左边第一个表关联键相同的记录,则关联上,如果没有,则会填成空。这种以左边第一个表为准的连接方式称为左连接。@1 是数字 1 不是字母 l,它表示以第 1 个为准。由于同维表是通过主键关联的,结果序表的关联键值和左边关联表一致,其长度也和左边关联表相同。超过两个表左关联时,同样以左边第一个表为准。
SPL 没有提供右连接,因为只要把参数换个位置就可以了。
实际上,同维关联也适用于临时产生的表,只要满足关联字段是主键的条件就可以。比如下图中的合同表、回款表和发票表:

现在想统计每一天的合同额、回款额以及发票额。我们可以把三个表分别按照日期分组汇总金额,并将分组结果看作三个表。其中的分组字段日期具有唯一性,天然能构成这些表的主键。这三个表主键相同,符合同维表的定义。三个表按照主键(日期)关联,就是同维表关联。因此,这个问题同样可以用 join 函数来解决,代码是这个样子:
A |
B |
|
1 |
=file("contract.btx").import@b() |
=A1.groups(cdate;sum(amount):amount) |
2 |
=file("payment.btx").import@b() |
=A2.groups(pdate;sum(amount):amount) |
3 |
=file("invice.btx").import@b() |
=A3.groups(idate;sum(amount):amount) |
4 |
=join@f(B1:c;B2:p;B3:i) |
|
5 |
=A4.new(ifn(c.cdate,p.pdate,i.idate):adate,c.amount:camount,p.amount:pamount,i.amount:iamount) |
|
A1 到 B3,依次将三个表按照日期汇总金额,汇总结果 B1、B2、B3 是以日期为主键的表。
A4 中,将 B1、B2、B3 做连接,生成一个新表,其三个字段 c、p、i,分别存储 B1、B2、B3 的记录。
A5:利用 A4 引用三个表的字段,生成新表,得到想要的结果。
从需求上看,合同额、回款额和发票额都为空的日期不会出现在结果中了,但只要有一个不为空就应该放到结果中。这里采用的 join@f 会兼顾所有连接的表,关联键值在任何一个表中存在,就会在结果表中生成一条记录,并将存在关联键值的表的记录填入相应的字段实现关联,不存在的相应字段值填为空。最后结果表中还有的关联键值集合,将是多个参与关联的序表的关联键集合的并集。这种多方兼顾的连接方式称为全连接。
因为全连接的结果中,c、p、i 都有可能为空,所以 A5 中要用 ifn 函数返回三个记录中不为空的第一个的日期字段,作为最终结果的日期字段。
主子表关联
表 A 的主键与表 B 的部分主键关联,A 称为主表,B 称为子表。主子表是一对多的关系,只有 JOIN 和 LEFT JOIN,不会有 FULL JOIN。主子表也是不对称的,有明确的方向。
主子表的典型示例是订单和订单明细,如下图:
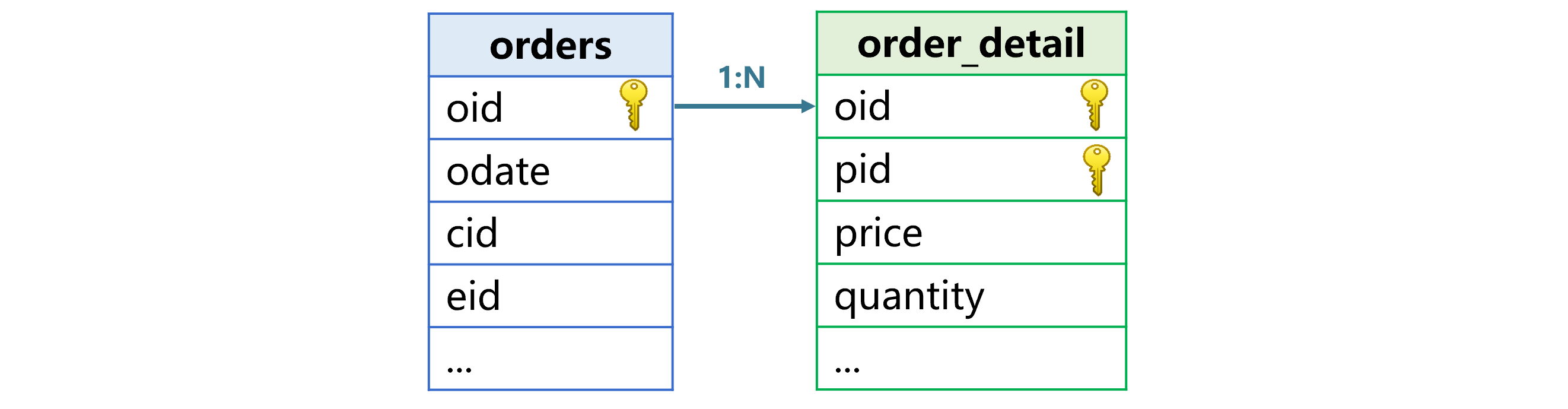
明细表的主键是两个字段订单号 oid 和产品号 pid。订单表的主键 oid 与明细表的部分主键 oid 关联。订单表是主表,明细表是子表,两者是一对多关系。
主子关联时 SPL 也使用连接(join 函数)来处理。比如我们想计算每个客户的订单总金额,代码是这样的:
A |
B |
|
1 |
=file("orders.btx").import@b() |
=file("order_detail.btx").import@b() |
2 |
=join(A1:o,oid;B1:od,oid) |
|
3 |
=A2.groups(o.cid:cid;sum(od.price*od.quantity)) |
|
A3 中使用 join 函数,连接订单和明细,关联字段是订单编号。
A2 中的 join 将 A1 中的订单记录和 B1 中的明细记录连接起来,也就是把 oid 相等的记录分别填入 o 和 od 字段,作为新表的一条记录。
与同维表关联不同的是,oid 只是明细表的部分主键,明细中可能会有 oid 相同的多条记录。这时候 join 函数的结果中订单记录会重复出现,每一条明细记录都会关联一条订单记录,而每一条订单记录则会关联多条明细记录,最后的结果的记录数和明细表相同。
这里用不带任何选项的 join 函数,会找出所有表的关联键都存在且相等的记录来关联,如果有一个表的关联键值在其他任一表中不存在,则这个表的相应记录也会被舍弃。这种连接方式称为内连接。
主子表关联,也可以先将子表按照部分主键(关联键)做分组汇总,再与主表连接。子表做分组汇总之后,就形成了以分组字段(关联键)为主键的表,和主表就是一对一的同维关联了。上面的例子可以写成这样:
A |
B |
|
1 |
=file("orders.btx").import@b() |
=file("order_detail.btx").import@b() |
2 |
=B1.groups(oid;sum(price*quantity):amount) |
|
3 |
=join(A1:o,oid;A2:od,oid) |
=A3.groups(o.cid:cid;sum(od.amount)) |
A2 按照 oid 对明细数据做分组汇总,求每个 oid 的金额 amount。分组结果表的主键是 oid,和订单是同维表。
A3 中对同维表 A1 和 A2 左连接,B3 中对连接的结果再按照客户号做分组汇总。
理论上,外键关联时,我们也可以把事实表以外键为分组键做 groups,形成可以和维表进行同维关联的表,但通常不会这么做。因为一个事实表经常会有多个外键,按某个外键做了 groups,其它外键就没法处理了。而子表在绝大多数情况下只会有一个主表,所以针对关联键去做 groups 再与主表做同维关联是没有问题的。
当然,外键关联时也可以像主子关联时直接用 join 函数来执行连接运算,把维表和事实表记录拼起来,一条维表记录可能关联多条事实表记录。其实,外键关联用到的 join 函数就是在这么做,只不过同时把关联后引用维表的字段动作一起做了,因为这种组合动作更为常见,结果序表长度也是和事实表(主子关联概念中的子表)长度相同,所以那个函数也被命名为 join。
小结
在 SQL 的概念体系中不区分外键表、同维表和主子表,多对一和一对多从 SQL 的观点看来只是关联方向不同,本质上是一回事。确实,订单也可以理解成订单明细的外键表。但是,SPL 把它们区分开,在简化语法和性能优化时就能使用不同的手段。通过上面的介绍,我们发现这样做确实可以有效简化语法。后续我们还会介绍,这样做也能有效提高性能。
外键表、同维表和主子表这三种 JOIN 涵盖了绝大多数等值 JOIN 的情况,可以说几乎全部有业务意义的等值 JOIN 都属于这三类,把等值 JOIN 限定在这三种情况之中,几乎不会减少其适应范围。
仔细考察这三种 JOIN,我们发现所有关联都涉及主键,没有多对多的情况,是不是可以不考虑这种情况?
如果两个表 JOIN 时的关联字段没有涉及到任何主键,那就会发生多对多的情况,而这种情况几乎一定还会有一个规模更大的表,把这两个表作为维表关联起来。比如学生表和科目表在 JOIN 时,会有个成绩表把学生表和科目表作为维表,单纯只有学生表和科目表的 JOIN 没有业务意义。
所以说,结构化数据运算中几乎不存在有业务意义的多对多连接,多对多连接只存在于理论分析或数学运算中。结构化数据运算场景里,基本上不会碰到与主键无关的关联,可以不必关注。SPL 提供了 xjoin,可以解决数学运算中的多对多 JOIN(比如计算矩阵乘法),可以参考其他文章的介绍。
SQL 采用笛卡尔积再过滤这种 JOIN 定义,确实非常简单,而简单的内涵将得到更大的外延,可以把多对多等值 JOIN 甚至非等值 JOIN 等都包括进来。但是,过于简单的内涵无法充分体现出最常见等值 JOIN 的运算特征。这会导致编写代码和实现运算时就不能利用这些特征,在运算较为复杂时(涉及关联表较多以及有嵌套的情况),无论是书写还是优化都非常困难。而充分利用这些特征后,我们就能创造出更简单的书写形式并获得更高效的运算性能。
与其为了把罕见情况也被包括进来而把运算定义为更通用的形式,还不如把这些情况定义成另一种运算更为合理。

