


报表工具怎样使用 MongoDB 的数据
MongoDB 是常见的 NoSQL 数据库,有些报表工具不提供 MongoDB 的接口,只能在自定义数据集里硬写代码去访问。还有些报表工具如 Birt 和 JasperReport,内置了访问接口,能用官方提供的 mongo Shell 去计算,不过代码会比较繁琐,功能也不强,处理复杂的报表难度较大。
更好的办法是使用集算器 SPL,一种 JAVA 生态下的开源计算类库。SPL 具有强大的多层数据计算能力,非常适合 MongoDB 中的 bson 类数据,内置了用法简单的 MongoDB 访问函数,提供了 JDBC/ODBC 驱动,可以被报表工具方便地集成。
SPL 内置了MongoDB 取数函数。比如,通过 mongo Shell 从某 collection 取数:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"keyValue.find()").fetch() |
3 |
=mongo_close(A1) |
SPL 当然不能止步于使用 mongo Shell,那样和让报表工具直接 MongoDB 并没有区别。SPL 更大的优势在于能够简化基于 MongoDB 的计算。
SPL 内置了丰富的计算函数,比 Mongo Shell 要直观简单,可以避免编写繁琐的 MongoDB 查询语法。比如,下面代码将 value 字段按逗号拆成多个数字,过滤出第 N 个数字符合某区间的所有记录,pN、pStart、pEnd 是查询参数:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell@x(A1,"keyValue.find()").fetch() |
3 |
=A2.select((valueN=value.split@pc()(pN), valueN>=pStart && valueN |
SPL 提供了JDBC/ODBC 驱动,可以像数据库一样被报表工具集成。比如,先将上面的 SPL 代码存为脚本文件 splitQuery.splx,再在报表工具里调用脚本文件,类似通过 JDBC 调用 RDB 的存储过程,形如:
{call splitQuery(?,?,?) }
再举几例:
A |
B |
|
2 |
… |
|
3 |
=A2.select(Amount>1000 || like@c(Client,"*s*")) |
//模糊查询 |
4 |
=A2.groups(year(OrderDate),Client;sum(Amount)) |
//分组汇总 |
5 |
=A2.sort(Dept,-Salary) |
//排序 |
6 |
=A2.id(State) |
//去重 |
SPL 提供了简单易用的关联函数,可以弥补 MongoDB 老版本无法关联,新版本虽有 $lookup 函数但功能不强语法繁琐的问题。
比如,对两个 collection 按照逻辑外键 key1,key2 进行左关联:
A |
B |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
|
2 |
=mongo_shell@x(A1,"c1.find()").fetch() |
=mongo_shell@x(A1,"c2.find()").fethc() |
3 |
=A2.join(key1:key2,B2:key1:key2,output) |
|
如果用mongo Shell 计算,代码就复杂多了:
db.c1.aggregate([
{"\lookup":{
"from":"c2",
"localField":"key1",
"foreignField":"key1",
"as":"collection2_doc"
}},
{"\$unwind":"\$collection2_doc"},
{"\$redact":{
"\$cond":[
{"\$eq":["\$key2","\$collection2_doc.key2"]},
"\$\$keep",
"\$\$prune"
]
}},
{"\$project":{
"key1":1,
"key2":1,
"income":"\$income",
"output":"\$collection2_doc.output"
}}
]}.pretty()
SPL 提供了多层数据类型,适合多层数据的计算。MongoDB 虽然天生支持多层数据,但缺乏计算能力。比如,对于下面的 collection,统计每条记录中 income,output 的数量之和:
_id |
Income |
Output |
1 |
{"cpu":1000, "mem":500, "mouse":"100"} |
{"cpu":1000, "mem":600 ,"mouse":"120"} |
2 |
{"cpu":2000,"mem":1000, "mouse":"50","mainboard":500 } |
{"cpu":1500, "mem":300} |
用mongo shell 计算,代码冗长难懂:
var fields = [ "income", "output"];
db.computer.aggregate([
{
$project:{
"values":{
$filter:{
input:{
"\$objectToArray":"$$ROOT"
},
cond:{
$in:[
"$$this.k",
fields
]
}
}
}
}
},
{
\$unwind:"$values"
},
{
$project:{
key:"$values.k",
values:{
"$sum":{
"$let":{
"vars":{
"item":{
"\$objectToArray":"$values.v"
}
},
"in":"$$item.v"
}
}
}
}
},
{$sort: {"_id":-1}},
{ "$group": {
"_id": "$_id",
'income':{"\$first": "$values"},
"output":{"\$last": "$values"}
}},
]);
SPL 代码则简短易懂:
A |
|
2 |
… |
3 |
=A2.new(_id:ID,income.array().sum():INCOME,output.array().sum():OUTPUT) |
SPL 具有很强的语法表达能力,擅长分步计算、行间计算、分组后计算等逻辑较复杂的计算,很多 SQL 和存储过程难以实现的计算,用 SPL 可以轻松解决。比如这个行间计算,求某支股票最长的连续上涨天数,SPL 只需一行:
A |
|
2 |
… |
3 |
=a=0,A2.max(a=if(price>price[-1],a+1,0)) |
SPL 提供了专业的 IDE,具有完整的调试功能,可以用表格的形式观察每一步的中间计算结果,特别适合开逻辑复杂的多步骤计算:
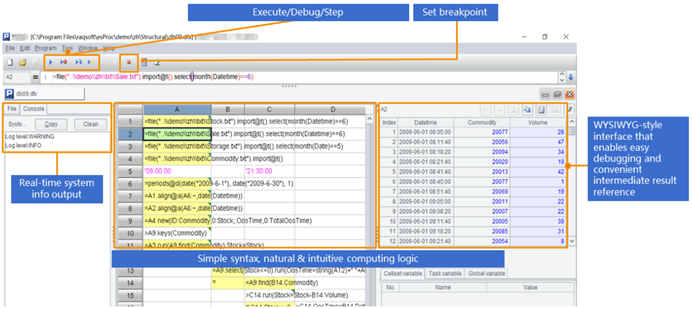
除了 MongoDB 之外,SPL 还支持 CSV/XLS/WebService XML/Restful Json/Hadoop、redis、ElasticSearch、SalesForce、Cassandra 等多种 NoSQL,以及不同数据源 / 数据库之间的混合计算。


英文版