


维表很多时如何提高多维分析的性能?
多维分析应用中,事实表会有很多维表,比如,订单表的维表如下图:
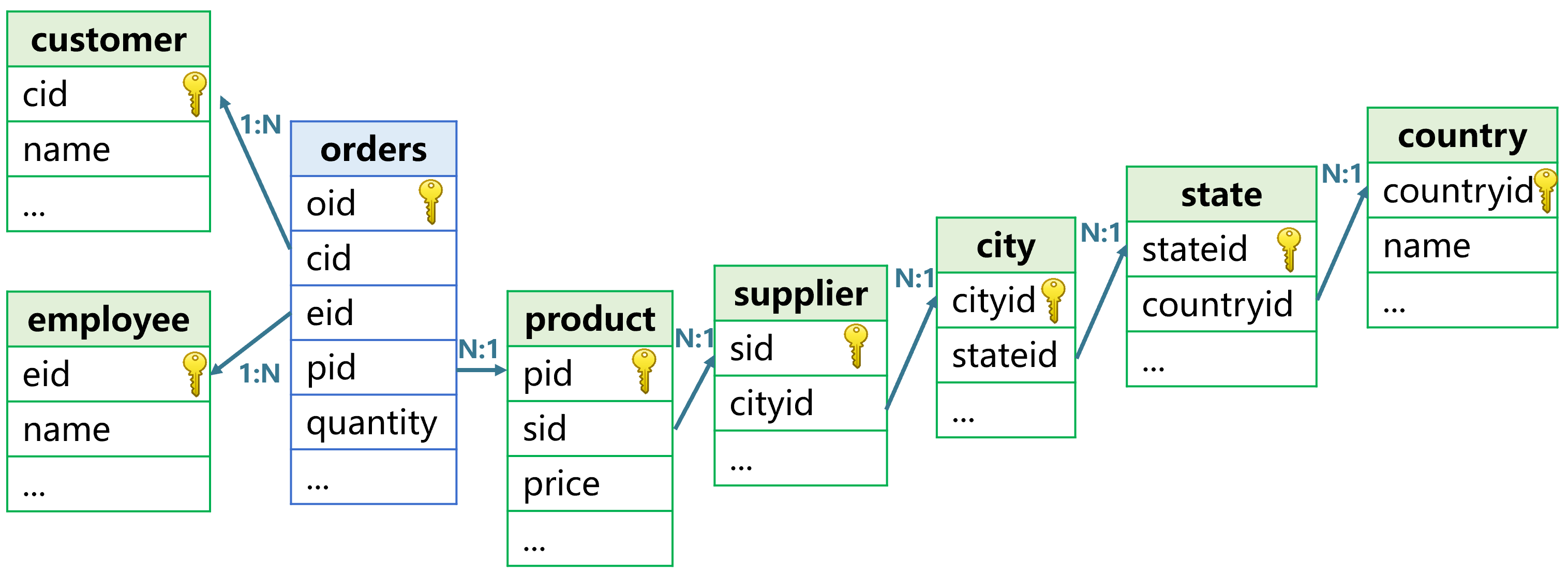
这些维表和事实表的关联运算就是 SQL 中的 JOIN,数据库技术一般采用 HASH JOIN 算法实现。这个算法每次只能解析一个 JOIN,有 N 个 JOIN 要执行 N 遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂,数据也会被遍历多次,计算性能会严重下降。
而且,在维表个数和层数较多时,数据库的优化器常常不能找出最合适的解析次序,而不同的次序会导致不同的数据产生和复制运算量,如果每次关联都有大表参与,这些额外的计算量就会很大,数据库的计算性能会急剧下降。HASH JOIN 算法也不容易并行,难以充分利用并行计算的性能优势。
维表一般比较小,我们可以事先在系统启动时就将其装入内存并建好索引,维表之间的关联也可以事先建立好。然后,只要在遍历事实表的过程中与内存中的维表进行关联,可以少计算一次 HASH 值,而且也不会发生找不到合适解析次序的问题。另外,维表和事实表区分明确,只要将事实表分段就很容易并行。
用开源集算器 SPL 实现这种算法的代码:
l 系统初始化代码如下:
A1=file("customer.btx").import@b().keys@i(cid)
// 读入客户维表并建立索引
A2=file("product.btx").import@b().keys@i(pid).switch(sid,file("supplier.btx").import@b().keys(sid))
// 产品维表与供应商维表预关联
>env(customer,A1),env(product,A2)
l 多维分析计算代码:
A1=file("orders.ctx").open().cursor@m(pid,cid,quantity).switch(pid,product;cid,customer)
// 用索引查找并关联维表记录,并行计算
A2=A1.select(pid.sid.name=="raqsoft.com").groups(cid.city;sum(pid.price*quantity))
// 预关联好的事实表和维表,先按照供应商名称切片,再按照客户所在城市分组汇总
如果事实表也不大,甚至还可以在系统启动时也装入内存,与维表之间的关联也事先建好,在计算时直接引用维表记录中的字段,不必再做任何 HASH JOIN,性能提高会更明显。
l 系统初始化代码:
A1=file("customer.btx").import@b().keys@i(cid)
// 客户维表建立主键(带索引)
A2=file("product.btx").import@b().keys@i(pid).switch(sid,file("supplier.btx").import@b().keys(sid))
// 产品维表与供应商维表预关联
A3=file("orders.btx").import@b().switch(cid,A1;pid,A2)
// 订单事实表与客户维表、产品维表(多层)预关联
>env(orders,A3) // 预关联好的事实表和维表,存入全局变量,供后续计算使用
l 多维分析计算代码:
orders.select(pid.sid.name=="raqsoft.com").groups(cid.city;sum(pid.price*quantity))
// 预关联好的事实表和维表,先按照供应商名称切片,再按照客户所在城市分组汇总
事实表很大时,还可以预先做序号化处理:一次性将事实表中的维度字段转换为对应内存维表记录的序号。计算时,将事实表数据分批读入内存,用维度字段值(也就是维表序号),直接取内存维表对应位置的记录,性能要比索引查找快很多,和内存预关联性能几乎是一样的。
l 序号化转换代码:
A1=file("orders-original.ctx") // 原数据表
A2=A1.reset@n(file("orders.ctx")) // 复制结构到新数据表
A3=A1.open().cursor().run(pid=file("product.btx").import@b().keys@i(pid).pfind(pid),cid= file("customer.btx").import@b().keys@i(pid).pfind(cid))
> file("orders.ctx").append(A3) // 序号转换后,存入新数据表
l 系统初始化代码:
A1=file("product.btx").import@b().switch(sid,file("supplier.btx").import@b().keys(sid))
// 产品维表与供应商维表预关联
>env(customer,file("customer.btx").import@b()),env(product,A1)
// 存入全局变量,不必生成客户、产品维表的索引,可以节省内存
l 多维分析计算代码:
A1=file("orders.ctx").open().cursor(pid,cid,quantity).switch(pid,product:#;cid,customer:#)
// 用序号定位维表记录
A2=A1.select(pid.sid.name=="raqsoft.com").groups(cid.city;sum(pid.price*quantity))
// 多维分析计算的代码和内存预关联时的写法一致
关系数据库没有对象指针这个概念,并且基于笛卡尔积定义的 JOIN 运算也无法假定外键指向记录的唯一性,没办法实施上述算法。有些数据库能在工程层面做类似上述算法的优化,也能一定程度地改善多维表一次解析和并行能力。不过,这种优化在只有两个表 JOIN 时问题不大,在有很多表及各种 JOIN 混在一起时,数据库就很难优化了。所以我们经常会发现当维表增加到四、五个后,数据库多维分析计算性能就会急剧下降。上述分析还表明,维表很多时,采用 SQL 模型的内存数据库做多维分析计算也很难快起来。要改变对 JOIN 运算的看法并使用不同的计算方案才能获得高性能的多维分析效果。


英文版