


SQL 提速:二值标签
【摘要】
从原理上分析 SQL 语句慢的原因,用代码示例给出提速办法。点击了解SQL 提速:二值标签
问题描述
我们把用来实现某种标记的“是否”型数据称为二值标签。在二值标签总数不太多,只有几个到几十个时,可以用数据表的布尔型字段来存储。
例如,表 T 包含 id 字段、flag1、flag2、…、flagN 和其他字段,其中 flagi 是“是否”型标签,存成布尔类型。针对二值标签的统计 SQL 大体是如下形式:
select … from T where flag2 and flag18 and flag25 and …
数据库过滤出第 2 个二值标签(简称标签 2)、标签 18 和标签 25 都为“是”,且满足其他条件的数据再做统计。
在实际应用中,二值标签的总数会达到几百个甚至几千个,而且还在动态增加中。数据库不支持几千个列的表,无法用一个表存储这么多二值标签,也很难动态增加字段,所以上述方案就不可行了。
首先想到的解决办法,是将几千个字段分成多个表存储,比如每个表存 100 个字段,20 个表就可以存储两千个。计算时,将需要的表用主键 id 关联起来。SQL 大体如下:
select … from T1 left join T2 on T1.id = T10.id left join T15 on T1.id=T15.id
where T1.flag2 and T10.flag913 and T15.flag1462 and …
这些表参与计算的总行数通常是很大的,需要外存。几个大表做外存连接运算的性能会很差。而且,数据库一般是行式存储,即使只有一个字段参与计算,也要把对应数据表的全部上百个字段都遍历到,非常耗时。
为避免大表 JOIN,也可以用一个字段、多条记录来存储二值标签。例如,表 T 包含 id(编号)、flag(标签号)和其他字段。id 和 flag 构成联合主键,每个 id 有最多几十个 flag。二值标签的总数有几千个,实际计算用到的一般都只有几个。
这样的存储结构可以更方便地应对标签的增加,上述计算 SQL 要改写:
select … from T
where (flag=2 or flag=18 or flag=25) and …
group by id
having count(flag)=3
数据库过滤出 flag 为 2 或 18 或 25 且满足其他条件的数据,按照 id 分组后,过滤出包含 3 条记录的组。一般来说,T 表按 id 分组结果集会很大,而大分组需要外存缓存,所以数据库计算的性能会比较差。而且,同一个 id 的其他字段值一般都是相同的,由于 flag 的原因出现了冗余,导致数据量增加一个数量级,也会使性能出现明显下降。
还可以将 id 和其他字段另存一个数据表 T1,T 表只保留 id 和 flag 字段以避免冗余,两表通过 id 关联后再计算。这样也能获得更好的通用性,SQL 要改写成:
select id,… from T t left join T1 t1 on t.id=t1.id
where t.flag in (2,18,25) and …
group by t.id
having count(t.flag)=3
)
这种方案仍解决不了大分组的问题,还要对两个大表做关联,性能仍然很差。
提速方案
一、按位存储、计算
为了提高性能,需要预先处理原数据,将二值标签按位存储。一个小整数是 16 位,每一位都可以存储一个二值标签,1 代表标签值为“是”,0 代表值为“否”。也就是说一个小整数可以存储 16 个二值标签,100 个就可以存储 1600 个二值标签。我们可以采用列式存储几百个小整型字段,包含的字段为 id,f1,f2,…,fn,…。其中,小整型字段 fi 包含 16 个二值标签的值,对应标签号是 (i-1)*16+1 到 i*16。
数据预处理完成后,就可以用按位计算来实现二值标签分析。例如:计算标签 2、18 和 25 都为“是”的情况,标签 2 在 f1 中对应第 2 位,需要将 f1 和小整数 2 做“按位与”,如果结果也是 2 就满足条件。这是因为小整数 2 写成二进制数是 10,只要 f1 的第 2 位是 1,按位与的结果就仍然是 2。
标签 18 和 25 大于 16 小于 32,所以都在第二个小整型字段 f2 中,标签 18 对应 f2 的第 2 位,标签 25 对应第 9 位。我们要将 f2 和小整数 258(二进制 100000010)做“按位与”,如果结果也是 258 就满足条件。最后,将两次按位与的结果做逻辑与计算,结果为真就表示满足二值标签条件。
这样做,每个 id 只有一行数据,不会出现冗余,也不会出现大分组,只要对数据遍历一遍即可,可以有效提高性能。按位存储的性能优势还体现在下面两个方面:
1、由于参加计算的二值标签很少,所以只需要读取几百个列中的几个,可以充分发挥列存的优势,大幅度降低外存数据的读取量。
2、标签总数有几千个,但是每个 id 对应的标签只有几个到几十个。所以这几百个小整型字段总体上是比较稀疏的,可以做到较高的列存压缩比,在进一步降低外存数据读取量的同时,CPU 解压时间的增加值可以忽略不计。
二、数据更新
在二值标签的场景中,数据的更新一般是标签值的改变。列存压缩的存储方式可以提高性能,但是压缩之后的数据无法直接修改。更新时只能重新生成数据,虽然耗时比较长,但可以保证标签计算的高性能。
如果更新的数据量小且不频繁,可以将改动的数据写到单独的数据区(补区)。补区数据和正常数据都按照主键(id)有序,在读取数据时归并计算。虽然补区对性能有影响,但是可以解决经常生成全量数据的耗时问题。
经过多次修改后,补区会越来越大,对性能的影响也会更大,我们要定期将补区数据混入正常存储区,重写部分数据(从补区最小的主键 id 开始,之前的数据不用改变),同时清理补区。
代码示例
一、数据预处理,转换为按位存储。
假设原数据保存在 T-original.ctx 中,包括 id(编号)、flag(标签号)和其他字段。id 和 flag 构成联合主键。实际应用中,原数据可能要从数据库中取得,需要将代码修改为连接数据库取数。
A |
B |
|
1 |
="#id,"/to(500).("f"/~).concat@c() |
="id,"/to(500).("f"/~).concat@c() |
2 |
=to(16).(int(bits(pad@r("1","0",~)))) |
=A2.m(16,1:15) |
3 |
=file("T-original.ctx").open() |
=A3.cursor().sortx(id) |
4 |
=file("T.ctx").create@y(${A1}) |
=create(${B1}) |
5 |
for B3;id |
=B4.reset() |
6 |
=B5.record(A5.id|to(500).(0)) |
|
7 |
=A5.new(int(ceil(~.flag/16)):position,B2(~.flag%16+1):value) |
|
8 |
=B7.group(position;int(or(~.(value))):value) |
|
9 |
=B8.(B4(1).field(~.position+1,~.value)) |
|
10 |
=A4.append(B4.cursor()) |
|
11 |
>A3.close(),A4.close() |
A1、B1:根据小整数字段的个数,动态生成新组表的结构和中间结果序表的结构:
#id,f1,f2,… ,f500
id,f1,f2,…,f500
小整数字段是 500 个,最多可以存储 8000 个标签。
这里只列出了 id 和小整数字段,需要其他字段的时候要加上字段名,后边的计算也同样处理,不再赘述。
A2、B2:生成“位存储转换表”,如果用 env() 函数放到全局变量,这里就可以省去计算。“位存储转换表”对性能优化的主要作用将在后面讲述。
A3、B3:打开原组表,对 id 做外存排序。
A4、B4:建立新组表和保存中间计算过程的序表。
A5:对 B3 游标做循环,每次从游标读取数据至 id 有变化。也就是说每次读取一个 id 的所有数据。第一次循环如下:

B5:清空 B4 的序表,准备用来保存当前 id 的按位存储结果。
B6:B4 中填入当前 id 和 f1 到 f500 的初始值 0,计算结果如下:

B7:根据 A5 中 flag 与 16 的商和余数,计算是第几个小整数的哪一位,再用余数 +1 查“位存储转换表”B2,得到小整数的值。例如:flag 的值 48,对应第 3 个小整数的第 16 位,position 是 3,余数是 0,value 是 32768(二进制 1000 0000 0000 0000)。
当前循环是在遍历原数据的游标,数据量很大。如果在循环中计算位存储的转换,计算的次数也会非常多。我们提前算好了“位存储转换表”,这里直接查表就可以了,对性能的提升会非常明显。
计算结果为:

B8:B7 的结果中合并相同的 position。例如标签 122 和 125 都在第八个小整数中,那么两个 value 就要做“按位或“,合并成一个。结果如下图:

B9:依据 B8,将序表 B4 中 position 对应的小整数值设置为 value。例如 position 为 3,就要将 f3 的值设置为 32768。执行后 B4 如下:

B10:B4 转换为游标,追加到 T.ctx 的最后。
A11:循环结束后关闭两个组表。
二、数据按位存储在组表 T.ctx 中,计算标签 2、18 和 25 都为“是”的数据。
完成了数据预处理后,对于这个需求,只要写很简单的代码就可以实现:
=file("T.ctx").open().cursor(id,…;and(f1,2)==2&&and(f2,258)==258&&…)
但是,实际应用中前端的传入参数一般都是 "2,18,25" 这样的标签号列表,所以还要写一些代码来转换成“按位于”的过滤条件。完整的示例如下:
A |
B |
|
1 |
="2,18,25" |
=A1.split(",").(int(~)) |
2 |
=to(16).(int(bits(pad@r("1","0",~)))) |
=A2.m(16,1:15) |
3 |
=B1.new(int(ceil(~/16)):position,B2(~%16+1):value) |
|
4 |
=A3.group(position;or(~.(value)):value) |
|
5 |
=A4.("and(f"/position/","/value/")=="/value) |
=A5.concat("&&")/"&&…" |
6 |
=file("T.ctx").open() |
=A6.cursor(id,…;${B5}) |
A1:多个标签号,实际应用中应为传入参数。
B1:标签号拆分为序列,并转换为整形。计算结果为:

A2:生成第 1、2、…、16 位为 1,其他位为 0 的 16 个小整数,结果如下:
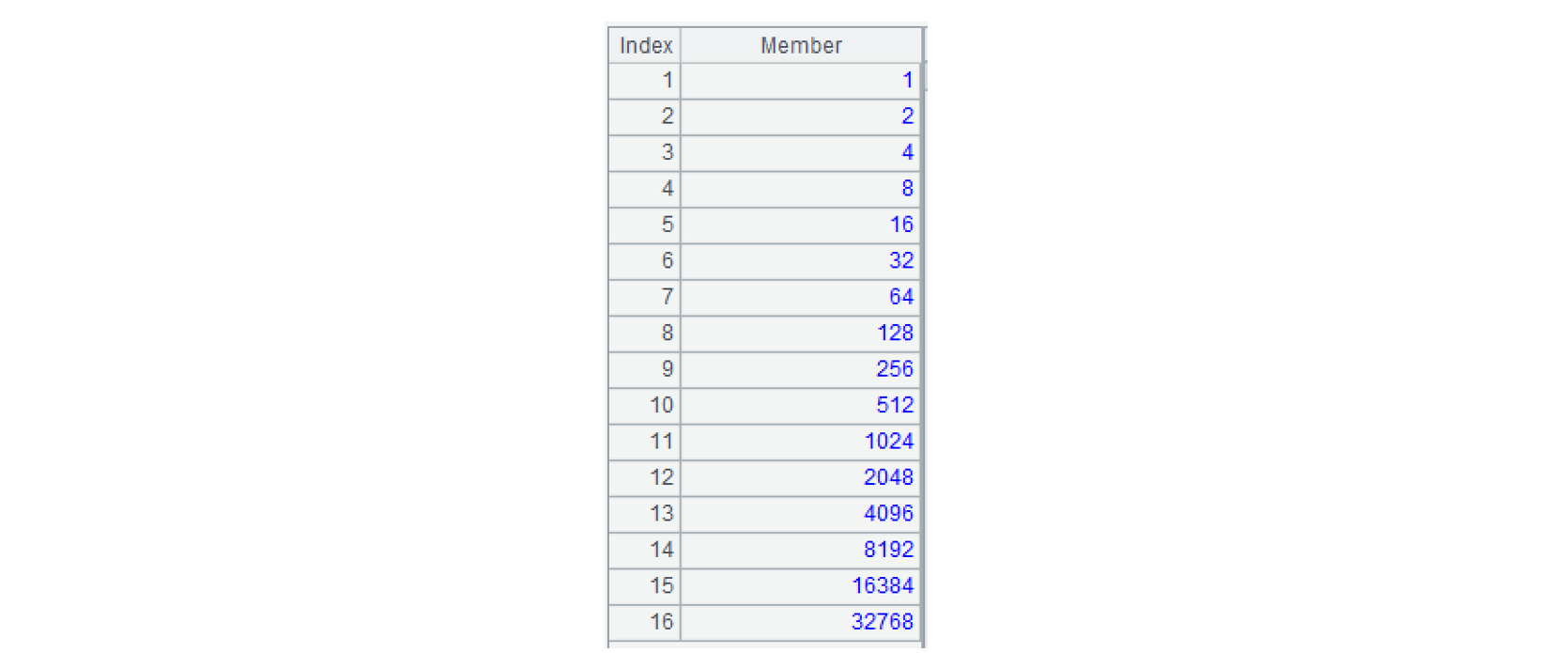
B2:将 A2 的成员调整位置如下:
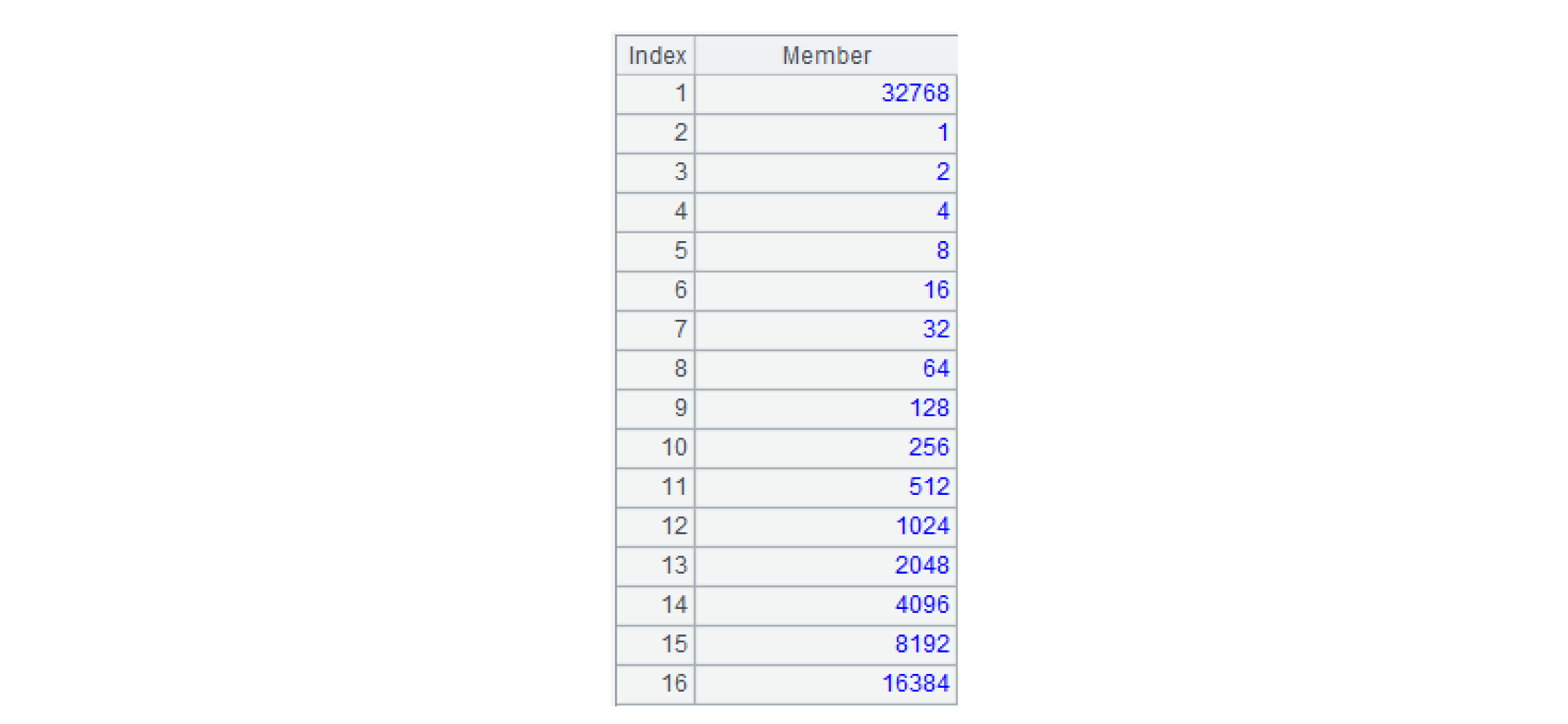
B2 的结果在标签计算、数据转换的代码中会反复用到,我们这里称之为“位存储转换表”。如果在系统初始化时预先算好,用 env() 函数放到全局变量中,这里就能直接使用,可以进一步提高性能。
B3:计算 B1 中的标签号,对应第几个小整数(position)以及在这个小整数中对应的值(value)。例如标签号 18 除以 16,商是 1 且余数不为零,那么标签 18 对应第 2 个小整数(position 为 2);又因为余数是 2,所以在“位存储转换表”B2 中查到第 3 个成员(余数 +1)就是标签 18 对应的小整数的值 2。B3 的计算结果为:

B4:B3 的结果中合并相同的 position。例如标签 18 和 25 都在第二个小整数中(position 为 2),18 的 value 是 2(二进制 10)、25 的 value 是 256(二进制 1 0000 0000),要对 2 和 25 做“按位或”运算,得到第二个小整数的最终值是 258(二进制 1 0000 0010)。结果如下图:

A5、B5:用 B4 的结果生成过滤条件序列,再用 && 连接成字符串。B5 中的“…”处可以写其他的过滤条件。结果为:
and(f1,2)==2&&and(f2,258)==258&&…
A6、B6:打开组表,建立带过滤条件的游标。后面继续写代码在游标的基础上完成统计。
统计过程中要对组表做遍历,读入的数据量是比较大的。我们之所以一直强调用小整数存储,是因为 SPL 是 Java 开发的,Java 产生对象很慢,SPL 将所有 16 位整数(0-65535)都事先产生了。如果发现读出来的整数在这个范围内,则不会新产生对象了,能减少很多运算量,还能减少内存的占用。
三、数据更新
如果修改数据量较少,而且不频繁,可以做组表 T.ctx 的更新,否则要重新计算生成组表。在更新之前,变动的数据也要转换成按位存储。假设转换后保存在 update.btx 中,结构和 T.ctx 相同。
A |
B |
|
1 |
=file("update.btx").import@b() |
|
2 |
=file("T.ctx").open() |
=A2.update(A1) |
A1:读入有变动的数据,变动的数据量不大,所以可以全部读入内存。
A2:打开组表。
B2:更新组表,数据写入补区。
定期清理补区的代码:
A |
B |
|
1 |
=file("T.ctx").open() |
|
2 |
if (day(now()))==1 |
=A1.reset() |
A1:打开组表。
A2:判断是否是每个月第一天。是则执行 B2。本例中每月清理一次,如果是其它时间周期可以用相应的判断方法。
B2:快速重置组表,将补区混入列区。


英文版